- Press Releases
Sustainability
Social Impact
Explore how Zillow is driving real progress toward a more affordable and accessible housing market.
- Investors
- Careers
12 min read
Building a Big Data pipeline to Process Clickstream Data
Clickstream data is one of the largest and most important datasets within Zillow. The data set contains a log of a series of page requests, actions, user clicks and other web activity from the millions of home shoppers and sellers visiting Zillow sites every month. The data powers many reporting dashboards and helps us answer complex business questions. From product initiatives to analyzing user behavior, personalization, recommendations and machine learning all depend on this valuable dataset to generate actionable insights.
We’ve always been successful at collecting this data through a pipeline, but due to the sheer size of the data set, making this ETL process efficient and scalable has been a huge area of focus for the team. With close to a billion events per day received via click stream data, we couldn’t initially scale fast enough to meet the growth in data volumes using our existing system. We sought a distributed platform which would enable the fast parsing and processing of large datasets via a massively parallel processing framework. Ensuring we get this data to the right dashboards in a timely manner is crucial as internal stakeholders are counting on it to make decisions. Our process has gone through several enhancements over time and here’s how we built it:
History
Version 1
We receive a large batch of raw web activity data in JSON format. On our end, we decided to use Amazon Redshift as our data warehouse and query platform due to its cost-effectiveness and inherent columnar database benefits. Our ETL process involved:
- Download the JSONs to local.
- Using C# .NET, parse and convert the JSONs to CSVs while performing a number of transformations along the way. Such as flattening various nested elements, deriving calculated columns, cleaning up text and formatting. We also split the CSV into multiple parts and compress them to make COPY more efficient.
- Upload CSVs to Amazon S3.
- Run COPY command in Redshift to copy CSVs from S3 to a Redshift table.
Scheduler: SSIS package via SQL Server Agent.
Version 2
At this point in our company's growth, the process started becoming slow due to increase in data volume. To make it fast again, we merged steps 1, 2, 3 above into a single step and added multithreading. Here is what it looked like:
- Read JSON lines into memory, skipping the download. Perform the transformations on the fly using .NET's multithreading capabilities. Write split CSVs into S3. Based on our server hardware, best performance was noticed when there are 8 parallel threads.
- Run COPY command in Redshift to copy CSVs from S3 to a Redshift table.
Scheduler: SSIS package via SQL Server Agent.

Version 3
Apache Hadoop is introduced into the picture. MapReduce written in Java. To replace an outdated .NET multi-threaded design. Hadoop cluster is launched and shut down for every run using command line (CLI) tools.
- Read JSON lines into memory, skipping the download. Perform the transformations on the fly using Hadoop, while writing CSVs into S3 in parallel.
- Run COPY command in Redshift to copy CSVs from S3 to a Redshift table.
Scheduler: Powershell+SQL Server based scheduling framework. Command line utilities for Hadoop cluster management.
Hadoop Cluster: 100 nodes with 16 vCPUs, 60 GB memory each.

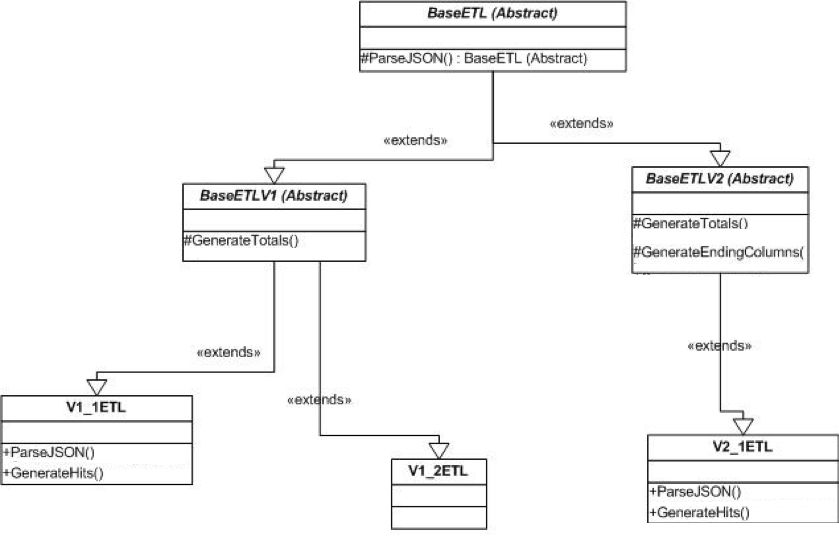
Hadoop MapReduce is implemented in Java. The java code is written such that it can support multiple current and future versions of the ETL and yet require as little change to the code as possible. This is done via a series of Abstract classes. All versions of the ETL start at BaseETL. From there, Version 1, 2 etc are created. These again are Abstract. Any changes made to BaseETLV2 will show up in any version that extends this. This allows us to make a general fix to all version 2s or all version 1s. The 'V' is the actual implementation. This has a ParseJSON function that is called when parsing data. With this Factory Producer based implementation, we need not create instances of any ETL and we instead use the Factory Producer class, which returns the correct version of the ETL we want.
Today
Version 4
Our web activity data is a collection of events generated from Zillow Group web platforms and mobile apps. Each web platform or mobile app maps to a separate data set in the source system storing the logs each day. For example, zillow.com, Zillow iOS app, Zillow Android app all have their own unique dataset IDs and corresponding source tables, identified using a dataset ID and Date. Dataset IDs are unique IDs for each app. This data is extracted from source table to Zillow Group Data Lake daily for all datasets.
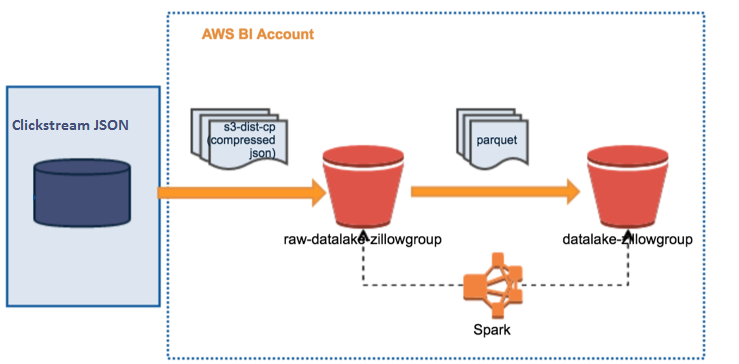
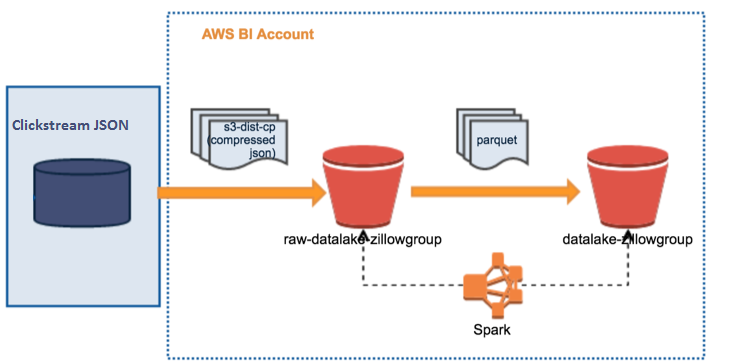
We set ourselves an audacious goal of building a new pipeline that makes the data available in the Data Lake in parquet format after its arrival in the source within 30 minutes. The biggest dataset is about 2 TB uncompressed for a single day. In addition to speed, there were other important decisions such as retries, alerting, auditing to be included in the design to make pipeline reliable. We tried different approaches to get this data in data lake. We decided to go with the one that is not only faster and simpler but can also be modularized in separate tasks. We did this in Apache Airflow, which is now our primary choice of ETL scheduler. One of the main advantages with this approach is the ability to retry from a failed step as opposed to re-running the entire pipeline. For more info on how we use Airflow, refer to an earlier blog post: https://www.zillow.com/data-science/airflow-at-zillow/
As soon as data is available in the source, we issue an export into JSON format. We use a dedicated Amazon EMR cluster for all the processing. The raw data in JSON format is moved over to “zillow group raw data lake” S3 bucket in Zillow Data Lake using 's3-dist-cp'. A Spark job on EMR transforms raw data into Parquet and places the result into “zillow group data lake” S3 bucket.
This latest version of our pipeline is our biggest leap forward and introduces several new big data frameworks in the picture:
- Spark is introduced to replace Hadoop.
- Elastic MapReduce (EMR) cluster replaces a Hadoop cluster.
- Apache Airflow replaces the Powershell + SQL Server based scheduling.
- Hive tables based on columnar Parquet formatted files replace columnar Redshift tables.
- S3 based Data Lake replaces Redshift based Data Warehouse.
- Copy JSONs to Amazon S3.
- Run our Spark processing on EMR to perform transformations and convert to Parquet.
Scheduler: Apache Airflow
EMR cluster configuration: A fully scaled up cluster looks like below:
- Master: 1 m4.4xlarge (32 vCore, 64 GiB memory, EBS only storage, EBS Storage: 200 GiB)
- Core: 10 r3.4xlarge (32 vCore, 122 GiB memory, 320 SSD GB storage, EBS Storage: none)
- Task 1: 10 m4.16xlarge (128 vCore, 256 GiB memory, EBS only storage, EBS Storage: 200 GiB)
- Task 2: 15 r4.4xlarge (16 vCore, 122 GiB memory, EBS only storage, EBS Storage: 200 GiB)
- Task 3: 10 r3.8xlarge (64 vCore, 244 GiB memory, 640 SSD GB storage, EBS Storage: none)
Design
Airflow DAG: DAG is designed to run each dataset independently based on availability of dataset in the source. This is accomplished using SubDags for each dataset. These SubDags are independent and can potentially run in parallel. But we observed issues with race conditions in subdag concurrency and moreover, we did not want to go too crazy with cluster size. So we decided to run the pipeline in a more controlled fashion. We only allow dag concurrency of 1 which means airflow will schedule only one dag run at a time and subdag concurrency of 4 which means 4 datasets can run at a time. In addition to that, we don't allow two big datasets to run at same time mainly to avoid big datasets competing for resources. This is achieved by using separate pool config in the Airflow with an available slot of 1.
Dag consists of 2 tasks: SubDag task and SNS task. There is exactly one SubDag task per dataset. In some cases, we have a single hive table storing multiple datasets. In such cases, we configure single SNS task dependent on multiple datasets.
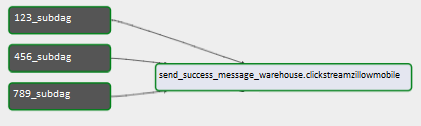
SubDag handles everything starting from data availability check to parquet processing.

Example Spark command:
Spark-submit
--master yarn --deploy-mode cluster
--name Web-Activity-ETL-987654321-2017-10-01
--executor-memory 20G
--driver-memory 5G
--conf spark.sql.files.maxPartitionBytes=16777216
--conf spark.sql.shuffle.partitions=5000 ./weblog/weblog-spark-etl-deploy-bundle.jar
--data-date 2017-10-01
--dataset-id 123456789
--role arn:aws:iam::12345:role/web-activity-role
--src s3://<zillow group raw datalake>/zillow/web-activity/json/
--dest /tmp/webactivityspark/parquet
--num-files 500
Performance: Running spark job for our biggest dataset under 30 mins was a goal. A couple of things that helped in increasing the performance significantly are: (1) Switching from Python to Scala made UDF's significantly faster as Scala can directly run on JVM. (2) Avoiding 'explode' function to extract dimensions in raw data and then join back to original dataset removed extra shuffle cost and caching. Instead of ‘explode’, we use index for each dimension to add new columns as look up happens in constant time.
Configuration: Various components of the entire pipeline are configurable through a YAML config file. A configuration-driven design allows for easy modification of following: (1) Add or remove a dataset ID in our pipeline (2) Update Spark settings for a dataset: spark_opts - It allows spark conf settings along with application args such as driver-memory, executor-memory and output number of files. (3) Update Dag and Subdag parallelism.
Alerting is done via Amazon SNS (Simple Notification Service).
Scheduling: We made sure no two big datasets run at same time on the cluster. This was mainly done to avoid over utilization of resources on Spark cluster. We created a separate pool in the airflow with single slot. We assign this pool for both of these datasets so at any given time if these datasets are picked by scheduler it would run one or the other, but not both. We have subdag concurrency of 4 which means 4 datasets can run at same time.
Hive tables: We store all of the raw web activity data under one primary hive table. Based on the expected query patterns, we chose to partition this parquet-based table on the fields dataset ID and data date. We also have set of secondary tables that are analysts facing and that sit on the same location as above table with exact same table definition. These additional tables are pre-filtered by dataset and provide a similar interface to queries written originally against Redshift.
Hive Metastore: We use Amazon Relational Database Service (RDS) for Hive Metastore. A persistent Hive Metastore removes the need to recreate Hive metadata (e.g. table structures and partitions) each time a new hadoop/spark cluster is started. Additionally, it allows teams across our organization to share the Hive metadata.
Benefits of using AWS
To solve the scalability and performance problems faced by our existing ETL pipeline, we chose to run Apache Spark on Amazon Elastic MapReduce (EMR). By running Spark on Amazon Elastic MapReduce (EMR), we can quickly create scalable Spark clusters and use Spark’s distributed-processing capabilities to process large data sets, parse them and perform complex calculations. Spark on Amazon EMR also meant we did not have to manage the Spark clusters ourselves.
As data volume continues to increase, the choice of Spark on Amazon EMR combined with Amazon S3 allows us to support a fast-growing ETL pipeline: (1) Scalable Storage: With Amazon S3 as our data lake, we can put current and historical raw data as well as transformed data that support various reports and applications, all in one place. So we now have a central place to enable infinite storage scalability at a low cost. All the raw data containing clickstream/user-traffic events is ingested and pushed into Spark on Amazon EMR. From the data lake, a number of applications such as personalization, recommendations, advertising optimization use the data without storage scalability concerns. Web activity is just part of several petabytes of data maintained in our Amazon S3 Data Lake. (2) Scalable Compute: With Spark combined with several features of Elastic MapReduce (EMR), we are able to scale up (or down) storage, compute & memory capacity automatically as well as on demand.
We wished to minimize our costs involved in running the EMR cluster for the duration of the pipeline. Various clickstream datasets processed by our pipeline varied quite a bit in terms of their size i.e. the volume of data and the number of records. This meant that the amount of required cluster resources such as CPU and memory also varied. We could potentially launch an EMR cluster big enough to handle our largest dataset. But smaller datasets which require significantly less powerful of a cluster would make this approach less cost effective. That’s where EMR Auto Scaling comes in handy. For more info on how we use auto scaling, refer to our earlier blog post: https://www.zillow.com/data-science/save-money-emr-autoscaling-spot/
Summary
The ETL job now takes around 30 minutes instead of several hours. Now we get data in the hands of users sooner than before during normal business hours. Due to the increased speed and reliability of our pipeline, clickstream/web activity data is made up-to-date sooner which makes dependent reports and models more accurate because they’re built with the absolute latest data. This is a huge benefit for business stakeholders and users, who depend on this information to influence their decisions.
We process several TBs of data per day and over a billion records per day across our Airflow pipelines. The biggest dataset in our web activity pipeline alone is about 2 TB of data (uncompressed) per day. Our table supporting the web activity data is the widest of our tables with about 700 columns. Due to existing dependent reports and a significantly sized user base already for Redshift, we are currently maintaining both our Redshift based Data Warehouse as well as S3 based Data Lake. Having both these solutions in place allows for a smooth transition from older to newer platforms, with minimal downtime in serving data for end-user’s needs.
Related Articles




Sign up for Zillow news updates
Subscribe to receive daily emails for the latest Zillow news and announcements, product updates, research and more.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23111116;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M.67,84.17v-9.38L39.19,20.75v-1.12H1.34V4.67h62.64v9.38l-37.85,54.04v1.12h38.97v14.96H.67Z'/%3e%3cpath%20class='st0'%20d='M75.04,9.36c0-5.58,4.13-9.71,9.94-9.71s9.94,4.13,9.94,9.71-4.13,9.71-9.94,9.71-9.94-4.02-9.94-9.71ZM76.71,84.17V27h16.53v57.17h-16.53Z'/%3e%3cpath%20class='st0'%20d='M106.3,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M135.33,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M161.79,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM208.58,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M246.32,84.17l-17.2-57.17h16.86l11.61,40.64h1.12l10.16-40.64h16.53l10.94,40.98h1.12l11.39-40.98h16.41l-17.31,57.17h-21.55l-8.71-37.85h-1.12l-8.6,37.85h-21.66Z'/%3e%3cpath%20class='st0'%20d='M362.44,84.17V4.67h56.94v15.86h-38.3v17.53h33.5v14.51h-33.5v31.6h-18.65Z'/%3e%3cpath%20class='st0'%20d='M428.76,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.53Z'/%3e%3cpath%20class='st0'%20d='M471.64,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM518.43,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M545.11,84.17V27h16.52v8.04h1.12c4.24-6.48,9.71-9.71,16.64-9.71,12.95,0,21.55,10.05,21.55,23.78v35.06h-16.52v-32.72c0-7.03-4.02-11.95-10.72-11.95s-12.06,5.25-12.06,12.51v32.16h-16.52Z'/%3e%3cpath%20class='st0'%20d='M617.13,65.74v-26.69h-8.04v-12.06h8.49l3.24-18.09h12.95l-.11,18.09h13.06v12.06h-13.06v26.02c0,4.8,2.9,8.04,7.59,8.04,1.56,0,4.02-.33,5.92-.78v11.84c-3.24,1.12-7.93,1.79-11.17,1.79-11.5,0-18.87-8.15-18.87-20.21Z'/%3e%3cpath%20class='st0'%20d='M686.58,84.17V4.67h34.95c19.43,0,31.93,10.27,31.82,26.69,0,16.3-12.62,26.8-31.93,26.8h-16.52v26.02h-18.31ZM704.89,44.08h15.07c9.16,0,14.85-5.02,14.85-12.73s-5.81-12.62-14.85-12.62h-15.07v25.35Z'/%3e%3cpath%20class='st0'%20d='M757.71,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM804.49,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.19,6.7-15.19,16.19,6.25,16.3,15.19,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M831.17,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.52Z'/%3e%3cpath%20class='st0'%20d='M874.16,55.58c0-18.2,12.62-30.37,31.04-30.37,15.52,0,27.36,8.71,29.25,22.22l-15.41,2.01c-1.45-6.25-7.26-10.61-13.62-10.61-8.37,0-14.74,6.92-14.74,16.75s6.25,16.75,14.63,16.75c6.59,0,12.17-4.35,13.73-10.5l15.52,1.9c-2.12,13.51-14.07,22.22-29.37,22.22-18.2,0-31.04-12.28-31.04-30.37Z'/%3e%3cpath%20class='st0'%20d='M944.73,84.17V1.32h16.52v33.39h1.12c4.35-6.25,9.71-9.49,16.64-9.49,12.95,0,21.66,10.05,21.66,23.67v35.28h-16.52v-32.83c0-7.03-4.13-11.95-10.83-11.95s-12.06,5.25-12.06,12.62v32.16h-16.52Z'/%3e%3c/svg%3e)
