- Press Releases
Sustainability
Social Impact
Explore how Zillow is driving real progress toward a more affordable and accessible housing market.
- Investors
- Careers
10 min read
Image Processing at Zillow: Out with the Old and In with the AWS

The old saying goes that real estate is about Location, Location, Location. We'd like to submit a new saying: online real estate shopping is about Photos, Photos, Photos. Nothing delights Zillow's users more than big, beautiful, and bountiful photos on real estate listings. And nothing delights agents, sellers, and property managers more than the page views, leads, and traffic they get when their listings entice shoppers with great pictures!

As Zillow's popularity increased and agents started providing higher resolution photos on their listings, we found that our legacy imaging system could not keep up with the demand. We realized we needed to scale in a big way. Amazon Web Services (AWS) was the way to get us there.
This blog post walks you through our journey from our local data center legacy imaging system of the past to our AWS-powered imaging system for the present and future. We'll show you:
- How our legacy system was structured and what its limitations were
- How we built a scalable imaging download and processing system using AWS
- Some key lessons we learned through the process since we started out as AWS newbies
We also discuss a few options we're considering for making the new system even better, so please feel free to comment with your opinions and experiences!
So How Many Images Are We Talking About?
Zillow currently processes over 3 million new images each day. This includes listing images; profile images for users, agents, and other professionals; home project images through Zillow Digs; and other assorted image types. Some are manually uploaded and some come in bulk feeds to be downloaded. The rate of new images coming from these bulk feeds can be unpredictable and is typically batched into groups throughout the day rather than an even rate.
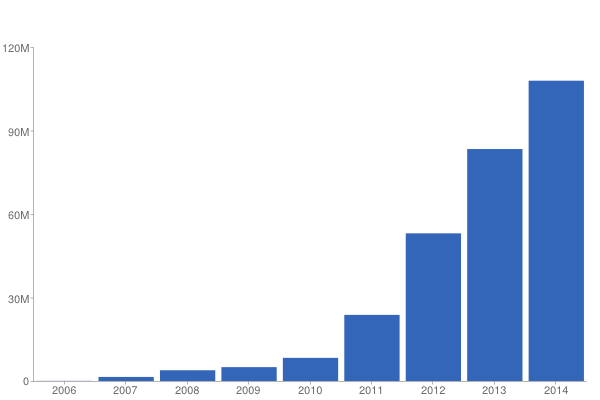
We have a lot of turnover in our images, so we don't end up persisting 1+ billion images (3 million * 365) each year . However, the chart below shows how many more images we have started to store as the years have passed. You can see why we needed to scale up our system!
The Legacy System
Our legacy system lived in our own hosted data centers (with the exception of a CDN for image serving). Images were downloaded out of one queue; stored on an NAS device in the 'pyramidal TIFF' format; and served to the CDN out of a local Squid service.
Its primary problems were:
- Not easily scalable for downloads, storage, or serving.
- Could not be easily extended with algorithms to improve image quality.
- Poor disaster recovery.
Here's a diagram of our downloading and processing pipeline:
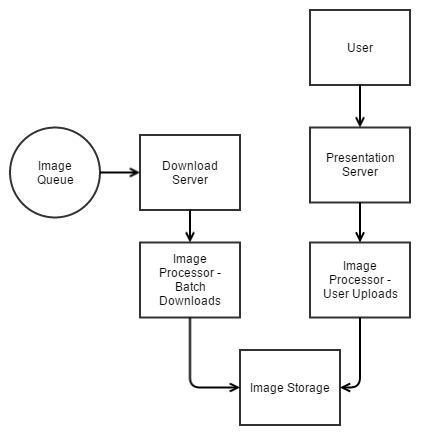
As you can see, manual uploads of images came in one path (on the right) and images provided from listings feeds were entered into another path with a queue (on the left). Because images from hundreds of feed sources were downloaded out of a single queue, we could not take advantage of the fact that some image sources allow much faster downloading with more concurrency than other sources. This caused head-of-line blocking problems (a slow or problematic image at the front of the queue would hold up other images) and the potential for overwhelming slower image sources with an image request rate that was too high (while at the same time not being able to take advantage of sources that could support that rate).
Images were stored on a large NAS device in the 'pyramidal TIFF' format, which is essentially a multi-layer image consisting of progressively smaller jpegs. The concept is that you can produce any image size efficiently by opening the file, seeking to the layer holding the next-largest size, and resampling it appropriately. This avoids the expense of scaling the original image (which is possibly much larger). Our scaling was done on the fly when an image serving request came for a particular size of image. Scaling on the fly can be expensive, so we relied heavily on caching via our CDN and local Squid service. If the cache was even partially blown, recovery would overwhelm the dynamic scaling layer and the NAS device for hours.
The tool that we used for processing the image to store it in pyramidal TIFF format was aging and not easily extensible. We could not easily put in image quality improvements like removing solid color borders from images or supporting CMYK/other colorspace images.
The New AWS System
Putting images 'in the cloud' may sound like a simple endeavor, but we actually had to build a substantial amount of infrastructure to end up with a system that solved the problems of our legacy imaging system.
Here's a summary of the problems we set out to solve and how we solved them:
- Disaster recovery
- Our images are now stored in Amazon's S3 service, which guarantees many "9s" of durability and availability.
- Our image downloading and processing system runs in AWS using Elastic Beanstalk (ELB), which takes advantage of multiple "availability zones" for disaster recovery.
- Not easily scalable for downloads, storage, or serving
- Image downloads from each feed source are now independent - we can take advantage of sources that support high bandwidth and concurrency while throttling back for sources that cannot.
- Image downloading and processing scales to handle varying levels of incoming images throughout the day.
- S3 provides unlimited storage without having to order and install more servers or drives.
- Amazon CloudFront and S3 take care of our serving scalability needs.
- Could not be easily extended with algorithms to improve image quality
- Our image processor is now built on the Python Imaging Library (PIL). We have found this easy to extend.
Here's a diagram of the system that we built. The individual services are described below.
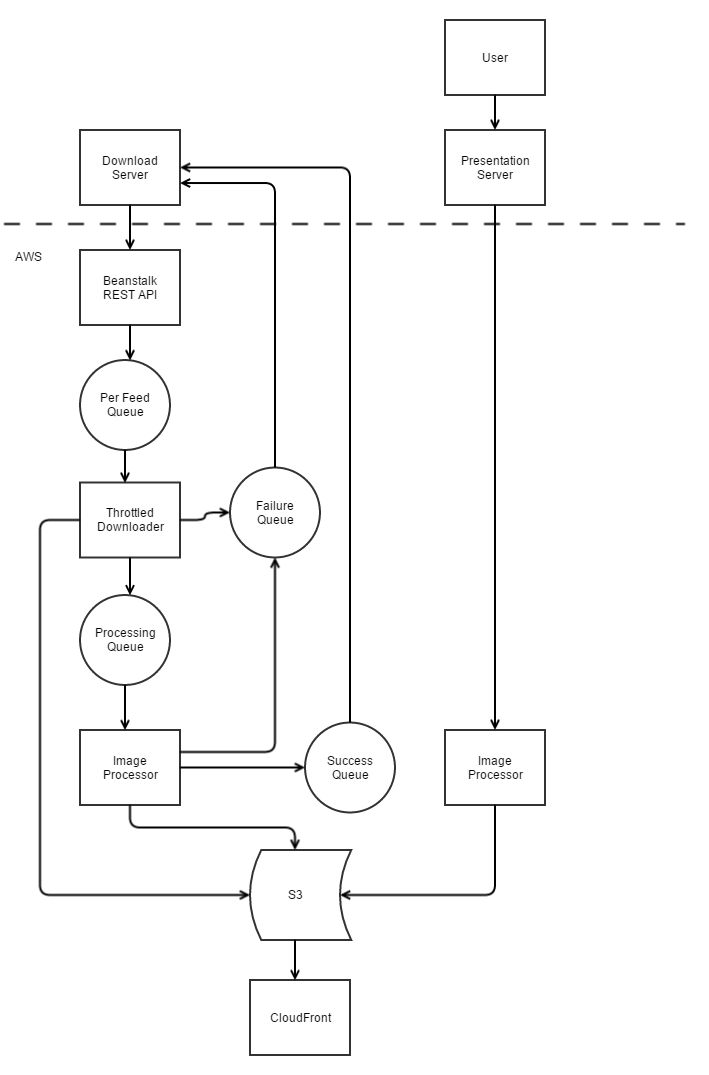
Download Server (DLS): This is a service in Zillow's data center that manages image download requests coming from listing feeds. This includes ensuring that our database of images (which also lives in our data center) is kept up-to-date with the results of the cloud image processing.
Beanstalk Rest API: This service is just a front-end in the cloud for the DLS. It takes an image download request and puts it in one of the per-feed SQS queues. We have one SQS queue per feed solve the head-of-line blocking problem.
Throttled Downloader: The throttled downloader does the actual downloading of the image. It controls the rate and concurrency at which we download images for each feed source, allowing us to take advantage of providers that support fast downloading and to not deluge providers that don't. If the image download succeeds, we write the original image into S3 to be used in the image processing step. If the image download fails, a message is queued into the failure queue to be processed by the DLS.
Image Processor: This is a beanstalk worker role deployment. It runs the Python Imaging Library with some custom code. We take the original images stored in S3 and process them through various image quality methods (such as removing solid color borders). We also generate a standard set of sizes for each image that we know we need on the site (for example: a large one for our full page photo gallery, a smaller one for our emails, etc.) and store those to S3. If the image conversion succeeds, a message is put into the Success SQS Queue. Otherwise it is put into the failure queue.
CDN: Images are served out of S3 and cached in the CloudFront CDN. We serve up to 15,000 images per second and have never had performance issues with this model.
Lessons Learned
In the process of moving over to a new imaging system and AWS, we learned some important lessons.
Measure! The initial versions of our apps did not expose enough metrics. Due to this, we could not figure out which component of the pipeline was contributing to image processing delays. We ended up having to invest a lot of time after the system was already live adding CloudWatch metrics to track latencies. Once we did this, we had a clearer picture of the causes and could take action to eliminate them. In some cases, we could use the metric thresholds to drive autoscaling activities, so no human intervention was required.
Use CloudWatch Alerts. We found cases where Beanstalk containers did not behave as expected. For example, in a worker role, sometimes the system would scale down, but leave a bad instance (one that failed early in the initialization phase) in service. The bad instance would never pick up any work. And since we used CPU thresholds to add/remove machines, the autoscaling group would never do its job because the CPU of the bad instance was always at zero. We could detect this by adding alerts on queue levels. We also added alerts to other parts of the pipeline which allowed us to closely monitor the SLA of the various components.
Future Work
We are continuously tuning the new system for best performance, lowest cost, and most functionality. Here are a few areas we want to tackle in the future:
- Given the bursty nature of how images come into our system, the autoscaling configuration of the Image Processor is tricky. Spin up too many instances and you'll waste money, but too few and you'll add delay to the images making it to the site. Right now we are scaling on the latency between the time an image is enqueued to when it is finished processing. In the future, we may switch to custom scaling based on queue length. We may also investigate solutions to preemptively scale up some Image Processors before times that we know large batches of images tend to come in.
- In the new system, we gave up the flexibility of our pyramidal TIFF scaling and went to pre-rendering all image sizes. If the design of the site changes and we need a new image size, it is a real pain to re-process hundreds of millions of images to support that new size. We would like to switch to a just-in-time model where scaling doesn't happen until the first request. Perhaps we could use GPU instances for scaling or the newly launched event-driven AWS Lambda?
- PIL is dead; long live Pillow. PIL is deprecated and Pillow is the project being actively developed. We need to switch over to take advantage of the open source community's continuing contributions to image processing.
- Improving image quality. We try to take the images we're given and make them the best version of themselves. We've experimented with sharpening and do solid color border removal, but there are many other areas we could investigate for the future.
Conclusion
Sometimes an old system is worth maintaining, but other times you're better off throwing it away and starting from scratch. Given the importance of images to the Zillow user experience, we wanted a system that could grow to match our needs. By moving to AWS (S3, CloudFront, Elastic Beanstalk, and SQS) we no longer have to worry about forklift upgrades, cache flushes, or capacity. The move was not without its challenges (in large part because we had very little prior AWS experience), but we are happy with the new system and eager to continue improving it.
Related Articles




Sign up for Zillow news updates
Subscribe to receive daily emails for the latest Zillow news and announcements, product updates and more.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23111116;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M.67,84.17v-9.38L39.19,20.75v-1.12H1.34V4.67h62.64v9.38l-37.85,54.04v1.12h38.97v14.96H.67Z'/%3e%3cpath%20class='st0'%20d='M75.04,9.36c0-5.58,4.13-9.71,9.94-9.71s9.94,4.13,9.94,9.71-4.13,9.71-9.94,9.71-9.94-4.02-9.94-9.71ZM76.71,84.17V27h16.53v57.17h-16.53Z'/%3e%3cpath%20class='st0'%20d='M106.3,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M135.33,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M161.79,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM208.58,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M246.32,84.17l-17.2-57.17h16.86l11.61,40.64h1.12l10.16-40.64h16.53l10.94,40.98h1.12l11.39-40.98h16.41l-17.31,57.17h-21.55l-8.71-37.85h-1.12l-8.6,37.85h-21.66Z'/%3e%3cpath%20class='st0'%20d='M362.44,84.17V4.67h56.94v15.86h-38.3v17.53h33.5v14.51h-33.5v31.6h-18.65Z'/%3e%3cpath%20class='st0'%20d='M428.76,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.53Z'/%3e%3cpath%20class='st0'%20d='M471.64,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM518.43,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M545.11,84.17V27h16.52v8.04h1.12c4.24-6.48,9.71-9.71,16.64-9.71,12.95,0,21.55,10.05,21.55,23.78v35.06h-16.52v-32.72c0-7.03-4.02-11.95-10.72-11.95s-12.06,5.25-12.06,12.51v32.16h-16.52Z'/%3e%3cpath%20class='st0'%20d='M617.13,65.74v-26.69h-8.04v-12.06h8.49l3.24-18.09h12.95l-.11,18.09h13.06v12.06h-13.06v26.02c0,4.8,2.9,8.04,7.59,8.04,1.56,0,4.02-.33,5.92-.78v11.84c-3.24,1.12-7.93,1.79-11.17,1.79-11.5,0-18.87-8.15-18.87-20.21Z'/%3e%3cpath%20class='st0'%20d='M686.58,84.17V4.67h34.95c19.43,0,31.93,10.27,31.82,26.69,0,16.3-12.62,26.8-31.93,26.8h-16.52v26.02h-18.31ZM704.89,44.08h15.07c9.16,0,14.85-5.02,14.85-12.73s-5.81-12.62-14.85-12.62h-15.07v25.35Z'/%3e%3cpath%20class='st0'%20d='M757.71,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM804.49,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.19,6.7-15.19,16.19,6.25,16.3,15.19,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M831.17,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.52Z'/%3e%3cpath%20class='st0'%20d='M874.16,55.58c0-18.2,12.62-30.37,31.04-30.37,15.52,0,27.36,8.71,29.25,22.22l-15.41,2.01c-1.45-6.25-7.26-10.61-13.62-10.61-8.37,0-14.74,6.92-14.74,16.75s6.25,16.75,14.63,16.75c6.59,0,12.17-4.35,13.73-10.5l15.52,1.9c-2.12,13.51-14.07,22.22-29.37,22.22-18.2,0-31.04-12.28-31.04-30.37Z'/%3e%3cpath%20class='st0'%20d='M944.73,84.17V1.32h16.52v33.39h1.12c4.35-6.25,9.71-9.49,16.64-9.49,12.95,0,21.66,10.05,21.66,23.67v35.28h-16.52v-32.83c0-7.03-4.13-11.95-10.83-11.95s-12.06,5.25-12.06,12.62v32.16h-16.52Z'/%3e%3c/svg%3e)
