- Press Releases
Sustainability
Social Impact
Explore how Zillow is driving real progress toward a more affordable and accessible housing market.
- Investors
- Careers
13 min read
My Internship at Zillow Group AI Part 1: Attribute Recognition in Real Estate Listings
Zillow Group is the leading real estate and rental marketplace that serves the full lifecycle of owning and living in a home: buying, selling, renting, financing, remodeling and more. ZG has a database of more than 110 million real estate listings and has huge amount of multi-modal (listing images, text descriptions, geo-location and structured data) data. In a previous blog, ZG AI team shared how they use this data to build engaging product features and improve user experience.
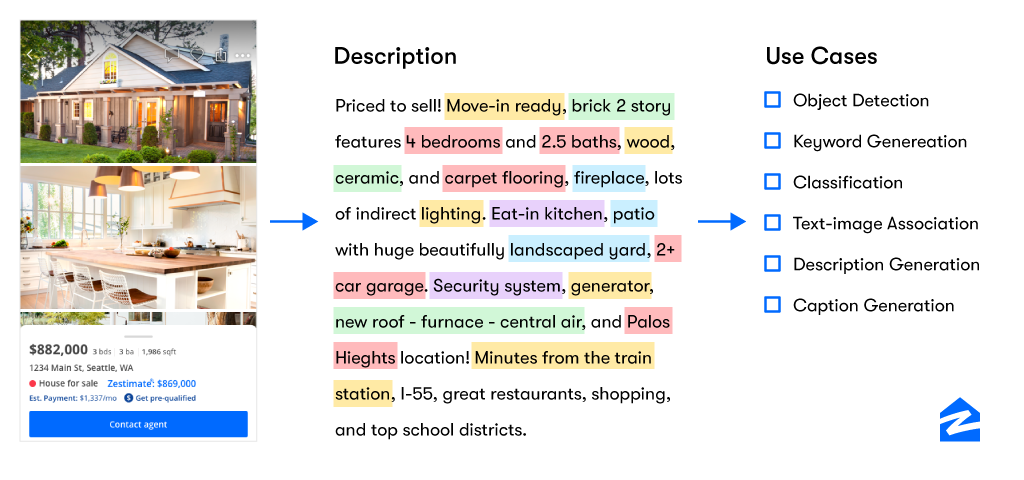 The rich multimodal database at Zillow provides unique opportunities to extract rich information and build systems for a variety of use cases.
The rich multimodal database at Zillow provides unique opportunities to extract rich information and build systems for a variety of use cases.
As my internship project, I built upon this work to identify real estate attributes in listing images using listing descriptions as weak-supervision. In this setting, attributes refer to various real estate concepts like an open kitchen, granite counters, hardwood floors, stainless steel appliances, etc. However, unlike traditional supervised approaches that require large amounts of well-annotated image-level data for training, we wanted to leverage weak labels generated programmatically from our large collection of listing descriptions. These labels are abundant and require minimum human supervision to create.
Generating weak labels from Listing Descriptions
Each real estate listing at ZG comes with a rich text description and a set of images. In order to generate associations between an image and the keywords in the description, the AI team has developed an algorithm that exploits semantic relations between scene type and keywords to weakly associate keywords in descriptions to the individual images.
At the high level it uses a visual model (CNN) to classify scenes in images, a keyword extraction algorithm to identify keyphrases/attributes from descriptions, a Word2Vec skipgram text model to learn semantic relationships between keywords and scene types, and a keyword-image association procedure to associate extracted keyphrases to images of semantically related scene type. For eg. “granite countertops” will be associated with images tagged as scene type Kitchen. We are able to run this process across millions of active listings to generate rich real estate collections for our users.
The above generation process provides us with millions of labels but makes certain assumptions around the completeness of the descriptions and images as well as the precision of the underlying models. As such we term these labels as weak labels.
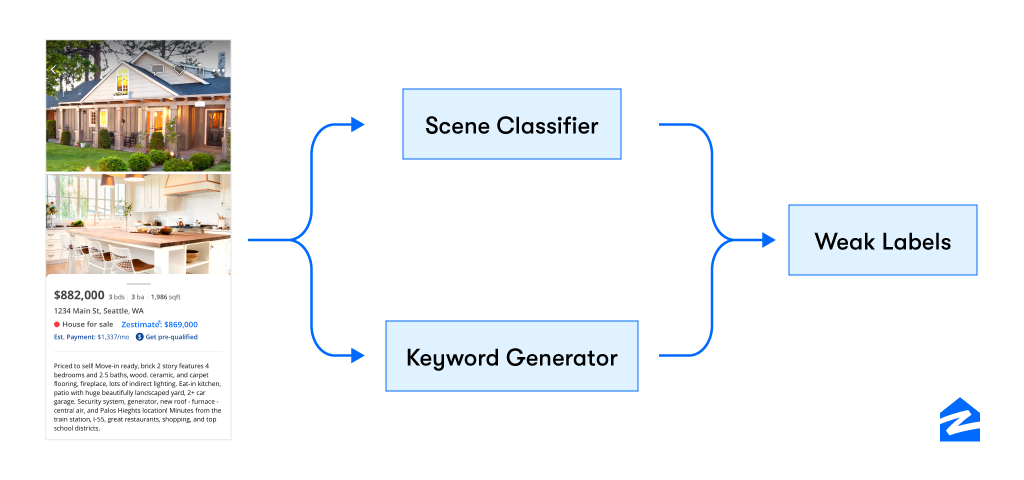 Weak-label data generation process. It is easy to create but lacks label precision.
Weak-label data generation process. It is easy to create but lacks label precision.
Our aim for this project was to explore if we can use these large collection of weak labels as supervision to train deep learning models that can detect attributes directly from images. This will both help to improve the accuracy of our downstream applications as well as provide us the ability to identify attributes when descriptions are either missing or incomplete.
From the onset we identified the following key challenges with the project:
- Label precision was unknown and labels were partial/incomplete
- Large number of attribute categories (around ~2400 categories)
- Some classes were over-lapping and subjective eg: countertop types, kitchen type, etc
- Attributes consisted of both entities (ex: stove, bed, couch) and concepts(floor-type, kitchen-type)
Phase 1: Validating our hypothesis
In order to better understand the data and decide on a possible course of action, we narrowed our scope to only kitchen scenes and 27 attributes. The attributes consisted of both entities and concepts covering a wide variety of features associated with kitchens such as appliances, kitchen type, floor type, cabinet types, countertop type, and lighting.
Understanding the data:
The immediate next step was to understand the label quality and assess the difficulty of classification. This understanding was crucial for the selection of loss function and model architecture. However, the only way to achieve this was through manual sampling and labeling of items across all 27 attributes. Sampling of the data revealed the following:
- The precision of the labels for a few attributes was as low as 10%. Also, the mean precision across all attributes was at ~60%.
- The images were not focused and all attributes were not clearly visible although present in the description. (Partial occlusion)
There were a few subjective attributes and were difficult to identify (especially floor, countertop, and cabinet types)
 A few examples from weakly labeled dataset. We can see the issues of low precision, incomplete labels and partial occlusion.
A few examples from weakly labeled dataset. We can see the issues of low precision, incomplete labels and partial occlusion.
Based on the label quality analysis, we decided to further reduce the attribute space and restrict it to 16 attributes with slightly better label precision. We also created a validation set of 300 images by manual labeling to evaluate model performance.
Model selection and loss function:
For computer vision tasks, the most efficient and quick way of building models is through transfer learning. We decided to start with the ResNet50 model trained on the places365 dataset open-sourced by MIT as the base model. The model was trained on 365 scene categories and Zillow had been using a fine-tuned version of this model for scene classification tasks. We used Binary cross-entropy loss with positive weights as we were dealing with a multi-label classification problem with class imbalance and mean average precision(micro) aka mAP as the evaluation metric.
Evaluating the results
The model was fine-tuned with at least 4000 high-quality images (filtered using image quality score) per attribute and we observed a mAP of around 0.47. Although the model predictions on the test set looked fine for a baseline model trained on a 60% precise dataset, we were concerned about model learning the label correlation instead of image features. One way to ascertain this was by looking at the Class activation maps (CAM) and understanding the model behavior. CAM is a simple technique to get the discriminative image regions used by CNN to identify a specific class in the image. In other words, CAM lets us see which regions in the image are relevant to a class. The CAM for the attributes suggested that the model was learning mostly the co-occurrence as discriminative image regions of all the classes were almost the same.
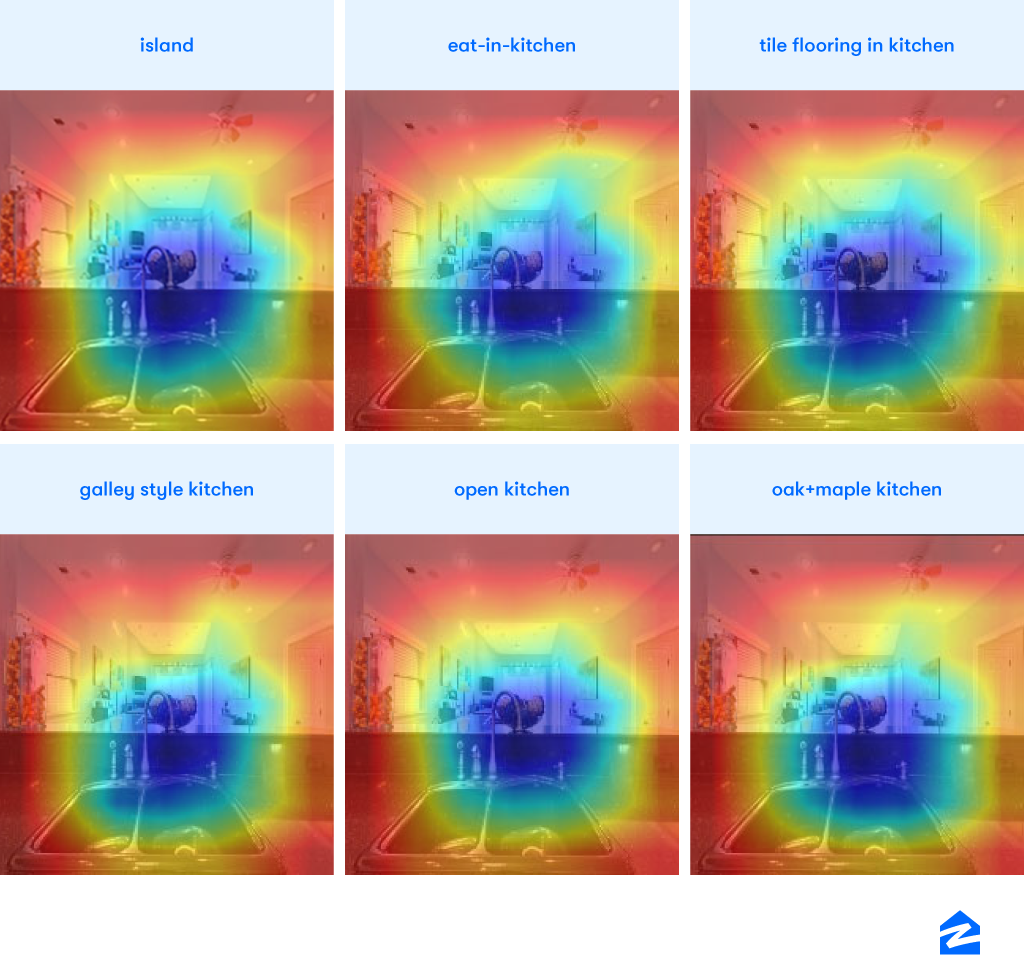 CAM of ResNet50 model pre-trained on the places365 dataset and fine-tuned on listing images. Blue shows the area of interest and it looks the same for all the classes. (The color scale is inverse of the normal representations.)
CAM of ResNet50 model pre-trained on the places365 dataset and fine-tuned on listing images. Blue shows the area of interest and it looks the same for all the classes. (The color scale is inverse of the normal representations.)
How can we help the model learn better?
Due to the weakly labeled dataset, we were not sure what was the best way to move forward. We decided to use the learning from the paper Deep Learning is Robust to Massive Label Noise that suggests larger batch sizes, appropriate learning rates and threshold levels of correct examples can help with noisy data. We also modified our model architecture based on the paper Is object localization for free? — Weakly-supervised learning with convolutional neural networks. This paper proposes a fully convoluted architecture that helps with localization and classification. This also has the added advantage of easy model interpretability with the help of CAMs.
Experimenting with a new model architecture
Although we formulated the problem as a multi-label classification task, due to the nature of the use case, it resembled object detection and localization tasks. The model needs to focus on different parts of the image to clearly assign attributes. Inspired by the paper, we decided to use 7 layers of a ResNet model and added 2 fully convolutional layers instead of dense layers to the architecture. The architecture had K(= no. of attributes) filters and a global max pooling at the last layer so that we end up with a Bx1x1xK tensor, where B is the batch size. This tensor acts as the final prediction for each class post applying sigmoid. The suggested architecture had the following advantages:
- Since we had full CNN layers and global Max pooling, the model could work with any input image sizes.
- The CNN layers helped in creating grids around the image (Similar to YOLO in object detection) and each grid had its own area of interest.
- Max pooling helped in localization and helped us get better CAMs for interpretability.
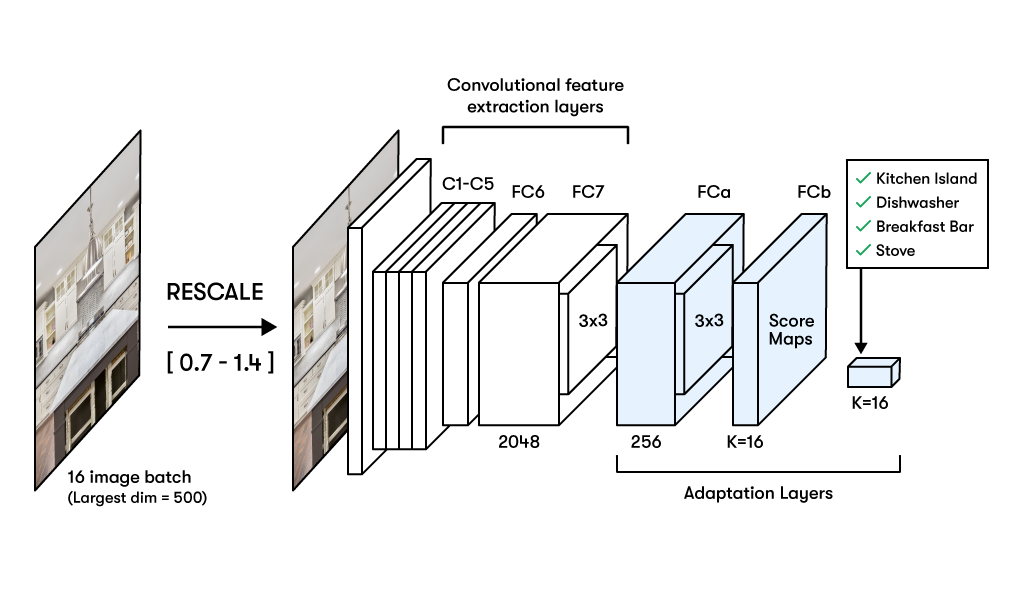 Modified network architecture for weakly supervised training based on this paper.
Modified network architecture for weakly supervised training based on this paper.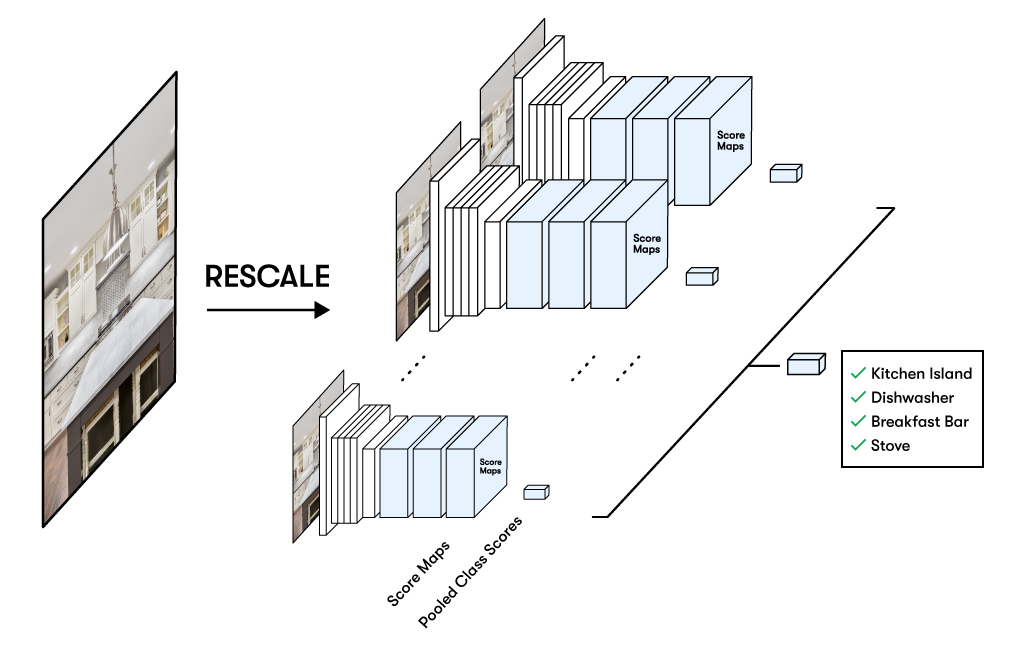 Test time augmentation incorporating multi-scale image classification
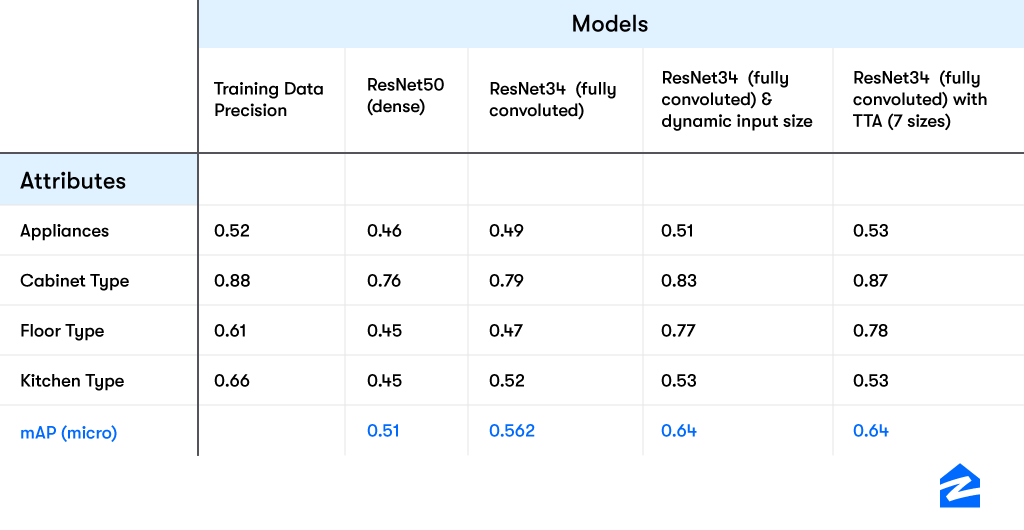
Test time augmentation incorporating multi-scale image classificationWe tried various base architectures ResNet34 (trained on imagenet), ResNet50 (trained on places365), different image sizes and test time augmentation(TTA) to improve model performance. For TTA, we resized the given images to 7 different scales and averaged the model prediction to account for smaller attribute size in the images. As shown in the result table, new architecture performed much better compared to a dense layer and was able to learn even with weakly label dataset. We also observe that, dynamic resizing of images while training and TTA further improved model performance as it became easier for the model to identify even smaller objects.
 The CAM also looks much better compared to previous architecture. We can clearly see various discriminative regions matching to the location of the attribute.
The CAM also looks much better compared to previous architecture. We can clearly see various discriminative regions matching to the location of the attribute. Class activation map with fully convolutional architecture using ResNet34 base model trained on imagenet dataset. The activation maps looks much better and shows focused regions(blue) for each class. (The color scale is inverse of the normal representations.)
Class activation map with fully convolutional architecture using ResNet34 base model trained on imagenet dataset. The activation maps looks much better and shows focused regions(blue) for each class. (The color scale is inverse of the normal representations.)Phase 2: Expansion
After the encouraging results of phase 1, we decided to expand to more categories and check the generalizability of our models and techniques. We also wanted to validate the model pipeline and find ways to improve model performance.
The major bottleneck in expanding to a larger number of categories was the requirement of a validation dataset. Since hand labeling the dataset was the only way to get validation data, we wanted to make use of available open source datasets to reduce this overhead. We explored COCO and ADE20K data set and listed common attribute with the Zillow attribute list. ADE20K had the maximum overlap between the attributes, but the data set size was really small. COCO had only a few categories in common but had a large amount of data. We created a 25K dataset for benchmarking and validation.
We trained our model pipeline on the open-source dataset to evaluate the model performance. With 30 attributes, the model had an mAP(micro) of 0.734 which was reassuring. We also observed that for attributes with less than 500 images, the model performance was poor. We also wanted to create a baseline for weakly labeled data by training on our weakly labeled data and validating against the open source dataset. To our surprise, the model performance was unexpectedly bad and revealed the next set of issues:
- Different classification criterion
The labelling criterion for the attributes was different across Zillow and open source dataset for a few classes. In order to have a consistent evaluation dataset and metric, we labeled 700 images to act as validation dataset.
- A higher number of Classes and noisy data
With the increase in the number of attribute classes, the model localization deteriorated. In order to tackle this problem we decided to try different loss functions, training techniques, and architectures. During our initial experimentation, we had found a fully connected layer network performed better than a dense layer network. However, this conclusion was based on a network that had ResNet50 pre-trained on places365 dataset. In order to isolate both components, we tried using dense layer networks with ResNet34 trained on imagenet data. To our surprise, the architecture performed better compared to a fully connected network trained on the same dataset. This may be due to the nature of the task of scene classification which needs the model to focus on the whole image instead of certain parts of the image. However, the CAM’s still did not look inspiring as shown below:
 CAM activation of a ResNet34 model with dense layers trained on imagenet dataset.
CAM activation of a ResNet34 model with dense layers trained on imagenet dataset. GradCAM activation of a ResNet34 model with dense layers trained on imagenet dataset.(The color scale is inverse of the normal representations.)
GradCAM activation of a ResNet34 model with dense layers trained on imagenet dataset.(The color scale is inverse of the normal representations.)In order to solve this mystery, we tried GradCAM and it produced much better results. GradCAM uses the class-specific gradient information flowing into the final convolutional layer of a CNN to produce a coarse localization map of the important regions in the image and is a strict generalization of the CAM. We believe this is the reason for a better visualization and it also assured that the model performance is not due to co-occurrence capture but due to image attributes.
Our research also revealed a variety of interesting approaches to tackle the problem of noisy and an incompletely labeled dataset. Here are a few approaches which we explored but only on the surface:
- Loss function: A large number of papers suggest ways to learn a transition metric between noisy labels and true labels. Incorporating these methods helps model learn true representation. Some papers also suggest using a ranking loss instead of BCE type loss to account for multiple labels and uncertainty with the labels. There are also a few papers that suggest using a bootstrapping method, where we assign some confidence to our labeled data and help model contradict the label provided as the model trains and gains confidence. We tried LSEP loss which is a ranking loss but found BCE loss to be slightly better.
- Training method: Many papers suggest ways to distill the noisy labels and provide better labels to the model to train on through some selection method. Co-teaching is one such method where we train 2 networks in parallel and one network selects training examples for the other based on a high probability of predicted labels. We tried a modified version of this training methodology for Zillow’s dataset however the results were not encouraging on the first go.
- Domain adaptation: The data distribution was very different across open source and listing images (how the images were captured). Since, the data-sets come from different distributions, domain adaptation by fine-tuning on relevant data could be a potential solution. We ran multiple experiments across different model training configurations to find out the most efficient way to train and fine-tune models based on available datasets. To start, we trained a model on the clean hand-labeled dataset (700 images) and derived the model benchmark of 0.753 mAP. Out of the various configurations tried, we observed that the model trained first on weakly labeled data, fine-tuned on open-source data, and lastly fine-tuned on 270 clean data labels achieved mAP of 0.750. In the absence of open-source data, we were still able to achieve a mAP of 0.719. This was a great insight and helps streamline future data collection.
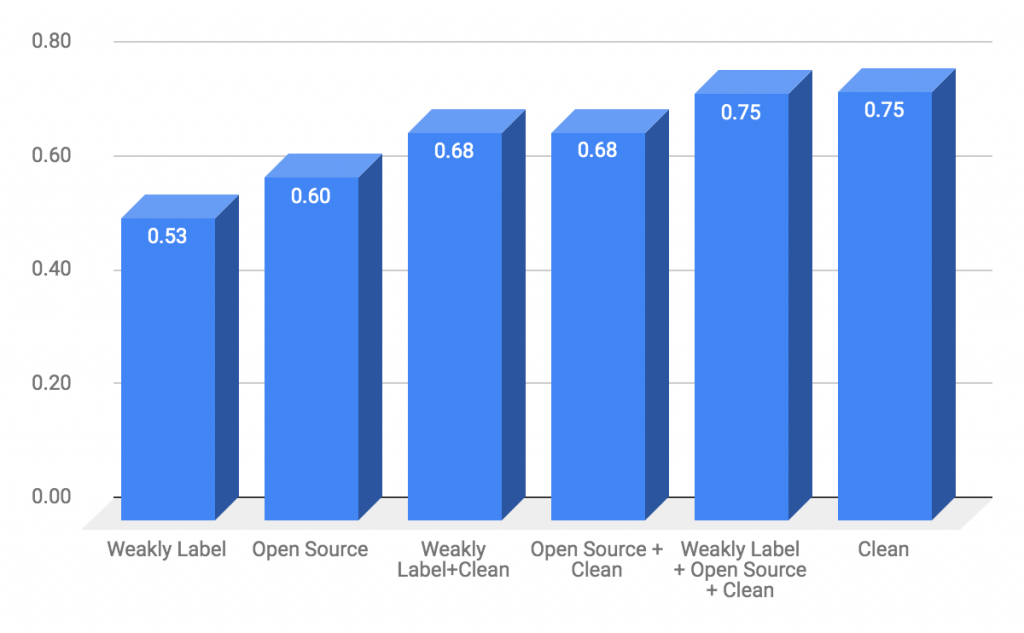 Comparison of model performance across different domain adaptation scheme. Depicts models ability to learn with weakly label and minimum clean data
Comparison of model performance across different domain adaptation scheme. Depicts models ability to learn with weakly label and minimum clean dataLooking Forward
This project showed us the potential of weakly labeled data in successfully training deep learning models and have paved the way for a lot of future projects. Personally, this project was a great learning experience for me and helped me learn the end-to-end project cycle of training, building and deploying deep learning models. I deployed the best performing model as a RESTful API service. Check out this previous post to learn more about deploying Deep learning models at Zillow. It also exposed me to the issues of translating business problems to machine learning problems and gathering relevant data. I was able to witness the learning power of deep neural networks even with noisy data and various ways of interpreting the end models.
This blog was part one of the project dealing with real estate images. Keep an eye out for part two where we will discuss how we use deep learning and NLP to improve keyword detection in listing descriptions and improve upon our weak-label generation process.
Related Articles



Sign up for Zillow news updates
Subscribe to receive daily emails for the latest Zillow news and announcements, product updates and more.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23111116;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M.67,84.17v-9.38L39.19,20.75v-1.12H1.34V4.67h62.64v9.38l-37.85,54.04v1.12h38.97v14.96H.67Z'/%3e%3cpath%20class='st0'%20d='M75.04,9.36c0-5.58,4.13-9.71,9.94-9.71s9.94,4.13,9.94,9.71-4.13,9.71-9.94,9.71-9.94-4.02-9.94-9.71ZM76.71,84.17V27h16.53v57.17h-16.53Z'/%3e%3cpath%20class='st0'%20d='M106.3,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M135.33,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M161.79,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM208.58,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M246.32,84.17l-17.2-57.17h16.86l11.61,40.64h1.12l10.16-40.64h16.53l10.94,40.98h1.12l11.39-40.98h16.41l-17.31,57.17h-21.55l-8.71-37.85h-1.12l-8.6,37.85h-21.66Z'/%3e%3cpath%20class='st0'%20d='M362.44,84.17V4.67h56.94v15.86h-38.3v17.53h33.5v14.51h-33.5v31.6h-18.65Z'/%3e%3cpath%20class='st0'%20d='M428.76,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.53Z'/%3e%3cpath%20class='st0'%20d='M471.64,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM518.43,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M545.11,84.17V27h16.52v8.04h1.12c4.24-6.48,9.71-9.71,16.64-9.71,12.95,0,21.55,10.05,21.55,23.78v35.06h-16.52v-32.72c0-7.03-4.02-11.95-10.72-11.95s-12.06,5.25-12.06,12.51v32.16h-16.52Z'/%3e%3cpath%20class='st0'%20d='M617.13,65.74v-26.69h-8.04v-12.06h8.49l3.24-18.09h12.95l-.11,18.09h13.06v12.06h-13.06v26.02c0,4.8,2.9,8.04,7.59,8.04,1.56,0,4.02-.33,5.92-.78v11.84c-3.24,1.12-7.93,1.79-11.17,1.79-11.5,0-18.87-8.15-18.87-20.21Z'/%3e%3cpath%20class='st0'%20d='M686.58,84.17V4.67h34.95c19.43,0,31.93,10.27,31.82,26.69,0,16.3-12.62,26.8-31.93,26.8h-16.52v26.02h-18.31ZM704.89,44.08h15.07c9.16,0,14.85-5.02,14.85-12.73s-5.81-12.62-14.85-12.62h-15.07v25.35Z'/%3e%3cpath%20class='st0'%20d='M757.71,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM804.49,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.19,6.7-15.19,16.19,6.25,16.3,15.19,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M831.17,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.52Z'/%3e%3cpath%20class='st0'%20d='M874.16,55.58c0-18.2,12.62-30.37,31.04-30.37,15.52,0,27.36,8.71,29.25,22.22l-15.41,2.01c-1.45-6.25-7.26-10.61-13.62-10.61-8.37,0-14.74,6.92-14.74,16.75s6.25,16.75,14.63,16.75c6.59,0,12.17-4.35,13.73-10.5l15.52,1.9c-2.12,13.51-14.07,22.22-29.37,22.22-18.2,0-31.04-12.28-31.04-30.37Z'/%3e%3cpath%20class='st0'%20d='M944.73,84.17V1.32h16.52v33.39h1.12c4.35-6.25,9.71-9.49,16.64-9.49,12.95,0,21.66,10.05,21.66,23.67v35.28h-16.52v-32.83c0-7.03-4.13-11.95-10.83-11.95s-12.06,5.25-12.06,12.62v32.16h-16.52Z'/%3e%3c/svg%3e)
