- Press Releases
Sustainability
Social Impact
Explore how Zillow is driving real progress toward a more affordable and accessible housing market.
- Investors
- Careers
10 min read
Using SageMaker for Machine Learning Model Deployment with Zillow Floor Plans

In Zillow Floor Plan: Training Models to Detect Windows, Doors and Openings in Panoramas, we described how we trained our ML model to help generate Zillow Floor Plans. In this post we are going to describe how we designed and implemented the infrastructure that would deploy and serve our models.
Our goal was to build an infrastructure that was:
- Easy to integrate into our services and pipelines
- Scalable and reliable
- Allowed for easy addition of new models
- Could be repurposed with across the Zillow infrastructure
We investigated multiple options from using dedicated servers within Zillow, to running our inference servers on AWS EC2. In the end, we chose SageMaker for deploying and serving our ML models. Although there is a price mark-up around 40%¹, the ease of use, varied features, and the reliability of SageMaker justified the cost. In the following sections we are going to give a broad overview of Sagemaker, describe how we built this infrastructure, and finish with the current status of this project and our future plans.
As the whole infrastructure is built around AWS ecosystem, it would be helpful to describe briefly some of these services as we will be using their abbreviations many times within this post: Lambda is AWS’s function-as-a-service (FaaS), automatically running code without managing any kind of server or resources. Step functions allow you to coordinate multiple AWS services into serverless workflows. Each step can be a Lambda or a SageMaker operation. S3 is AWS’s storage solution and DynamoDB is AWS’s non-relational database. Cloudwatch is a monitoring and management service for all things related to AWS resources. ECR is AWS’s container registry and EC2 is the name of the AWS compute cloud.
What is SageMaker?
SageMaker is AWS’s fully managed, end-to-end platform covering the entire ML workflow within many different frameworks. It offers services to:
- Label data
- Choose an algorithm from model store and use it
- Train and optimize an ML model
- Deploy and serve your own ML models, make predictions, and take action
We already had local machines that we used to train and create our ML models. For this particular application, we were more focused on inference rather than periodic retraining cycles. What is more, GPU instances available in SageMaker were too expensive relative to the projected gain in accuracy by exhaustively retraining ML models. Therefore, we decided to use SageMaker only to serve and deploy our ML models.
Choosing the right features
SageMaker has a plethora of features which makes it a good candidate for the productization of ML models. It offers both online and offline inference solutions. It is built on top of EC2 therefore there are many CPU/GPU options available. In addition to standard EC2 instances, SageMaker also offers Elastic Inference, which uses CPU instances while hosting, but magically switches to use GPU resources during inference that result in significant cost reduction.
Our main reason for choosing SageMaker was the fact that it is highly integrated with other AWS services and most of our services were already built within the AWS ecosystem.
However, having this many features and options can be quite confusing. Therefore, to make things simpler, we needed to ask the following questions to choose the most cost-effective solution:
1- Do we need a live service for inference requests?
2- How much time do we have between the data generation and the actual use of predictions?
3- If we choose the offline inference, how should we bundle the input data?
Online inference is enabled via creating endpoints that would respond to training or inference requests. It takes around 10 minutes to create this host and enables live inference. It accepts images that are stored in S3 as input or even as an “application/x-image” data source along with your inference request.
On the other hand, offline inference, or batch transform, comes in handy where the application does not require live inference and all data is already in S3. It takes a list of input images and stores inference results as JSON objects in S3.
In this project, we would like to detect windows, doors, and openings from a panoramic image. In addition to generating high fidelity data which can be used for many other different purposes as described earlier (such as sunlight simulation, automatic room merging), our main goal is to automate floor plan generation, reducing the time and cost.
We ran numerous experiments by changing different parameters:
- SageMaker Parameters
- Online vs Offline Inference
- EC2 instance type
- Instance count
- Internal parameters
- Batch size
- Current and Projected 3D tour data
- SLA in floor plan generation
After an extensive investigation and experimentation period, we decided to use Batch Transform CPU instances. It was the most cost-effective solution for our business needs because:
- It is feasible and adequate. We did not need real-time inference, as there is enough time between the panoramas created and predictions used.
- It is an offline service, meaning that we did not need to maintain and keep a service online and make sure it has enough instances. AWS takes care of everything.
- It is cheaper. We only paid for the amount of time batch transform takes.
An example cost analysis
There are 3 types of costs that come with using SageMaker: SageMaker instance cost, ECR cost to store Docker images, and data transfer cost. Compared to instance cost, ECR ($0.1 per month per GB)² and data transfer ($0.016 per GB in or out) costs are negligible. What is more, if we used pre build AWS Docker images and stored the data in S3 we would not need to pay for either one of them.
Assuming that the SageMaker instance is the only cost, Table 1 describes what the rough projected cost would look like daily for 1000 images with given inference times for a given ML model.
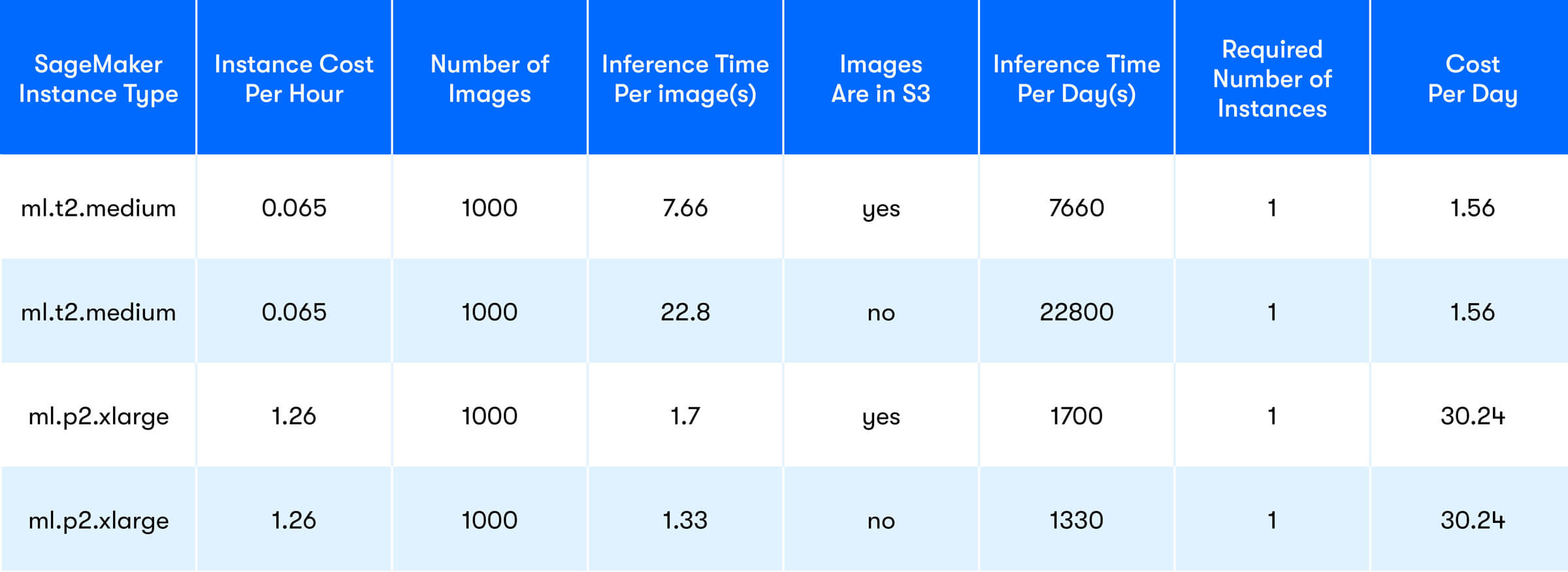 Table 1 - Projected SageMaker cost for online inference
Table 1 - Projected SageMaker cost for online inference
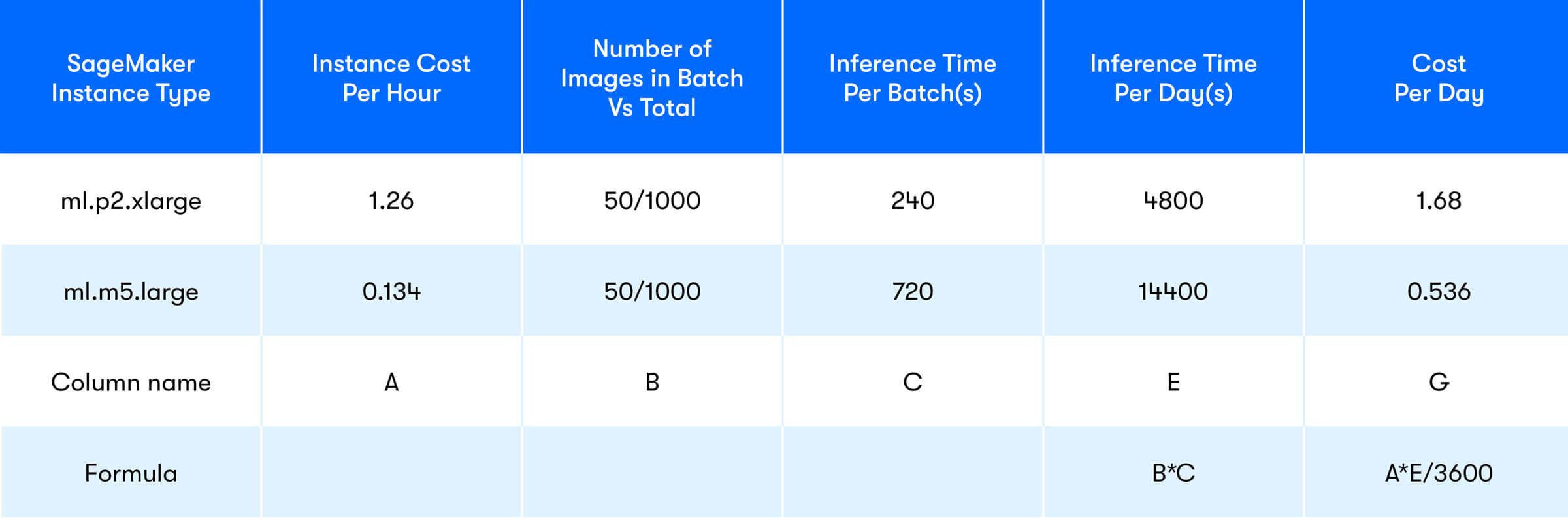 Table 2 - Projected SageMaker cost for offline inference
Table 2 - Projected SageMaker cost for offline inference
For batch inference, it’s important to consider the fixed cost of booting up a Docker container and installing necessary packages which may take up to 1-2 minutes.
Integrating SageMaker into Our Pipeline
Deploying ML models in SageMaker
In order to run batch inference, SageMaker requires a SageMaker model. A SageMaker model can be considered as a configuration, which includes information about the properties of the EC2 instance created, and the location of the model artifacts.
EC2 instance configuration enables setting the number of instances, linking to Docker image in ECR, and CPU/GPU information. Model artifacts include a frozen/saved model and the inference code in a certain format. Further customization may be required depending on the underlying ML framework and Docker image being used. Writing custom code to preprocess/postprocess data and how the model will be served is also an option. Examples for these can be found in AWSs SageMaker container GitHub pages.
Every batch transform job can be summarized as follows:
- Create an EC2 instance using the image given in SageMaker model
- Load ML model artifacts and start a model server specific to the ML framework
- Given an input dataset, run inference and save outputs in S3
- Kill the EC2 instance
We touched base on EC2 instances and model artifacts but what are these model servers?
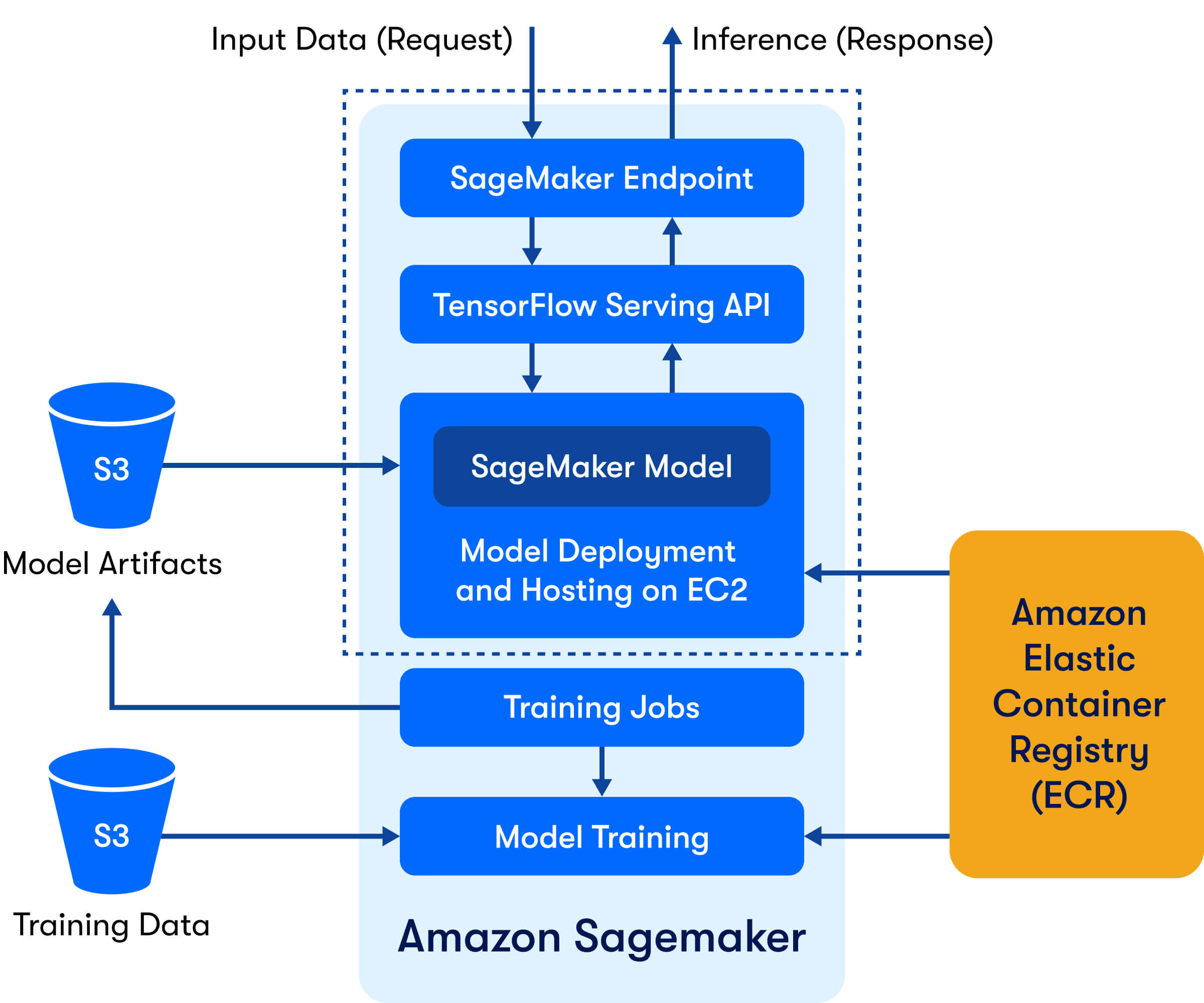 Figure 1 - A block diagram depicting how SageMaker creates a host to serve inference requests via ML model servers.
Figure 1 - A block diagram depicting how SageMaker creates a host to serve inference requests via ML model servers.
Machine learning model servers
ML model servers are tools for serving deep learning models trained using any ML/DL framework. They can be run individually on hosts or be used via Docker images, setting up endpoints to handle RESTful requests. These requests can be for training, inference or anything else that are defined via specialized handler functions.
As shown in Figure 1, they can be considered as a layer between actual model inference and the outside world, which allows RESTful communication.
There are different model servers compatible with different ML frameworks. TensorFlow model server can be used to serve TensorFlow models and MxNet model server can work with MxNet, Gluon or Pytorch models. As we trained our WDO model via TensorFlow, we used the TensorFlow model server for this project.
Running multi-model batch transform jobs automatically
Our pipeline starts with a Zillow 3D Home™ tour. As shown in Figure 2, once a 3D Home tour is successfully completed all the panoramas are already uploaded to S3. When a tour also requires a Zillow Floor Plan™ it triggers another step function via a Cloudwatch Alarm.
This step function has several steps that have several atomic operations. First we preprocessed the input images for cleaning as well as calculating useful information. Then we ran multiple Lambdas in parallel that are responsible for the inference. These Lambdas are responsible for:
1- preparing data
2- triggering batch transform jobs
3- checking the status of these jobs
4- cleaning/filtering/mapping the batch transform results once the job completes.
Via this start-monitor-wait-monitor-end design pattern, we did not pay for the Lambda during the whole inference process, which can last for up to an hour for large image sets. Each Lambda runs in parallel with the same input image therefore additional ML models did not add to overall process time. The Lambda was written in such a way that it is agnostic of the underlying ML model. Therefore, adding a new Lambda for future ML models is trivial.
In the end we stored the predictions as JSON objects in S3. We also stored keys for these JSON objects in DynamoDB for quick and easy access to whichever service that needs it.
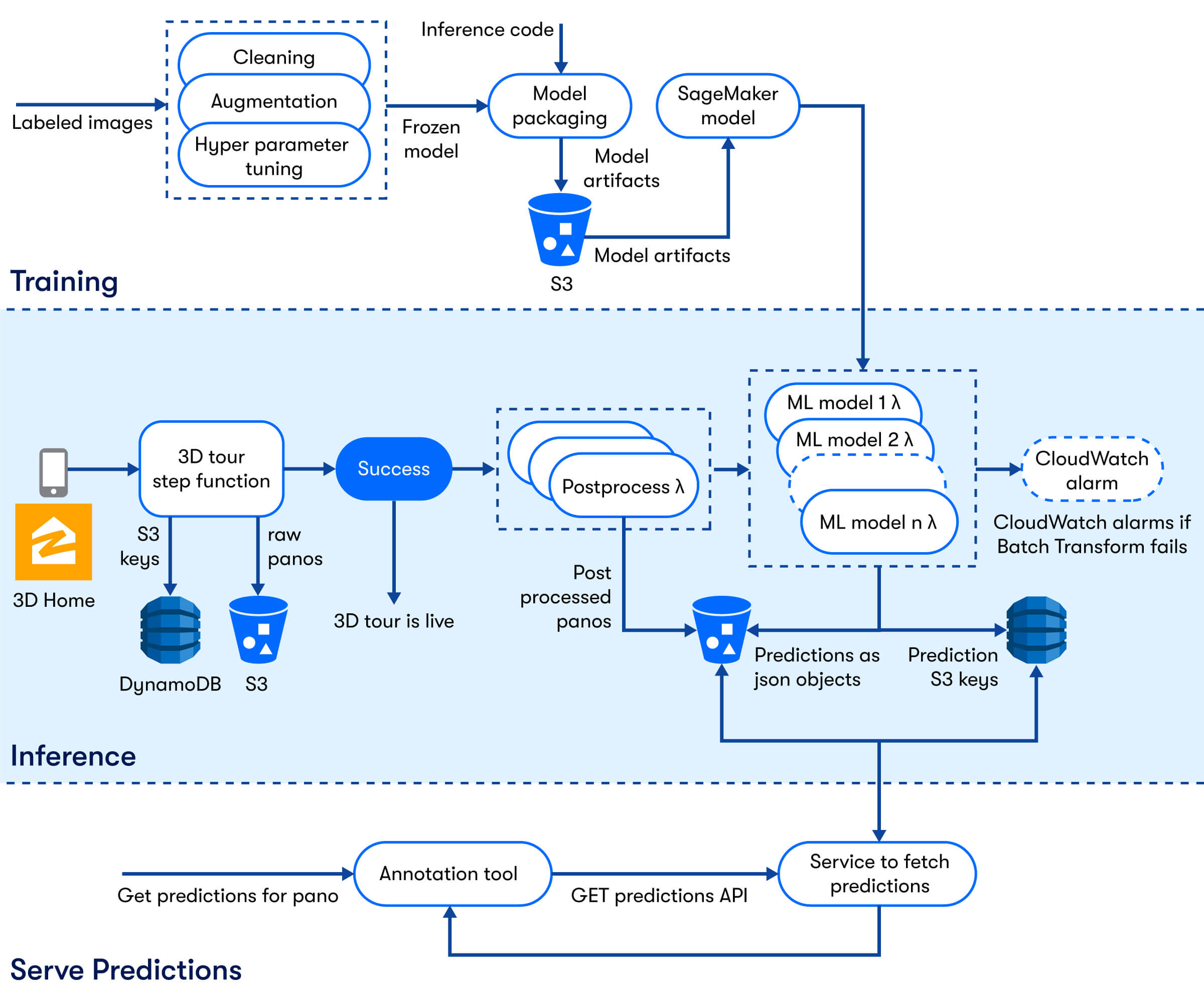 Figure 2 - A flow chart depicting our pipeline from receiving panoramas from users, running inference to serving prediction results to annotators.
Figure 2 - A flow chart depicting our pipeline from receiving panoramas from users, running inference to serving prediction results to annotators.
Conclusion and What is next?
As the demand for Zillow 3D Home and other virtual offerings increases we are realizing the benefits of investing significant time into the design and development of our infrastructure to ensure scalability. Now that we have a complete, scalable, and reliable infrastructure to serve our ML models, the next step is to design an infrastructure that would enable us to auto train models as we collect new data.
On this front, we recently moved our model artifacts into a repository with a GitLab pipeline for CI/CD as shown in Figure 3. This pipeline performs the following operations to ensure both code quality and the model performance:
- Build a custom Docker image per underlying ML framework
- Format/lint the inference code
- Run training/inference
- Check performance of the models based on predefined metrics on an image set
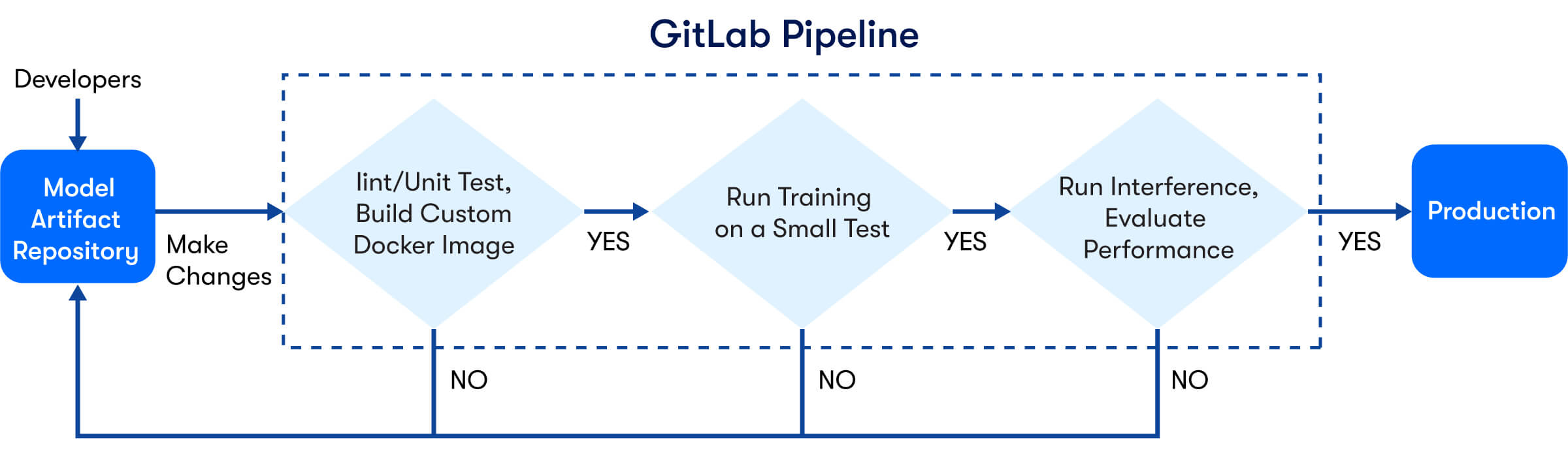 Figure 3 - A flow chart showing our model artifact repository pipeline for CI/CD.
Figure 3 - A flow chart showing our model artifact repository pipeline for CI/CD.
Scheduled retraining is still in the planning stage and we are currently investigating different frameworks such as Kubeflow and mlflow.
¹ This is based on an m5.large EC2 instance ($.096/hour) vs ml.m5.large standard SageMaker batch transform instance ($.134/hour).
² Taken from https://aws.amazon.com/ecr/pricing/
Related Articles




Sign up for Zillow news updates
Subscribe to receive daily emails for the latest Zillow news and announcements, product updates, research and more.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23111116;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M.67,84.17v-9.38L39.19,20.75v-1.12H1.34V4.67h62.64v9.38l-37.85,54.04v1.12h38.97v14.96H.67Z'/%3e%3cpath%20class='st0'%20d='M75.04,9.36c0-5.58,4.13-9.71,9.94-9.71s9.94,4.13,9.94,9.71-4.13,9.71-9.94,9.71-9.94-4.02-9.94-9.71ZM76.71,84.17V27h16.53v57.17h-16.53Z'/%3e%3cpath%20class='st0'%20d='M106.3,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M135.33,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M161.79,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM208.58,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M246.32,84.17l-17.2-57.17h16.86l11.61,40.64h1.12l10.16-40.64h16.53l10.94,40.98h1.12l11.39-40.98h16.41l-17.31,57.17h-21.55l-8.71-37.85h-1.12l-8.6,37.85h-21.66Z'/%3e%3cpath%20class='st0'%20d='M362.44,84.17V4.67h56.94v15.86h-38.3v17.53h33.5v14.51h-33.5v31.6h-18.65Z'/%3e%3cpath%20class='st0'%20d='M428.76,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.53Z'/%3e%3cpath%20class='st0'%20d='M471.64,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM518.43,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M545.11,84.17V27h16.52v8.04h1.12c4.24-6.48,9.71-9.71,16.64-9.71,12.95,0,21.55,10.05,21.55,23.78v35.06h-16.52v-32.72c0-7.03-4.02-11.95-10.72-11.95s-12.06,5.25-12.06,12.51v32.16h-16.52Z'/%3e%3cpath%20class='st0'%20d='M617.13,65.74v-26.69h-8.04v-12.06h8.49l3.24-18.09h12.95l-.11,18.09h13.06v12.06h-13.06v26.02c0,4.8,2.9,8.04,7.59,8.04,1.56,0,4.02-.33,5.92-.78v11.84c-3.24,1.12-7.93,1.79-11.17,1.79-11.5,0-18.87-8.15-18.87-20.21Z'/%3e%3cpath%20class='st0'%20d='M686.58,84.17V4.67h34.95c19.43,0,31.93,10.27,31.82,26.69,0,16.3-12.62,26.8-31.93,26.8h-16.52v26.02h-18.31ZM704.89,44.08h15.07c9.16,0,14.85-5.02,14.85-12.73s-5.81-12.62-14.85-12.62h-15.07v25.35Z'/%3e%3cpath%20class='st0'%20d='M757.71,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM804.49,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.19,6.7-15.19,16.19,6.25,16.3,15.19,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M831.17,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.52Z'/%3e%3cpath%20class='st0'%20d='M874.16,55.58c0-18.2,12.62-30.37,31.04-30.37,15.52,0,27.36,8.71,29.25,22.22l-15.41,2.01c-1.45-6.25-7.26-10.61-13.62-10.61-8.37,0-14.74,6.92-14.74,16.75s6.25,16.75,14.63,16.75c6.59,0,12.17-4.35,13.73-10.5l15.52,1.9c-2.12,13.51-14.07,22.22-29.37,22.22-18.2,0-31.04-12.28-31.04-30.37Z'/%3e%3cpath%20class='st0'%20d='M944.73,84.17V1.32h16.52v33.39h1.12c4.35-6.25,9.71-9.49,16.64-9.49,12.95,0,21.66,10.05,21.66,23.67v35.28h-16.52v-32.83c0-7.03-4.13-11.95-10.83-11.95s-12.06,5.25-12.06,12.62v32.16h-16.52Z'/%3e%3c/svg%3e)
