- Press Releases
Sustainability
Social Impact
Explore how Zillow is driving real progress toward a more affordable and accessible housing market.
- Investors
- Careers
10 min read
Personalized Location Preference for Home Recommendations
Written by Ondrej Linda on April 10, 2018
Perhaps not surprisingly, one of the most important features for home recommendations is a user's location. In this blog post, we first discuss a simple baseline method for modeling a user’s location preference based on zip-code counting. In the second part, we outline an alternative method based on clustering past user home clicks and building a personalized click density model for each individual user.
Home Recommendations
The Personalization & Relevance team within Zillow's Artificial Intelligence group (formally known as Data Science and Engineering) is responsible for developing a personalization layer across various products such as search and email. The main mission of our team is to make it easier for Zillow's users to discover and find relevant home information and we strive to guide users through all aspects of the real estate market. We learn from a user’s interaction history on the website and in the mobile apps and then customize the displayed content accordingly.
One of the core products developed by our team is a content-based home recommendation engine. The engine builds a user profile for each user and upon request makes recommendations by 1) generating a set of candidate homes and 2) ranking these homes based on a predicted match between the user profile and the candidate homes. This prediction is based on various features. Below we discuss two ways to construct input features capturing user's location preference.
Zip-code counting
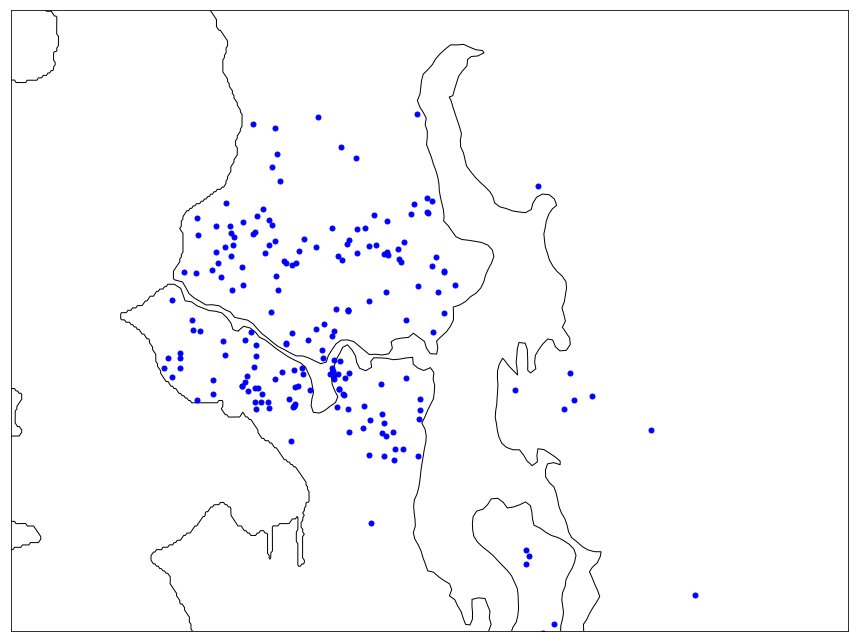
According to the Zillow Consumer Housing Trends Report, the typical US home buyer spends 4.3 months searching for their new home. During this time, users repeatedly visit our site and apps, search their target area, and interact with listed homes. This interaction history can be viewed as a random sample from some unknown location preference density function. We can assume that areas in which users explored more homes are more likely to be relevant to that user. Furthermore, for near-future home click prediction, areas explored more recently by the user are also more likely to be more relevant . As an example, here is a plot of the locations of the 200 most recently clicked homes by a potential home buyer in Seattle, WA.
Zip-code Histogram
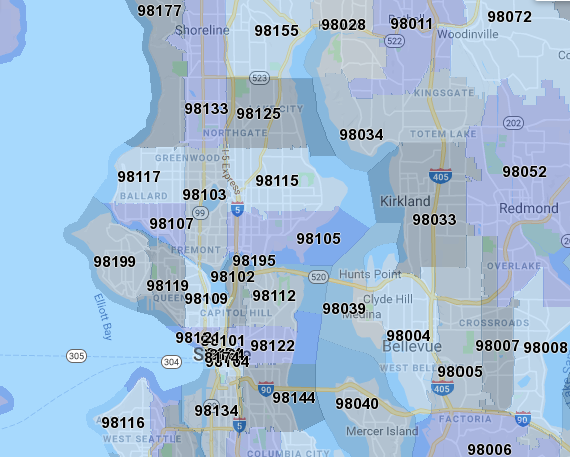
In order to build a user's location preference profile, we need some way to aggregate and summarize the recorded home interaction history. One intuitive way to do this is to leverage the already existing decomposition of the United States into zip-code areas. The figure below shows the zip-code area subdivision in and around Seattle.
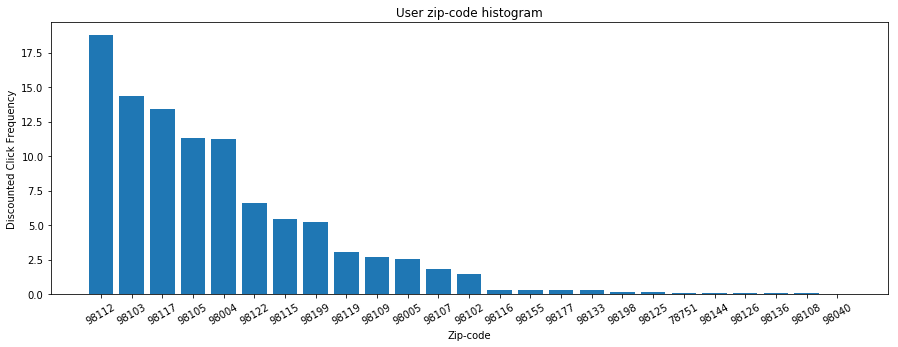
To model the user's location preference with respect to zip-codes, we can simply count home clicks in each zip-code. To accommodate for time-shifting user preference, we can weight each click with an exponentially decay based on how long ago a particular home was clicked. After doing this, we obtain a user zip-code histogram based on the discounted click frequency as shown below, with the most recent and frequent user home interactions in zip-codes 98112, 98103 and 98117.
Zip-code Location Preference
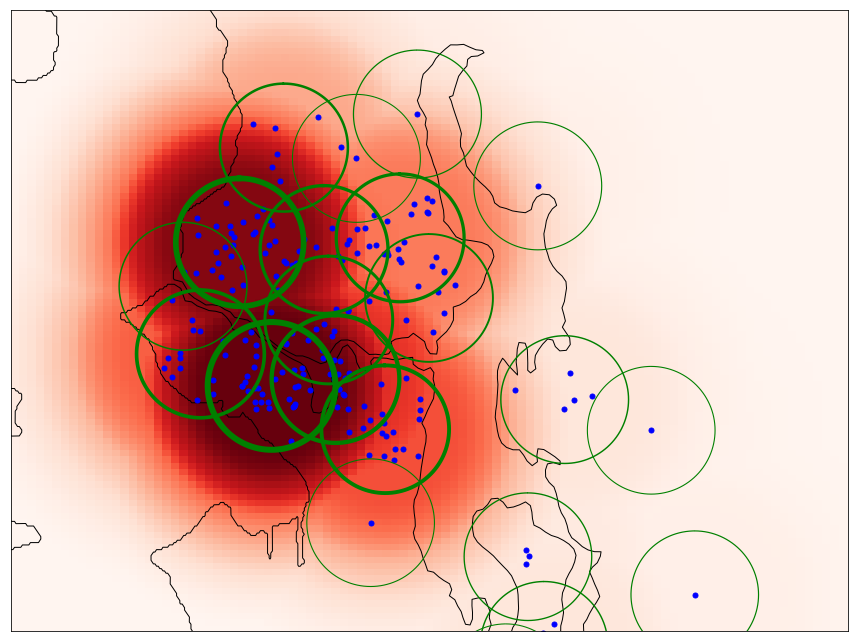
Once this user profile is constructed we can use it to extract features for our user home match score prediction model. For example, we can extract features based on the normalized zip-code histogram count for each candidate home. In our example, homes in 98112 would have the highest value, followed by homes in 98103, 98117 and so on. This method is intuitive, simple to implement and easy to incrementally update as new home interactions are added to the profile. However, it suffers from several drawbacks, especially when it comes to how accurately it models the user's location preference. To visually understand what this zip-code count based matching feature looks like, we have rendered a map of the zip-code histogram-based location preference. The shade of the color of each cell in the map overlay is assigned based on the nearest zip-codes normalized discounted histogram value (i.e. the darker the shade of red, the higher the location preference value).
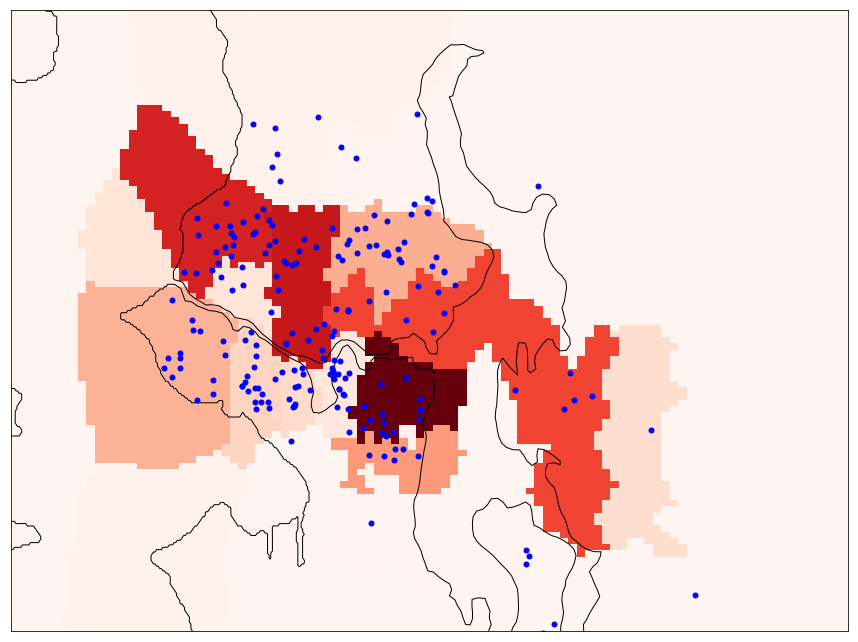
We can see that this location relevance feature is rather discontinuous and does not exactly match our real world intuition. For instance, it is quite likely that two homes very close to each other in terms of walking or driving distance might get vastly different feature values just because they are located on different sides of a zip code boundary. Furthermore, while there are certain aspects of zip-codes that might guide users in their search (e.g., school assignment, or state boundary), most users are likely not aware of the precise zip code boundary, and each user might understand neighborhoods and nearby areas in their own unique way.
Personalized Location Preference
To address the above identified issues, we decided to experiment with a new solution for modeling user location preference that would match our set of desired properties:
- Simple to implement
- Fast, requiring preferably a single pass through the data
- Supports incremental updates as new clicks arrive
- Better predicts the user’s location preference
Intuitively, we first need a way to model the spatial distribution of user clicks, which could then be used to predict future home clicks. To do this we have decided to first cluster the set of user clicks. The reasons for this are both computational since clustering reduces the number of parameters for users with a large amount of clicks, as well as accuracy-related since clustering also reduces noise in sparse data by grouping data points together. However, while there are many available clustering methods to group points in 2D space, not many of them fit our specific needs.
Single Pass Clustering
The Single Pass clustering method fits our needs very well. Despite a lack of any guarantees to produce an optimal clustering, it works just fine for our use case, producing a reasonable representation of a user's location preference with small computational effort. The pseudocode of the method can be summarized as follows:
- Randomly select a data point, and assign it to a new cluster
- For each remaining data point:
- Compute the distance to the nearest cluster
- If the distance is more than max_radius, create a new cluster
- Else update the nearest cluster by shifting its center towards the new point
- (The amount of shift depends on the weight of the new data point and the total weight of points already assigned to the cluster)
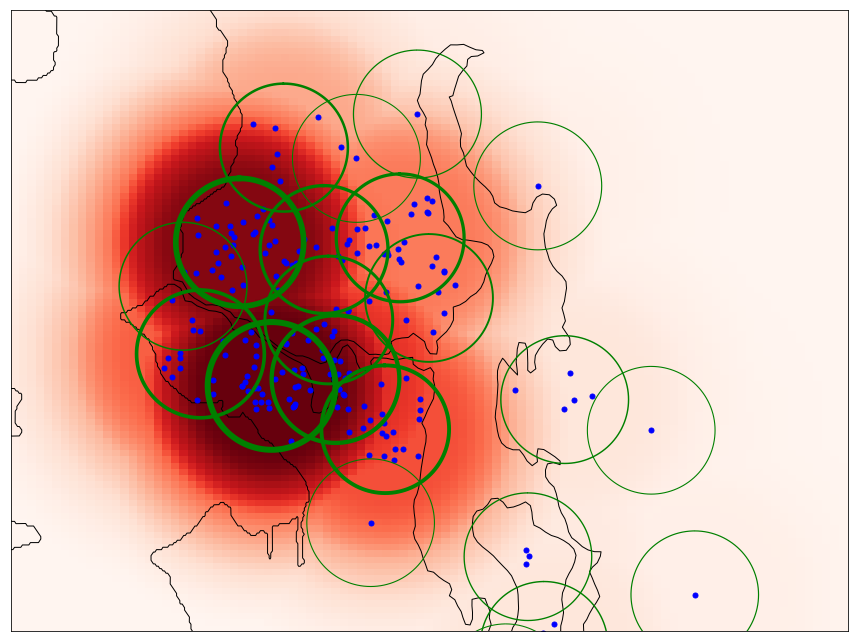
We can see that this method does not require a pre-specified number of clusters, but instead it relies on a maximum cluster radius threshold. We can easily set this threshold based on the preferred location resolution (or even set it dynamically based on home density in a particular area). To show how this clustering works, we have depicted the learned cluster distribution for the sample Seattle home buyer with a maximum cluster radius of 2.5 km. Note, that the width of each cluster’s border denotes its weight. In this clustering, we set the weight of each point to 1; i.e., there is no time-decaying weight.
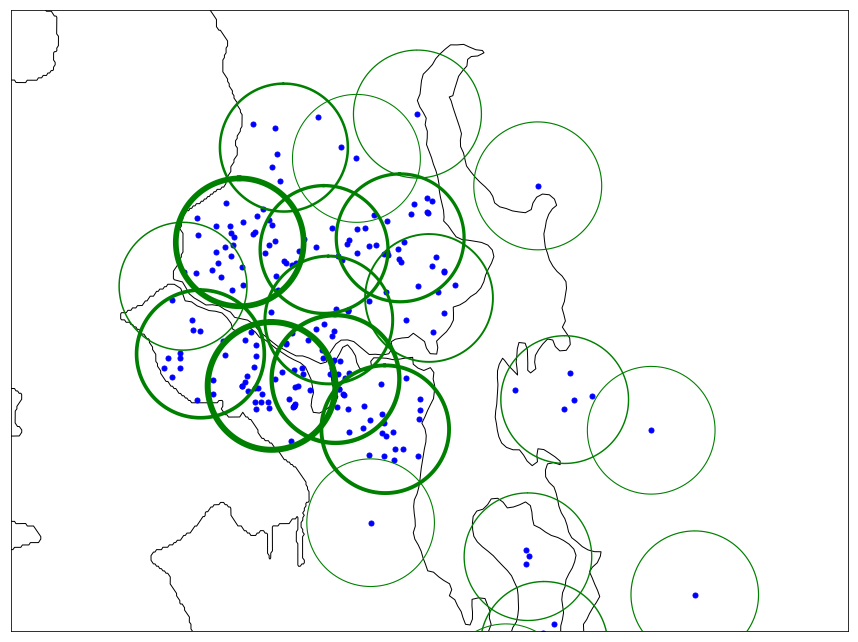
Cluster Membership Function
Once we construct the user’s cluster-based location preference representation, we can use it to compute the location matching feature between the user's profile and a new actively listed home. While there are many ways to do this, we have selected a simple method that models the match between cluster and point by using an s-shaped membership function. The nice property of this function is that its parameters are easy to interpret and tune for a specific application. The general definition of the membership function is given be the following equation:
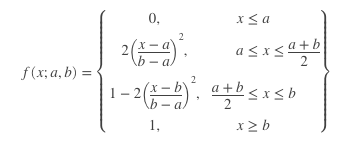
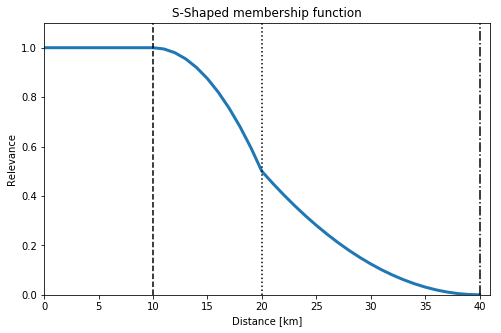
For our purpose, we have adapted the above equation to be decreasing function of the distance and to use cluster radius as parameters; in particular, first-outer radius and second-outer radius. The s-shaped function takes on the value of 1.0 for distances less than the cluster radius, it smoothly interpolates between 1.0 and 0.5 for distances between the cluster radius and the first-outer radius, and finally it smoothly interpolates between 0.5 and 0.0 for distances between the first-outer radius and second-outer radius. As an example, the plot below shows the s-shaped membership function with cluster radius of 10km, first-outer radius of 20km and second-outer radius of 40km.
In order to account for the weight of each cluster, we scale the amplitude of each cluster's membership function by the cluster's own normalized weight. As a result, the cluster with the highest accumulated weight has maximum membership of 1.0, and other clusters have maximum membership proportionally smaller. Finally, for each candidate home, we compute the location match feature as the maximum over the scaled s-shaped membership function with respect to all clusters.
To visually demonstrates what this feature looks like, we have again rendered its value in the Seattle area for the same example user. We can clearly see how the higher values of location preference center around higher-weight clusters, and the overall location relevance function is more smooth and continuous.
Adding time-weighting
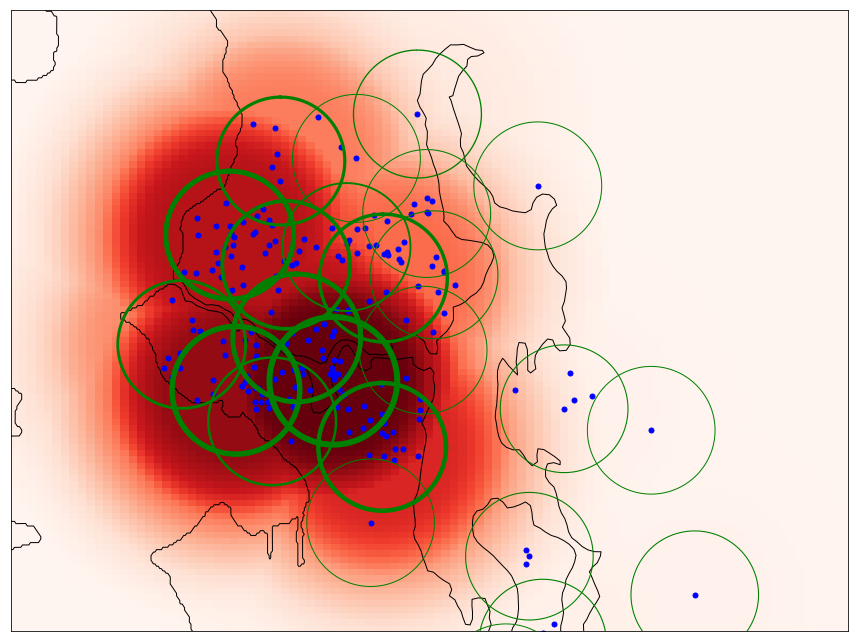
Finally, similarly to using exponential decay during zip-code counting to accommodate for recency, we can also incorporate recency into our new cluster-based representation. The Single Pass clustering method can weight each cluster point by its relative importance. All we need to do is to set the point importance based on the exponential decay of how long ago each home was clicked.
To show the effect of adding time-weighting, we render the location match feature value with time-weighted home clicks below. After accounting for time, the user's location relevance heat-spot moved further to the east close to the South Lake Union area.
Evaluation of Location Preference Features
In addition to visual inspection, we also would like to quantitatively evaluate the contribution of the cluster-based location preference feature. To do this we use a user’s past interaction history and measure how well we are able to predict their home clicks on the following day. We collect all candidate homes, namely the set of homes in the general area where the user is searching, as a search result set. We label homes clicked by the user as positive examples and the rest as negative. Once our content-based recommender engine predicts the user-home match score, we sort all results by this score.
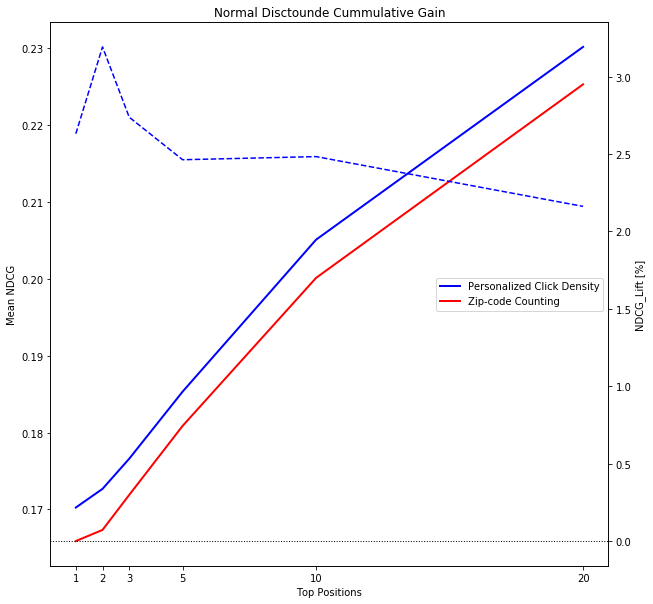
To evaluate the quality of the sort order, we compute the Normal Discounted Cumulative Gain (NDCG). By calculating the relative lift of the mean NDCG between two match score prediction methods, we can gain an understanding of which method is likely to display more relevant homes higher in the sort order. The intuition is that the higher we sort relevant homes, the more likely the user is to view them and engage with the search result set.
The chart below shows the absolute mean NDCG @ 1, 2, 3, 5, 10 and 20 top positions. In addition, the right-hand axis shows the relative lift of the mean NDCG between the user home match score prediction with personalized click density (the blue solid line) and zip-code counting (in red). The plot shows that personalized location preference density can better predict user's future home clicks than zip-code counting, which leads to an NDCG lift of 3% in the top of the sort and over 2% in the top 20 positions. As a next step, we will be validating the features in production via a live A/B test on the site.
Room for Improvement
In this post we demonstrated that the personalized click density-based location preference more accurately models user behavior. However, there is certainly a lot to be improved. From the heat maps shown above, we can see how our radiating location preference extends across lakes. Perhaps clustering in driving distance space would yield more accurate and intuitive results. Also, our current method uses a single distance threshold value for Single Pass clustering. Clearly, using a dynamic radius based on local listing density should yield additional improvements, i.e. smaller clusters in urban and larger clusters in rural areas.
If you find this work interesting and if you like to apply you data science and machine learning skills to our large-scale, rich and continuously evolving real-estate data set, please reach out - we are hiring.
Related Articles




Sign up for Zillow news updates
Subscribe to receive daily emails for the latest Zillow news and announcements, product updates and more.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23111116;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M.67,84.17v-9.38L39.19,20.75v-1.12H1.34V4.67h62.64v9.38l-37.85,54.04v1.12h38.97v14.96H.67Z'/%3e%3cpath%20class='st0'%20d='M75.04,9.36c0-5.58,4.13-9.71,9.94-9.71s9.94,4.13,9.94,9.71-4.13,9.71-9.94,9.71-9.94-4.02-9.94-9.71ZM76.71,84.17V27h16.53v57.17h-16.53Z'/%3e%3cpath%20class='st0'%20d='M106.3,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M135.33,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M161.79,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM208.58,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M246.32,84.17l-17.2-57.17h16.86l11.61,40.64h1.12l10.16-40.64h16.53l10.94,40.98h1.12l11.39-40.98h16.41l-17.31,57.17h-21.55l-8.71-37.85h-1.12l-8.6,37.85h-21.66Z'/%3e%3cpath%20class='st0'%20d='M362.44,84.17V4.67h56.94v15.86h-38.3v17.53h33.5v14.51h-33.5v31.6h-18.65Z'/%3e%3cpath%20class='st0'%20d='M428.76,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.53Z'/%3e%3cpath%20class='st0'%20d='M471.64,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM518.43,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M545.11,84.17V27h16.52v8.04h1.12c4.24-6.48,9.71-9.71,16.64-9.71,12.95,0,21.55,10.05,21.55,23.78v35.06h-16.52v-32.72c0-7.03-4.02-11.95-10.72-11.95s-12.06,5.25-12.06,12.51v32.16h-16.52Z'/%3e%3cpath%20class='st0'%20d='M617.13,65.74v-26.69h-8.04v-12.06h8.49l3.24-18.09h12.95l-.11,18.09h13.06v12.06h-13.06v26.02c0,4.8,2.9,8.04,7.59,8.04,1.56,0,4.02-.33,5.92-.78v11.84c-3.24,1.12-7.93,1.79-11.17,1.79-11.5,0-18.87-8.15-18.87-20.21Z'/%3e%3cpath%20class='st0'%20d='M686.58,84.17V4.67h34.95c19.43,0,31.93,10.27,31.82,26.69,0,16.3-12.62,26.8-31.93,26.8h-16.52v26.02h-18.31ZM704.89,44.08h15.07c9.16,0,14.85-5.02,14.85-12.73s-5.81-12.62-14.85-12.62h-15.07v25.35Z'/%3e%3cpath%20class='st0'%20d='M757.71,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM804.49,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.19,6.7-15.19,16.19,6.25,16.3,15.19,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M831.17,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.52Z'/%3e%3cpath%20class='st0'%20d='M874.16,55.58c0-18.2,12.62-30.37,31.04-30.37,15.52,0,27.36,8.71,29.25,22.22l-15.41,2.01c-1.45-6.25-7.26-10.61-13.62-10.61-8.37,0-14.74,6.92-14.74,16.75s6.25,16.75,14.63,16.75c6.59,0,12.17-4.35,13.73-10.5l15.52,1.9c-2.12,13.51-14.07,22.22-29.37,22.22-18.2,0-31.04-12.28-31.04-30.37Z'/%3e%3cpath%20class='st0'%20d='M944.73,84.17V1.32h16.52v33.39h1.12c4.35-6.25,9.71-9.49,16.64-9.49,12.95,0,21.66,10.05,21.66,23.67v35.28h-16.52v-32.83c0-7.03-4.13-11.95-10.83-11.95s-12.06,5.25-12.06,12.62v32.16h-16.52Z'/%3e%3c/svg%3e)
