- Press Releases
Sustainability
Social Impact
Explore how Zillow is driving real progress toward a more affordable and accessible housing market.
- Investors
- Careers
8 min read
Helping Buyers Explore the Real Estate Market via Personalized Recommendation Diversity
In this post we examine the application of a diversification algorithm to improve the diversity of our home recommendations.
Written by Ondrej Linda on September 25, 2018
Note: All work described in this blog post was done by Kai Liu from the University of Texas at Austin.
Home recommendations at Zillow are delivered via several channels, including email and mobile push notifications, to present a prospective buyer with a collection of relevant homes. Real estate poses several unique and interesting challenges for designing such a system. For example, in many high-demand real estate markets newly listed homes are of great interest and relevant to prospective buyers. Although new homes have not yet been seen and interacted with by a sufficient number of users -- hence implicit signal about them is lacking -- they need to be promptly recommended to relevant users. A content-based model can address this new-listing cold-start problem by scoring the relevance of each home for each user by evaluating the match between the user’s preference profile and the home’s attributes.
Such a content-based model is trained to predict a user’s click probability for each home (or “listing”) independently of all other homes. Consequently, similar recommended homes tend to have similar scores, and simply ranking these items by score may result in recommending nearly identical items (Figure 1). This lack of diversity among the recommendations fails to provide users with the variety of options necessary to discover what they care about, especially for buyers exploring the home market.

In this post we examine the application of a diversification algorithm to improve the diversity of our home recommendations. The main reasons for choosing this method are its ease of implementation and its applicability as a post-process for our (or any) recommender system.
Increasing the Diversity of Recommendations
Our home recommendation engine produces a set of candidate homes for each user, each with its predicted relevance score. The user’s candidate set is selected with the objective of including all of the homes that are relevant to that user while minimizing the size of the set. For example, one such possible candidate selection strategy might only consider homes in cities where the user has recently searched and which are priced within the user’s expected price range.
Next, we take the scored candidate homes as input and feed them to the diversification stage, where we re-sort the scored list A = {a1, a2, ... an} by optimizing the following submodular objective function :
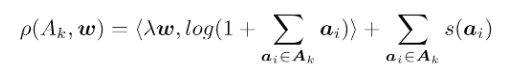
Here Ak is a subset of size k of the set of candidate homes A. Each home ai in A represents a one-hot-encoded d-dimensional category vector for listing item i. There are d categories (the number of different types of homes that we are trying to diversify over). Further, w denotes a d-dimensional vector that encodes user preferences for each of the d categories. Scalar λ is a weight on the user preference, which can be adjusted to vary the emphasis on diversity. Finally, s(a) is a function which maps an item to a score, such as the click probability (i.e., relevance score) computed by our recommendation model.
In the above equation, the weight vector w emphasizes the importance of each category to a user. By summing over per-item category vectors a in a given subset of items, we compute the total number of times that each category occurs in this subset. The logarithm has the following effect: the incremental utility of each additional item from category i decreases as more items from the same category are included in the subset. By optimizing this submodular objective function, highly relevant items are selected while preference is also given to selected items spanning a diverse set of categories.
The actual solution to the above optimization problem is computed using a greedy forward selection algorithm. First, we start with an empty list of selected items. Next, we provisionally add each available item individually to the selected set and compute the value of the objective function on that provisional set. The item that produces the best score is added to the selected list. This process is repeated until the required number of top diversified items is generated.
Assigning Homes to Categories of Interest
While we could partition listed homes based on price or house type, at a more fine-grained level there are no natural categories readily available. As a result, we decided to partition all listings into a small set of distinct categories via clustering. For simplicity we consider only the top most discriminative home attributes, namely price, square footage (sqft), and house type. We cluster the listings into 20 clusters using the bisecting k-means algorithm .
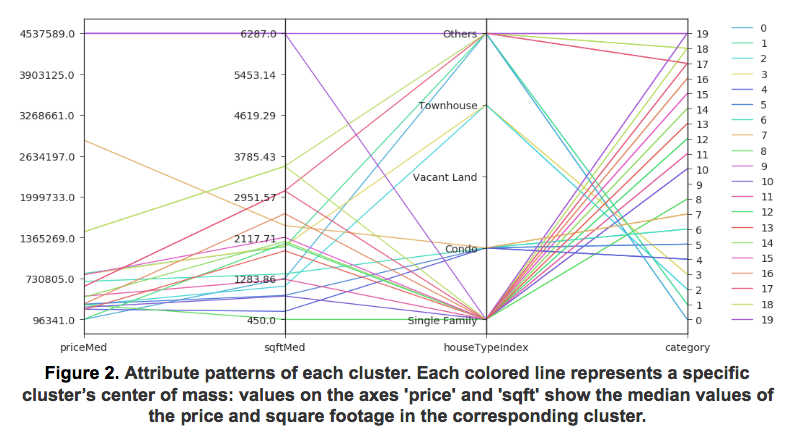
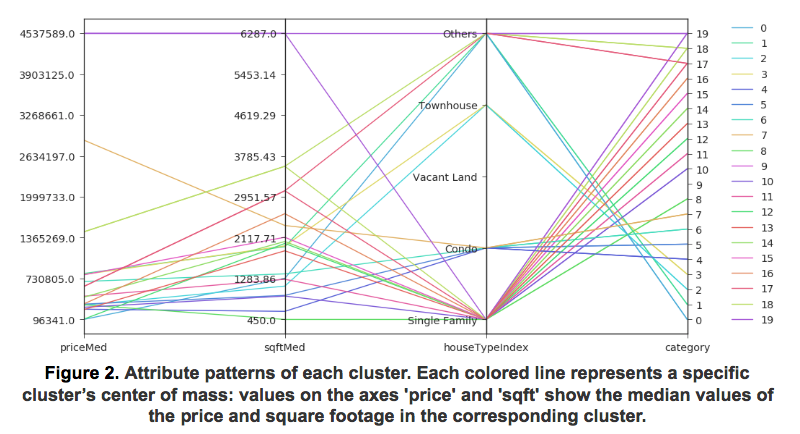
To verify that our clustering method learned meaningful categories, we first visualize the differences between the clusters. To conveniently visualize multiple clusters in multi-dimensional space we use the parallel coordinates method shown in Figure 2 . We can see that different clusters group various types of homes based on their size and price range as one might expect.
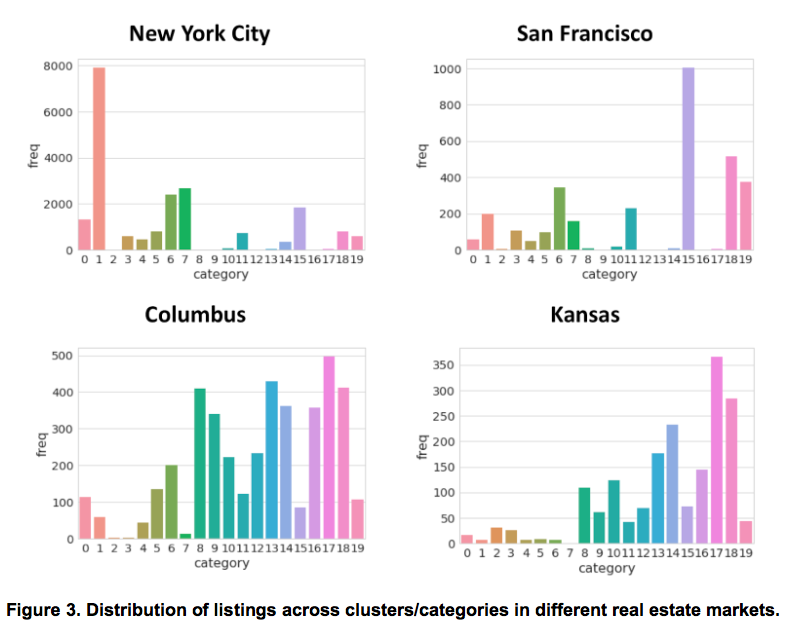
In addition, we have also compared the histograms of available homes in several distinct real estate markets, namely New York City, San Francisco, Columbus and Kansas. Figure 3 visualizes the home categories’ histograms, clearly depicting the varied nature of these distinct markets.
Learning User Category Preference
We compute two different types of user preferences here. The first one is a global user category preference, which not personalized and is instead is computed based on all users’ click history. The second method is personalized category preference, which takes the global preference as a prior and then adjusts the estimates for each user individually based on their past click history. Let’s consider each in turn.
Global User Preference
Global user preference wg is defined as the user preference for home categories for the average user. We use the per-category click-through-rate (CTR) across our entire training population to compute wg . To make the estimates more robust to low sample counts for rare home categories we smooth them with a Dirichlet prior.
Personalized User Preference
When computing personalized user preferences, we leverage the precomputed user profile, which contains a history of all recent user clicks and can therefore be used to estimate a user’s interests cu for each listings category. To improve our estimates for users with limited past click history, a Bayesian estimation is again applied to estimate the personalized user preference. Based on the method described in , we use a Dirichlet distribution as a prior distribution with a parameter α0, where α0 is assumed to be the global user preference (our wg). Then the personalized user preference can be computed as:
![]()
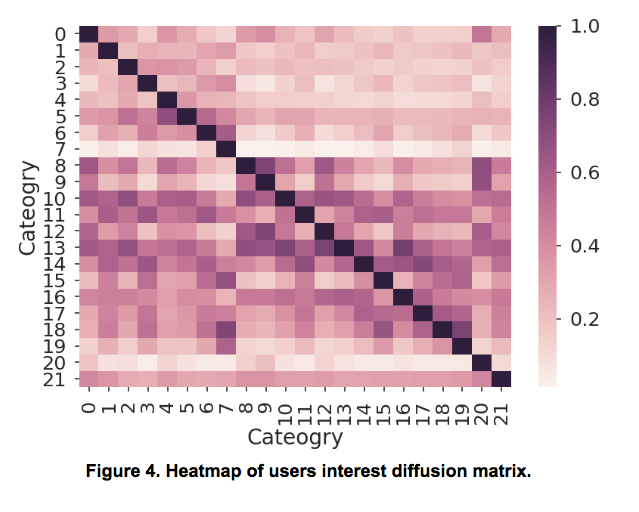
In addition, users’ interest on different categories are commonly correlated. For example, if 80% of users who clicked listings in category i also clicked listings in category j, there is a high chance that a user who only clicked listings in category i might also be interested in category j. To give these users the opportunity to interact with listings from different categories, we add a user interests diffusion matrix M. Each element mij represents the proportion of users who clicked listings in category j and also clicked listings in category i. This matrix M is multiplied with the user preference estimates effectively diffusing some of users’ preferences to other similar categories. Figure 4 shows the generated user signal diffusion matrix based on users’ click history.
Experimental Results
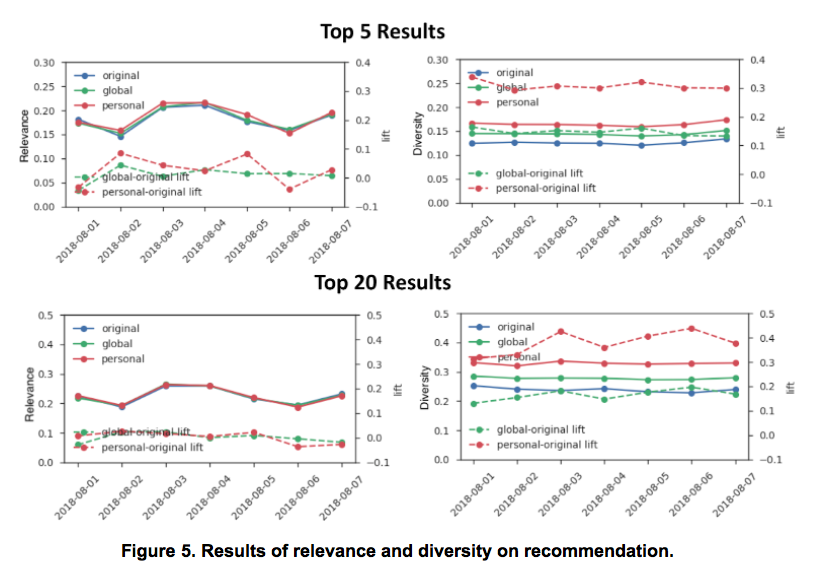
To evaluate the performance of the diversity model offline, we consider both the relevance and the diversity of the re-sorted recommendations. For relevance, we use NDCG as our metric. For diversity we measure the average proportion of categories with at least a single home selected up to a given rank. Ideally, the re-sorted recommendations would have a high diversity compared to the original recommendations while maintaining a comparable level of relevance (i.e. neutral NDCG lift). We compared the relevance and diversity of our recommendations for a sample of users over a period of 7 days. Both NDCG and diversity are evaluated for the top 5 and top 20 recommendations. The results are shown in Figure 5. We can see that both global and personalized diversity models maintain similar relevance to the original ranking based on the NDCG metric; i.e., the NDCG lift remains neutral within bounds. However, both the global and personalized diversity methods provide significant lift in our diversity metric, with the personalized diversity model especially lifting the diversity by ~30% and ~40% at top 5 and top 20 recommendations, respectively.
Conclusion
In this blog post, we explored the application of a personalized diversity algorithm method first proposed by researchers at Amazon . The method improves the ability of Zillow’s customers to explore diverse real estate market options. We have demonstrated that this diversity model helps improve the diversity of home recommendations without sacrificing any relevance whatsoever.
If you find this interesting and if you would like to apply your data science and machine learning skills to our large-scale, rich and continuously evolving real-estate data, please reach out - we are hiring in multiple roles.
Reference
Teo et al. Adaptive, Personalized Diversity for Visual Discovery. RecSys '16. 2016(4): 35-38.
M. Steinbach, G. Karypis and V. Kumar. A comparison of document clustering techniques,. Workshop on Text Mining, KDD, 2000.
A. Inselberg, Multidimensional detective, Information Visualization, 1997. Proceedings., IEEE Symposium on, pp. 100–107, 1997
Related Articles




Sign up for Zillow news updates
Subscribe to receive daily emails for the latest Zillow news and announcements, product updates and more.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23111116;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M.67,84.17v-9.38L39.19,20.75v-1.12H1.34V4.67h62.64v9.38l-37.85,54.04v1.12h38.97v14.96H.67Z'/%3e%3cpath%20class='st0'%20d='M75.04,9.36c0-5.58,4.13-9.71,9.94-9.71s9.94,4.13,9.94,9.71-4.13,9.71-9.94,9.71-9.94-4.02-9.94-9.71ZM76.71,84.17V27h16.53v57.17h-16.53Z'/%3e%3cpath%20class='st0'%20d='M106.3,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M135.33,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M161.79,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM208.58,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M246.32,84.17l-17.2-57.17h16.86l11.61,40.64h1.12l10.16-40.64h16.53l10.94,40.98h1.12l11.39-40.98h16.41l-17.31,57.17h-21.55l-8.71-37.85h-1.12l-8.6,37.85h-21.66Z'/%3e%3cpath%20class='st0'%20d='M362.44,84.17V4.67h56.94v15.86h-38.3v17.53h33.5v14.51h-33.5v31.6h-18.65Z'/%3e%3cpath%20class='st0'%20d='M428.76,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.53Z'/%3e%3cpath%20class='st0'%20d='M471.64,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM518.43,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M545.11,84.17V27h16.52v8.04h1.12c4.24-6.48,9.71-9.71,16.64-9.71,12.95,0,21.55,10.05,21.55,23.78v35.06h-16.52v-32.72c0-7.03-4.02-11.95-10.72-11.95s-12.06,5.25-12.06,12.51v32.16h-16.52Z'/%3e%3cpath%20class='st0'%20d='M617.13,65.74v-26.69h-8.04v-12.06h8.49l3.24-18.09h12.95l-.11,18.09h13.06v12.06h-13.06v26.02c0,4.8,2.9,8.04,7.59,8.04,1.56,0,4.02-.33,5.92-.78v11.84c-3.24,1.12-7.93,1.79-11.17,1.79-11.5,0-18.87-8.15-18.87-20.21Z'/%3e%3cpath%20class='st0'%20d='M686.58,84.17V4.67h34.95c19.43,0,31.93,10.27,31.82,26.69,0,16.3-12.62,26.8-31.93,26.8h-16.52v26.02h-18.31ZM704.89,44.08h15.07c9.16,0,14.85-5.02,14.85-12.73s-5.81-12.62-14.85-12.62h-15.07v25.35Z'/%3e%3cpath%20class='st0'%20d='M757.71,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM804.49,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.19,6.7-15.19,16.19,6.25,16.3,15.19,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M831.17,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.52Z'/%3e%3cpath%20class='st0'%20d='M874.16,55.58c0-18.2,12.62-30.37,31.04-30.37,15.52,0,27.36,8.71,29.25,22.22l-15.41,2.01c-1.45-6.25-7.26-10.61-13.62-10.61-8.37,0-14.74,6.92-14.74,16.75s6.25,16.75,14.63,16.75c6.59,0,12.17-4.35,13.73-10.5l15.52,1.9c-2.12,13.51-14.07,22.22-29.37,22.22-18.2,0-31.04-12.28-31.04-30.37Z'/%3e%3cpath%20class='st0'%20d='M944.73,84.17V1.32h16.52v33.39h1.12c4.35-6.25,9.71-9.49,16.64-9.49,12.95,0,21.66,10.05,21.66,23.67v35.28h-16.52v-32.83c0-7.03-4.13-11.95-10.83-11.95s-12.06,5.25-12.06,12.62v32.16h-16.52Z'/%3e%3c/svg%3e)
