- Press Releases
Sustainability
Social Impact
Explore how Zillow is driving real progress toward a more affordable and accessible housing market.
- Investors
- Careers
4 min read
Saving Money with EMR Auto Scaling and Spot Instances
At Zillow, we have 100’s of batch ETL jobs that we run throughout the day. The resources required to process our data is in constant flux as our data volumes vary from hour to hour. We process a wide variety of batch data that can come in hourly or daily including user activity, push notification and a/b testing to name a few. To tackle the ebb and flow our data we turned to auto scaling with EMR.
Most of our ETL jobs use either Spark, Hive or Sqoop depending upon the task. Zillow runs a typical S3 data lake strategy. We use S3 as our HDFS and then spin up clusters for ETL, analytics and machine learning that all point to the same shared data on S3. Separating our compute/memory from storage has allowed us to move fast and provide enough computing power for all of our analytical needs.
Here is what our default EMR cluster for ETL looks like:
- 1 Master node which cannot be auto scaled
- 5 Core nodes which are mainly used for local HDFS jobs. Sqoop is our primary consumer of core nodes. Our cluster uses local disk when Sqooping data out of relational db’s and converting to Parquet (more on why we choose parquet in a future blog post). We store the data locally because the version of Sqoop we run has a bug where it cannot convert data directly to Parquet. The local HDFS is used as a staging area, then we dump the Parquet data to S3.
- 1 Task node – Perfect for compute power that needs no access to local HDFS.
Scale out rules:
- Core – we auto scale on HDFS utilization. If HDFSUtilization >= 80 for 5 minutes add nodes.
- Task – We have 3 rules related to yarn, apps pending and containers pending.
- If YARNMemoryAvailablePercentage <= 15 add nodes
- If AppsPending-Out >= 2 add nodes.
- If ContainerPending-Out >= 75 add nodes.
Our rules are slightly less aggressive with our scale in policy. We found that a slightly longer cool down of 30 to 60 minutes fits our workloads. Initially we tried a 5 minute scale in cool down, but found our clusters removing nodes and then adding them back in a few minutes later.
The one thing to watch out for is the time it takes to add additional nodes. We have seen it range from 10 minutes to 25 minutes to add additional Spot instances. If a job requires 50 nodes to process data, the job may arbitrarily wait 25 minutes to get the resources it needs.
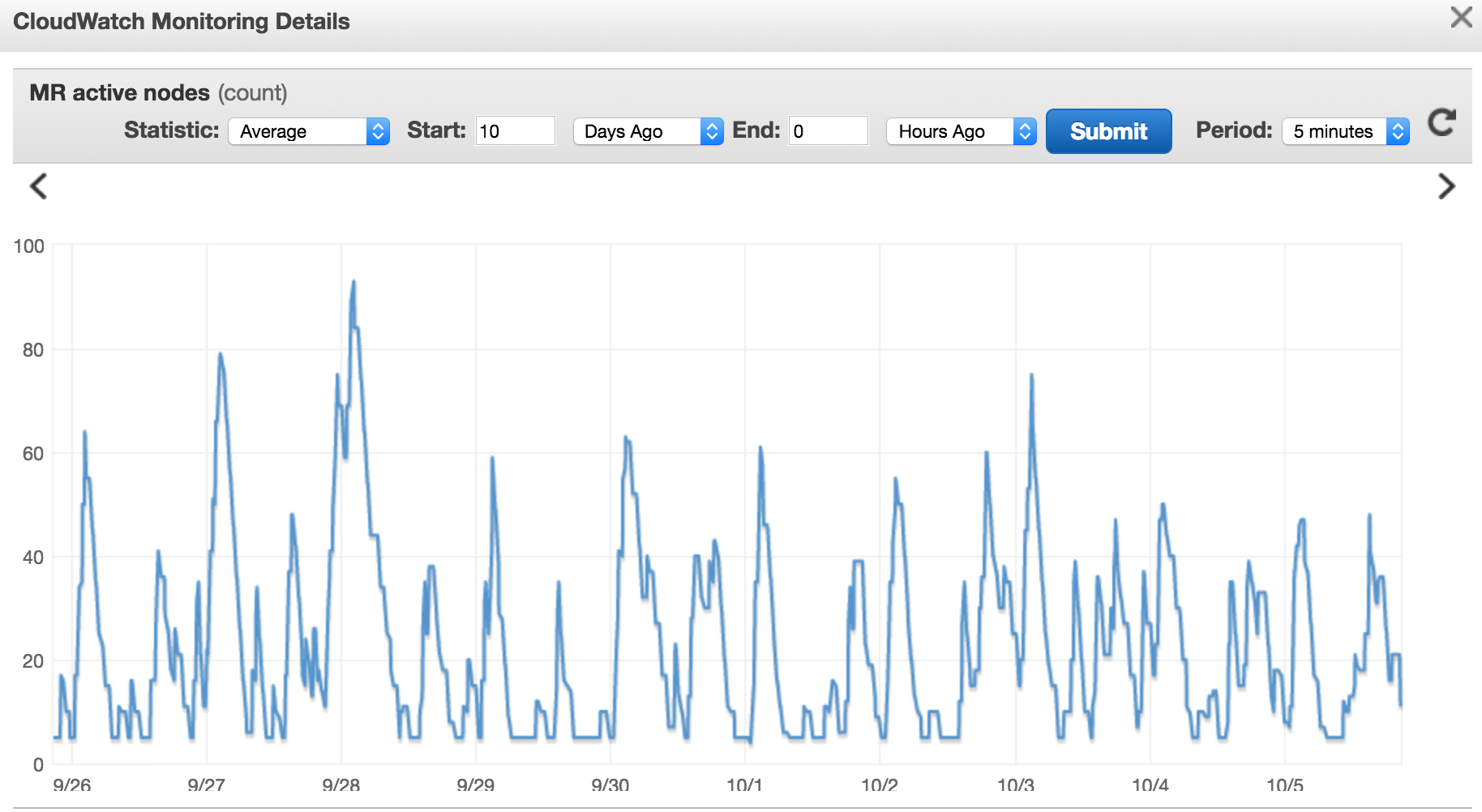
Here is our node usage over the past several days

As you can see we have several large spikes in nodes on our cluster. We sometimes receive a large batch of data that can contain up to 10tb of data. Our analysts want to query this data as soon as possible so our goal is to make it available fast, but also at a reasonable price.
The big question is how does using Spot with EMR Auto Scaling compare to reserved instance pricing for our EMR cluster?
Hourly rates:
- On demand hourly rate $0.40
- 1 year all up front hourly rate $0.231
- 3 year all up front hourly rate $0.18
Zillow’s spot blended rate over the past few months $0.125
This means we are beating the 3 year reserved hourly rate, plus we are only utilizing nodes when needed. These spot instances are not on 24/7 so we are saving significant amounts of money by only using machines when we need them. In short, we like Auto Scaling with EMR and Spot Instances!
Lessons learned
We originally set our cluster to terminate at instance hour for our scale down behavior. After a few weeks or running, we started to receive Spark errors. As noted by our colleagues at Trulia in their emr-ad-hoc-spark-development-environment blog, Spark tasks store shuffle output on the local disks. When instances are killed, our jobs started to crash. To solve this, we switched to terminate at task completion. Amazon is switching to per second pricing for EC2 so we are no longer concerned about killing resources before an hour is up.
What’s next
Spot has been working out well for us, but how long will this last? We do have some predictability with our jobs. If spot becomes more expensive than on demand we will consider scheduled reserved instances.
Right now it can take 15 – 25 minutes to spin up additional spot EC2 instances for EMR. Auto Scaling with EMR is powerful, but we would prefer that our jobs finish as fast as possible. We will investigate programmatically adding spot instances before heavy workloads hit our cluster.
Our team is constantly evaluating and playing with how many nodes to add and remove from our cluster with our auto scaling rules. We have played with 10, 15 and 20 and have settled on 15 nodes for now, but this needs further investigation to optimize job performance.
Related Articles




Sign up for Zillow news updates
Subscribe to receive daily emails for the latest Zillow news and announcements, product updates and more.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23111116;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M.67,84.17v-9.38L39.19,20.75v-1.12H1.34V4.67h62.64v9.38l-37.85,54.04v1.12h38.97v14.96H.67Z'/%3e%3cpath%20class='st0'%20d='M75.04,9.36c0-5.58,4.13-9.71,9.94-9.71s9.94,4.13,9.94,9.71-4.13,9.71-9.94,9.71-9.94-4.02-9.94-9.71ZM76.71,84.17V27h16.53v57.17h-16.53Z'/%3e%3cpath%20class='st0'%20d='M106.3,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M135.33,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M161.79,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM208.58,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M246.32,84.17l-17.2-57.17h16.86l11.61,40.64h1.12l10.16-40.64h16.53l10.94,40.98h1.12l11.39-40.98h16.41l-17.31,57.17h-21.55l-8.71-37.85h-1.12l-8.6,37.85h-21.66Z'/%3e%3cpath%20class='st0'%20d='M362.44,84.17V4.67h56.94v15.86h-38.3v17.53h33.5v14.51h-33.5v31.6h-18.65Z'/%3e%3cpath%20class='st0'%20d='M428.76,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.53Z'/%3e%3cpath%20class='st0'%20d='M471.64,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM518.43,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M545.11,84.17V27h16.52v8.04h1.12c4.24-6.48,9.71-9.71,16.64-9.71,12.95,0,21.55,10.05,21.55,23.78v35.06h-16.52v-32.72c0-7.03-4.02-11.95-10.72-11.95s-12.06,5.25-12.06,12.51v32.16h-16.52Z'/%3e%3cpath%20class='st0'%20d='M617.13,65.74v-26.69h-8.04v-12.06h8.49l3.24-18.09h12.95l-.11,18.09h13.06v12.06h-13.06v26.02c0,4.8,2.9,8.04,7.59,8.04,1.56,0,4.02-.33,5.92-.78v11.84c-3.24,1.12-7.93,1.79-11.17,1.79-11.5,0-18.87-8.15-18.87-20.21Z'/%3e%3cpath%20class='st0'%20d='M686.58,84.17V4.67h34.95c19.43,0,31.93,10.27,31.82,26.69,0,16.3-12.62,26.8-31.93,26.8h-16.52v26.02h-18.31ZM704.89,44.08h15.07c9.16,0,14.85-5.02,14.85-12.73s-5.81-12.62-14.85-12.62h-15.07v25.35Z'/%3e%3cpath%20class='st0'%20d='M757.71,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM804.49,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.19,6.7-15.19,16.19,6.25,16.3,15.19,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M831.17,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.52Z'/%3e%3cpath%20class='st0'%20d='M874.16,55.58c0-18.2,12.62-30.37,31.04-30.37,15.52,0,27.36,8.71,29.25,22.22l-15.41,2.01c-1.45-6.25-7.26-10.61-13.62-10.61-8.37,0-14.74,6.92-14.74,16.75s6.25,16.75,14.63,16.75c6.59,0,12.17-4.35,13.73-10.5l15.52,1.9c-2.12,13.51-14.07,22.22-29.37,22.22-18.2,0-31.04-12.28-31.04-30.37Z'/%3e%3cpath%20class='st0'%20d='M944.73,84.17V1.32h16.52v33.39h1.12c4.35-6.25,9.71-9.49,16.64-9.49,12.95,0,21.66,10.05,21.66,23.67v35.28h-16.52v-32.83c0-7.03-4.13-11.95-10.83-11.95s-12.06,5.25-12.06,12.62v32.16h-16.52Z'/%3e%3c/svg%3e)
