- Press Releases
Sustainability
Social Impact
Explore how Zillow is driving real progress toward a more affordable and accessible housing market.
- Investors
- Careers
16 min read
Leveraging Knowledge Graphs in Real Estate Search

Why Knowledge Graphs?
In the age of the internet, there is no dearth of information on any topic we want. But organizing information in a structured manner and making it consumable is still a challenge. Knowledge Graphs (KG) are one such tool for storing information in a more structured manner, capturing the relationships across data points, and making it easy to consume — both for humans and machines.
We experience the benefits of a KG during our internet searches, when structured information gathered from a variety of sources is summarized by the search engines. For example, a keyword search for the word “New York” returns a variety of results related to land area, weather, demographics, and news reports, all of which are linked and structured under the same page easily. The results are similar even when you look for 'NYC'. This is a nice example of how a KG can be used to visually represent the relationship between a query and indexed data from different sources, making the data easily available for a variety of tasks and consistent for related searches.
At Zillow, in addition to an abundance of user engagement data, we work with large amounts of home-related data in the form of listing images, listing descriptions, home attributes, neighborhood information, points of interest (POI) datasets, etc. We also work with several in-domain knowledge banks, such as curated blogs, real estate attribute definitions, and annotation guides that are relevant to the business. In order to create seamless experiences for our users, and help them find their next home, it’s critical that the business consume and structure this data correctly. Figure 1 is an illustrative knowledge graph representing the relationships among a small subset of possible home attributes
In summary, a knowledge graph can help Zillow:
- Understand and enrich structured and unstructured data from a variety of sources and normalize them to the same vocabulary
- Represent relevant relationships, dependencies, and summaries for a variety of use cases
- Create seamless experiences for our users by better understanding their needs and creating relevant product features
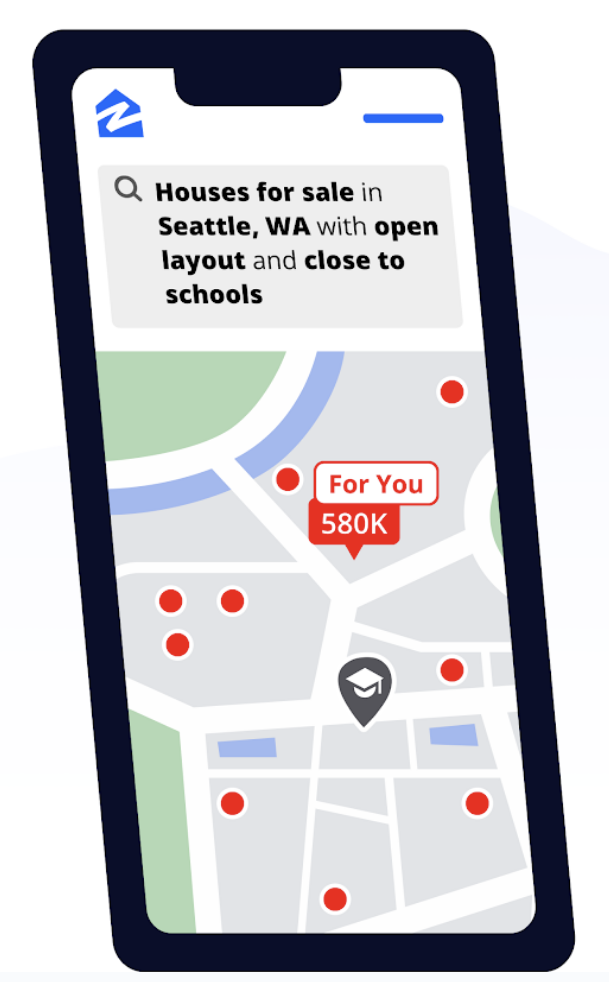
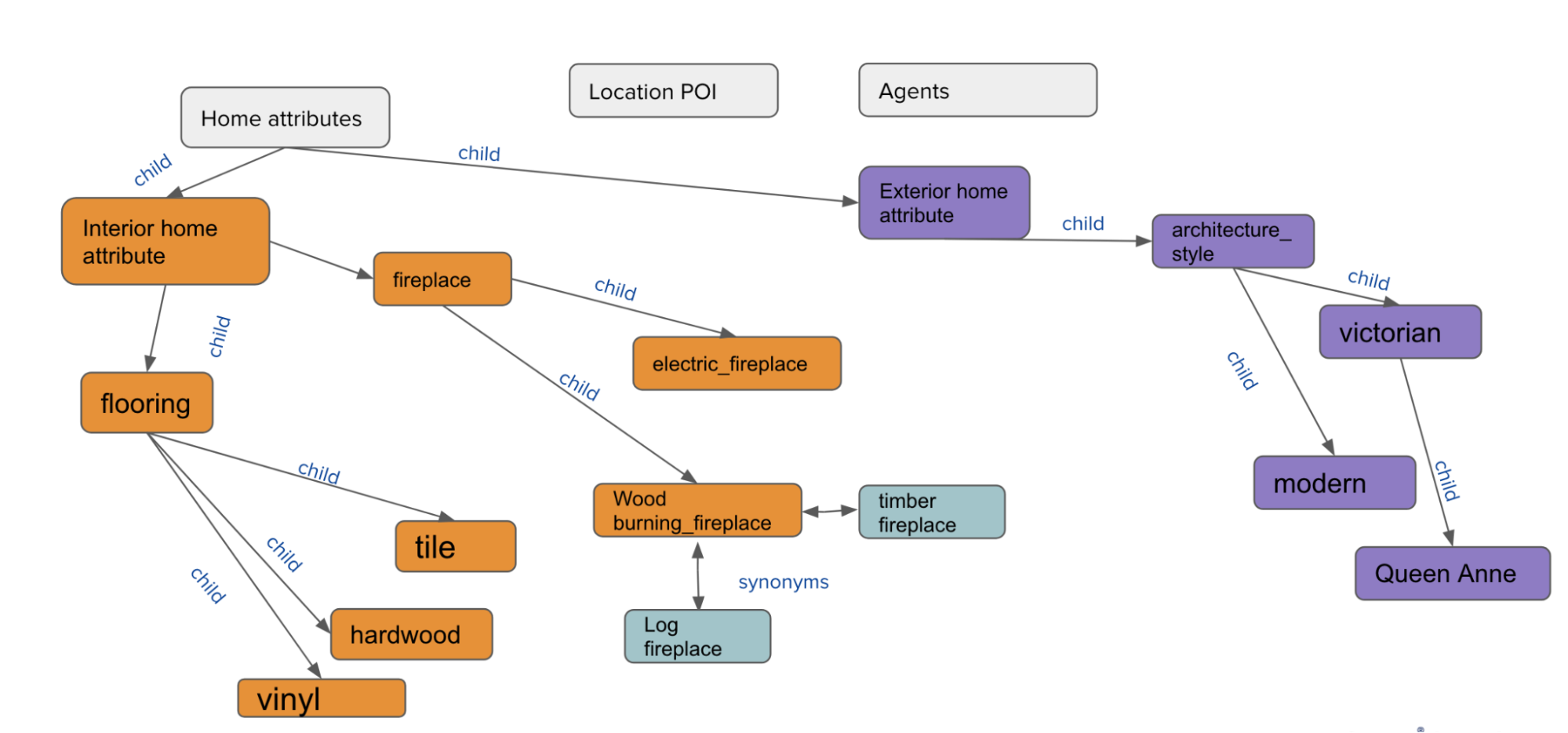 Figure 1. A small sample of a real estate KG consisting of concepts for different home features and connected to each other through Parent / Child (i.e., Hypernym / Hyponym) and Synonym relationships
Figure 1. A small sample of a real estate KG consisting of concepts for different home features and connected to each other through Parent / Child (i.e., Hypernym / Hyponym) and Synonym relationships
Key Applications and User Experiences for a Real Estate Knowledge Graph
The diagram in Figure 2 shows the functional view of a KG enriched by data from a variety of sources and supporting various use cases and product experiences. The Content Understanding Platform is Zillow’s internal platform built to tap into a variety of structured and unstructured data sources available to extract information and store it in a KG, with the help of Human in the Loop (HITL) validation (i.e., a human validating correcting model prediction). The platform is crucial in aggregating and normalizing information and acts as a bridge for KG creation and updates. The platform hosts a variety of image and text models and can make near real-time predictions for supported use cases. The data present in the KG powers a variety of applications, as shown below. We will now briefly touch upon how the KG helps to power these applications.
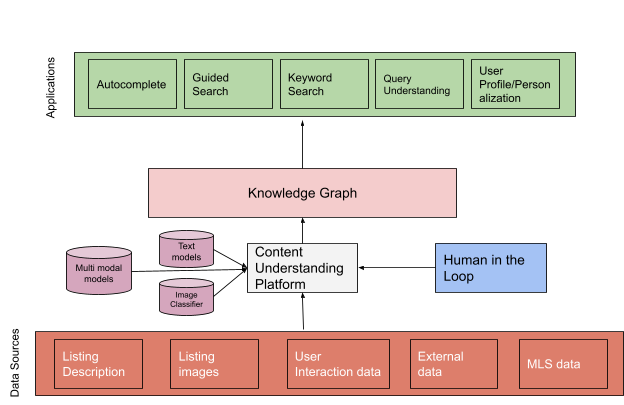 Figure 2. Applications of a Knowledge Graph (KG), together with data sources and models informing the KG.
Figure 2. Applications of a Knowledge Graph (KG), together with data sources and models informing the KG.
As shown below, we solve several important problems with the help of Knowledge Graphs:
Search Query Autocomplete: The KG provides a variety of concepts that can be presented to users in order to provide them with the right options as they search for homes. The KG offers suggestions related to various home concepts, such as amenities, specific architectures, or locations:
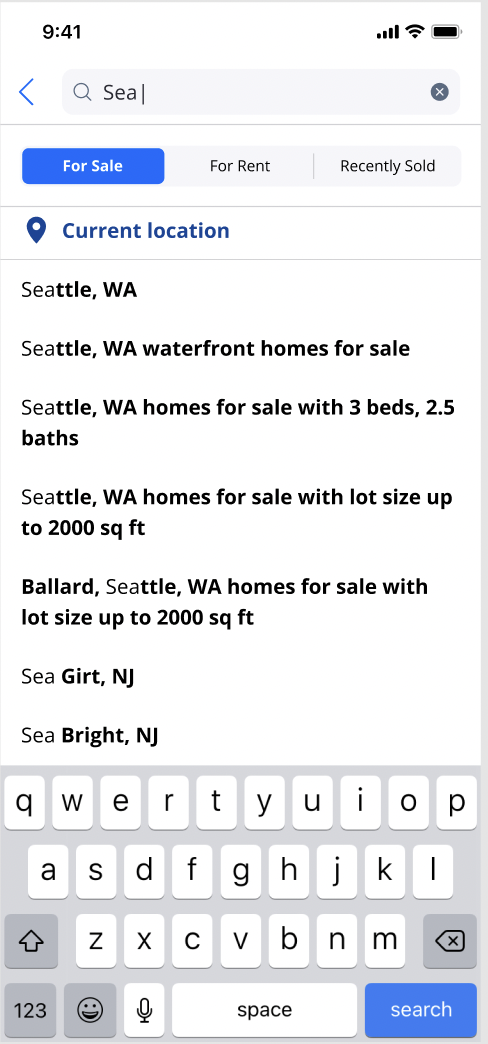 Search Query Autocomplete
Search Query Autocomplete
Keyword search: The KG plays a critical role in understanding user intent during keyword search, normalizing the query keywords based upon canonical concepts that can be used to generate consistent retrieval of relevant listings, which are indexed with the same canonical concepts. On the indexing side, the KG enables standard indexing of listings and normalizes the listings in terms of the canonical concepts. A keyword search that leverages a knowledge graph in this way is referred to as a concept search:
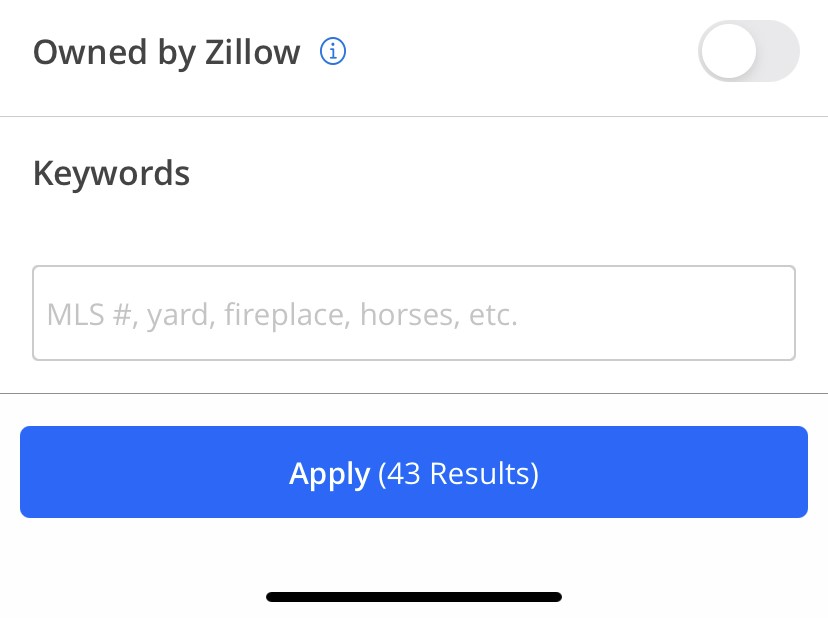 Keyword Search
Keyword Search
Query Understanding: The KG helps in understanding various components of a user’s natural language query and enables concept search for items they are looking for in the query:
Query Understanding
User Profile: A user profile in search and recommendation engines is a personalized dataset that captures a user's preferences, behavior, and attributes in order to tailor the experience and improve the relevance of search results. KG helps create new user profile features based on the user’s interaction with explicit searches or their interaction with listings that are relevant to specific KG nodes they might be interested in. A more accurate user profile helps improve personalized recommendations:
User Profile
Creating a Real Estate Knowledge Graph
At Zillow, we work with data sources that are both structured and unstructured. Here are some examples of each type:
- Structured data: Structured data includes data syndicated from MLSs or agents about a property and data sources about the location and region of the property. We also have structured data representing user interactions on the website, user searches, search sessions, and user/agent profiles.
- Unstructured data: Unstructured data comes in a variety of formats, such as text in a property listing description, images of the property, 3D/floor plans, documents, scanned images related to the property, etc.
Creating a KG typically includes the following steps:
Knowledge extraction: This process deals with aggregating information across different data sources and getting it ready for ingestion in the KG. In our case, these are some of the data sources listed above. We use both statistical models and the latest transformer-based model to extract this information. (Read this blog post and this blog post for more information on keyphrase extraction.) We will touch briefly on the processes through which we extract this data:
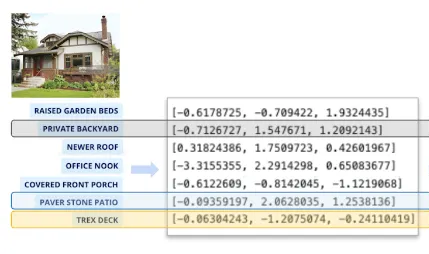
- Listing Description: We apply various NLP/information extraction techniques to extract interesting home-related information from the natural language descriptions of a home. For example, we extract all-important home attributes from the listing description as shown below:
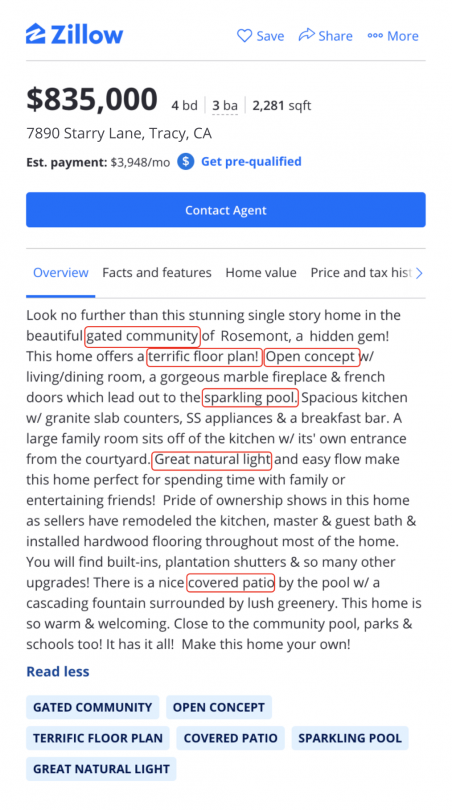
Figure 3: Example of extracting important home-related attributes from listing description.
- Images: Images related to listings are also a valuable source of information because we can extract a lot of information about a house and surrounding area that may or may not be clearly conveyed in the description. A typical extraction includes running image models to get scenes of the image, image quality, and image-attributes alignment. (Read this post and this post to get a general understanding of Zillow’s image processing techniques.)
 Figure 4: Example of identifying important home attributes from images
Figure 4: Example of identifying important home attributes from images
- Historical user queries: Zillow apps now also support natural language queries as a part of the search box experience(e.g. homes near me with 2 beds 2 baths and a fireplace). The Zillow website also supports keyword searches along with standard filters. We also review external data such as SEO queries coming from search engines like Google. These are great sources of information that can help us understand various user preferences, important real estate-related attributes, and different ways of expressing them. We extensively review these data sources and ingest them as a part of our Knowledge Graph.
- MLS Structured data: We capture a lot of structured data as part of agent input, and MLS feeds that are also stored in our data stores directly. Normally, this data has some structure and is easier to consume compared to unstructured data. We also capture user interaction on the website and natural language queries, which are another great source of information and learning.
Defining Ontology: The next step to creating a KG typically involves normalizing the various data sources to standard ontologies and storing them in a standard format for easy consumption and inference. In simple terms, Ontology refers to the standard entities, classes, and relationships defined in a KG, and guidelines on how to interact with them. Here are some sample node types and relation types defined for the real estate domain:
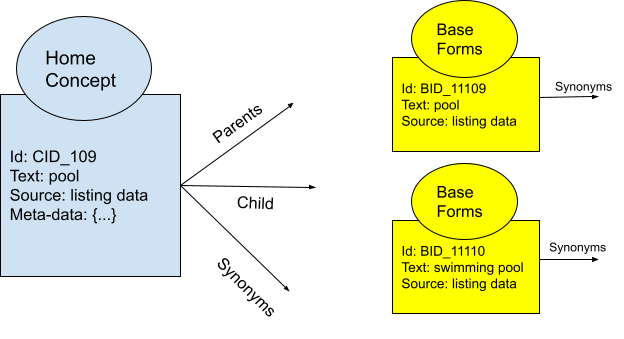 Figure 5: Example of Ontology nodes related to Home concept and Base form along with a set of relationship edges.
Figure 5: Example of Ontology nodes related to Home concept and Base form along with a set of relationship edges.
In Figure 5 we show two different node types to represent information:
- Home Concepts such as pool, architecture style, amenities, etc. present or related to a home. They can also be related to other home concepts through parent, child, or synonym relationships. Ex: Concept “pool” is synonymous with swimming pool and is a parent of the concept “heated pool”. Such metadata helps us better understand the various concepts and use them based on use cases.
- Base forms: These are any entities we observe across our datasets that we want to include in our knowledge graph. They are the basic block of home concepts and are aggregated to form a unique concept, on an as-needed basis.
The same design principles can be easily extended to other nodes such as agents, listing, etc.
Normalization and entity disambiguation: One critical aspect of ingesting data across various sources is the different forms in which the same entity can appear across the dataset. For example, the home concept “pool” can appear as “pool”, “swimming pool”, “swimmingpool”, or “has_pool: True” across various text data sources. However, we know that they all refer to the same standard concept of pool, and hence they need to be normalized and stored correctly in the Knowledge Graph. There are a variety of ways of handling this task, but we will talk about two broad classes of methods we use:
- Capturing static list of various forms: Under this method, we keep a list of the various observed forms for a concept as a synonym, or mapping list and use it to disambiguate a base form. This approach is fast and offers better understanding and quality control, but fails when addressing out-of-vocabulary words. The list must also be updated constantly to ensure that we have high coverage. At Zillow, we maintain such a Knowledge base as a part of the Knowledge graph for easy disambiguation and linking. This also acts as a data source for the next method discussed.
- ML models for disambiguation: In this method, we take the help of ML models to link a new base form to existing nodes in the knowledge graph. These could be Image models that take an image and link it to a concept class or text models or graph models that can identify synonyms/same concepts or other open-source KG for entity disambiguation and association to an existing node. At Zillow, we have trained BERT-based models to identify synonyms and help with entity disambiguation. We send a pair of phrases to the model and it classifies if the pair is a synonym or not. This model can not only help in online inference but also generate new candidates to expand the static list discussed above.
Connecting nodes in the Knowledge Graph: A major step in KG creation is connecting the nodes with relevant links to make the KG more informative and help find newer insights. A part of the linking process can be done with the help of:
- Structured data that lets us know the different links present across nodes. Ex: Listing data capturing dishwasher as one of the kitchen amenities and hence we can connect those two nodes for that listing. However, this data is normally incomplete and does not cover all the links we may be interested in.
- For such missing links, we need to mine for relationships in the data and connect them appropriately. These methods of finding missing links in KG are a function of both the node type and relation type. We can apply a variety of methods ranging from heuristic or rule-based to more complex methods needing language models or graph-based models.
We will quickly touch upon one such method we use for home concepts that are normally in text form. For one of the use-cases, we care mostly about synonyms, parent and child links detection as explained:
- If a user is looking for the concept of a large backyard, it could be a good idea to show all listings that mention the base form big backyard, huge backyard, etc. In addition, we can also show the user home with concepts such as covered large backyard, fenced huge backyard, etc. that are children of the concept backyard. This not only helps in better listing discoverability for the user, but we can also create relevant touch points for the user to better refine their search preference and look for nuanced concepts. This knowledge can also help us do query relaxation in areas where there is less inventory
We have trained BERT-based models in-house that can help classify relationship types given a pair of nodes or generate candidates. Figure 6 depicts the flow of the link discovery process:
Base form represents the phrase for which we want to find child nodes. The candidate bank can be a list of all available nodes we can potentially connect to.
- The first step in connecting nodes is candidate generation, which identifies a limited number of nodes that could be connected to a given node. For the candidate generation process, we use an in-domain SBERT model to generate candidate embeddings and generate nearest neighbor candidates to be sent to the final pairwise classification model. This process is to reduce the computation cost of comparing all the pairs in the candidate bank.
- The second step is a pairwise classification for a given relationship. The pairwise classification model takes the base form and each selected candidate by SBERT one at a time and makes predictions on a given type of relationship.
- We additionally have a Human in the loop step (HITL) as well to get this verified using a human annotator when needed to ensure high accuracy.
- The same process is followed for synonyms, parents, or other relationships as well.
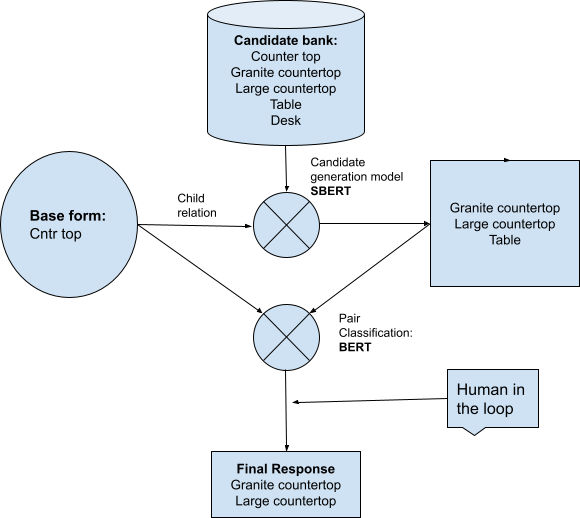 Figure 6: Explaining the process of discovering links across nodes in KG
Figure 6: Explaining the process of discovering links across nodes in KG
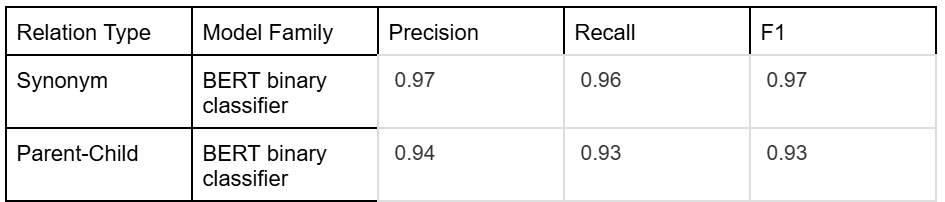 Table 1: Performance of in-house trained BERT-based models for Synonym and Parent-child relation discovery
Table 1: Performance of in-house trained BERT-based models for Synonym and Parent-child relation discovery
KG updates and versioning: As you may have guessed by now, the process of creating and maintaining the KG is a dynamic process since there is a constant inflow of new information and updates sent across data sources. This makes the process of maintaining and updating KG a critical and challenging task in order to return correct information at any point in time. Typical updates can range from updates to listing description, image, and property structure data that is more common to rare occurrences of updates in definitions of some key concepts, parent-child relationships, and new node creation. In order to cater to the above-mentioned changes, we need to have a KG update workflow in place and a versioning methodology for easy tracking and analysis in the future. Two broad classes of updates we see at Zillow and the complexities associated with them are:
- Point-wise updates: These refer to local changes in the KG that have a limited scope of impact and are normally limited to small sets of nodes. This can include updates in a listing description that show some home concept getting added or removed, new images added to a property, new base forms added to KG coming from a new source, etc. These changes are normally localized and have a limited impact on the other nodes on the graph. Hence these updates are easy to make and maintain.
- Knowledge base updates: This refers to bigger updates that have an impact across a variety of nodes and impact a lot of downstream applications that consume this data. This can be related to Ontology change, the addition of a new relationship type, or an update to a concept's parent/child or synonym list. These changes alter the way the data gets consumed and inferred by applications and hence need stricter control and tracking mechanisms for updates and point-in-time analysis we may need in the future.
There are multiple ways to handle the above-mentioned updates and tracking of the KG depending on the use case, frequency of data updates, and consuming applications. At Zillow, we adopt the following mechanism of KG updates and versioning:
- We try to classify our major update tasks as either belonging to Pointwise updates or Knowledge-based updates. A Point-wise update is easy to execute and requires smaller changes to the KG and minimal communication to consumers. We normally conduct Knowledge-based updates less frequently and rely on the help of subject matter experts and humans in the loop to ensure high accuracy. Also, extensive communication is done with downstream clients to ensure limited impact.
- We do time-based versioning of our KG and have the ability to maintain multiple versions at the same time. This helps improve tracking and gives consumer teams enough time to move to the next version of the KG. Not all teams use all parts of KG for their use. As such, they can make updates as needed when a new version of the KG is rolled out.
- Major releases and updates are made available to teams for review and feedback before a new version is released.
Results
The KG has been a great tool for us in aggregating data across different sources, standardizing it, and powering many new experiences and products. This enabled us to launch the first Natural Language Search experience in the real estate domain and we experienced lifts in customer experiences measured through AB tests. We also observed a significant lift in the number of properties shown for keyword searches, the ability to understand user queries better, and better relevance score for properties shown to users. The standardization also led to a better understanding of users and improved our search and ranking algorithms. The initial success has been encouraging and paves the way for our future extension of the KG, as well as delighting our customers through new products and services.
Acknowledgments
This work would not have been possible without the active support and contribution of the amazing Search AI team here at Zillow. Kudos to Raghav Jajodia Supriya Anand Shourabh Rawat Jyoti Prakash Maheswari for the work in creating the platform and technology that helps in improving and creating new experiences for Zillow Customers. We would also like to thank Eric Ringger and Matthew Danielson for reviews and suggestions for the content of this blog.
References
- Giuliano Janson, Zachary Harrison, Anish Khazane, “Helping Users Discover Their Dream Homes Through Home Insights Collections” Zillow Tech Blog. Feb 13, 2023
- Anish Khazane and Zachary Harrison, “Helping Home Shoppers Find a Home to Love Through Home Insights,” Zillow Tech Blog. August 8th, 2022
- Jyoti Prakash Maheswari, “My Internship at Zillow Group AI Part 1: Attribute Recognition in Real Estate Learnings”, Zillow Tech Blog. September 10th, 2019.
- Shourabh Rawat, “Organizing Real Estate Photo Collections for Visual Browsing”, Trulia Blog
Related Articles




Sign up for Zillow news updates
Subscribe to receive daily emails for the latest Zillow news and announcements, product updates and more.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23111116;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M.67,84.17v-9.38L39.19,20.75v-1.12H1.34V4.67h62.64v9.38l-37.85,54.04v1.12h38.97v14.96H.67Z'/%3e%3cpath%20class='st0'%20d='M75.04,9.36c0-5.58,4.13-9.71,9.94-9.71s9.94,4.13,9.94,9.71-4.13,9.71-9.94,9.71-9.94-4.02-9.94-9.71ZM76.71,84.17V27h16.53v57.17h-16.53Z'/%3e%3cpath%20class='st0'%20d='M106.3,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M135.33,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M161.79,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM208.58,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M246.32,84.17l-17.2-57.17h16.86l11.61,40.64h1.12l10.16-40.64h16.53l10.94,40.98h1.12l11.39-40.98h16.41l-17.31,57.17h-21.55l-8.71-37.85h-1.12l-8.6,37.85h-21.66Z'/%3e%3cpath%20class='st0'%20d='M362.44,84.17V4.67h56.94v15.86h-38.3v17.53h33.5v14.51h-33.5v31.6h-18.65Z'/%3e%3cpath%20class='st0'%20d='M428.76,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.53Z'/%3e%3cpath%20class='st0'%20d='M471.64,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM518.43,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M545.11,84.17V27h16.52v8.04h1.12c4.24-6.48,9.71-9.71,16.64-9.71,12.95,0,21.55,10.05,21.55,23.78v35.06h-16.52v-32.72c0-7.03-4.02-11.95-10.72-11.95s-12.06,5.25-12.06,12.51v32.16h-16.52Z'/%3e%3cpath%20class='st0'%20d='M617.13,65.74v-26.69h-8.04v-12.06h8.49l3.24-18.09h12.95l-.11,18.09h13.06v12.06h-13.06v26.02c0,4.8,2.9,8.04,7.59,8.04,1.56,0,4.02-.33,5.92-.78v11.84c-3.24,1.12-7.93,1.79-11.17,1.79-11.5,0-18.87-8.15-18.87-20.21Z'/%3e%3cpath%20class='st0'%20d='M686.58,84.17V4.67h34.95c19.43,0,31.93,10.27,31.82,26.69,0,16.3-12.62,26.8-31.93,26.8h-16.52v26.02h-18.31ZM704.89,44.08h15.07c9.16,0,14.85-5.02,14.85-12.73s-5.81-12.62-14.85-12.62h-15.07v25.35Z'/%3e%3cpath%20class='st0'%20d='M757.71,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM804.49,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.19,6.7-15.19,16.19,6.25,16.3,15.19,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M831.17,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.52Z'/%3e%3cpath%20class='st0'%20d='M874.16,55.58c0-18.2,12.62-30.37,31.04-30.37,15.52,0,27.36,8.71,29.25,22.22l-15.41,2.01c-1.45-6.25-7.26-10.61-13.62-10.61-8.37,0-14.74,6.92-14.74,16.75s6.25,16.75,14.63,16.75c6.59,0,12.17-4.35,13.73-10.5l15.52,1.9c-2.12,13.51-14.07,22.22-29.37,22.22-18.2,0-31.04-12.28-31.04-30.37Z'/%3e%3cpath%20class='st0'%20d='M944.73,84.17V1.32h16.52v33.39h1.12c4.35-6.25,9.71-9.49,16.64-9.49,12.95,0,21.66,10.05,21.66,23.67v35.28h-16.52v-32.83c0-7.03-4.13-11.95-10.83-11.95s-12.06,5.25-12.06,12.62v32.16h-16.52Z'/%3e%3c/svg%3e)
