- Press Releases
Sustainability
Social Impact
Explore how Zillow is driving real progress toward a more affordable and accessible housing market.
- Investors
- Careers
25 min read
Serving Machine Learning Models Efficiently at Scale at Zillow
Zillow 2022 AI Forum
Zillow was founded with a goal of “turning on the lights'' for consumers, and it continues as a core value of the company today. Our mission is to give people the power to unlock life’s next chapter and help them find, make a winning offer on, and purchase their next home through low-friction digital solutions.
This includes putting an estimate of a home’s market value — called the Zestimate® — on every rooftop, giving people the power to make informed decisions about one of the most important transactions of their lifetime. Many Zillow features are powered by data and machine learning (ML), ranging from providing the best home recommendations, to enabling textual home insights on listings, to generating floor plans, to enabling users to perform semantic search, and to optimizing connections with our Premier Agents® partnerships — to list just a few.
As machine learning is central to so many product scenarios, it has been critical for us to invest in platform solutions. Standardized platform solutions not only provide economies of scale for infrastructure but also an easy onboarding user experience that seamlessly integrates with various internal platforms like our data and experimentation platforms as well as monitoring and alerting subsystems. The goal is to help our ML product teams iterate quickly through various stages of the machine learning development lifecycle, shipping continuously and successfully and bringing value to Zillow’s end users.
Before we talk about our solutions in this area, let’s understand the various challenges in the machine learning development lifecycle and why it is important to address them.
Machine Learning Development Lifecycle
The machine learning (model) development lifecycle, as we ML practitioners (applied scientists, data scientists, machine learning engineers) know, is a cyclic iterative process.
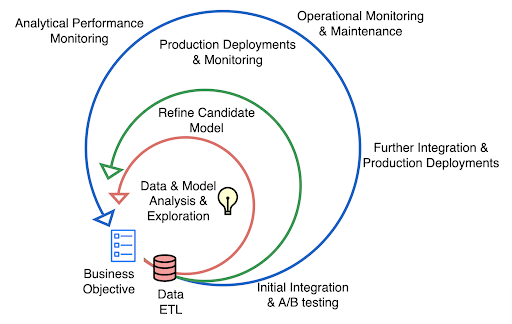 Figure 1: ML development lifecycle as inner, middle and outer loops
Figure 1: ML development lifecycle as inner, middle and outer loops
Many of us have seen some variation of the ML Lifecycle as expressed in Figure 1, and can identify with the various stages and loops presented here:
- The inner loop: Typically we start with a business objective, frame it as an ML Problem, collect requisite data, conduct exploratory data analysis (EDA) to understand it, generate relevant features, try various ideas/hypotheses, explore models, evaluate the models, and iterate. Here an ML practitioner wants to write and run quick experiments offline and fail fast to succeed sooner.
- The middle loop: Only the promising models move past the model exploration phase to the refinement phase. In this loop we iterate to find the best version of the model.
- The outer loop: After testing and evaluation, only the most promising models meeting the bar for the offline metrics that we believe align with business metrics move forward to a production deployment phase. This most often consists of deploying models (CICD) in production batch pipelines for serving cached predictions or as an online web service for real-time predictions, writing production quality code, optimizing for performance, establishing monitors and metrics for system and model health, and creating a maintainable operations pipeline.
Note that the outer loop is also represented as the biggest loop: in practice it takes the most engineering effort to get a model running in a production environment. Even with the best of tooling and a multitude of skills, a lot of friction exists to move within and between these stages and loops easily. This makes the whole process of ML development a very prolonged and strenuous one. A similar idea is conveyed in this paper.
In this blog, we are going to talk about the serving layer of our AI platform (AIP) and focus on the stages in the lifecycle when trained models are transitioning into production (outer loop), with an emphasis on how we enable our ML practitioners to easily and rapidly deploy models as online web services, serving predictions with low latencies and Zillow-scale traffic to power our business scenarios.
Challenges with deploying Machine Learning Models and What Needs to Be Solved
For an ML model to be deployed in production, we’ll need to add substantial custom business logic to serve it. This includes preprocessing the incoming requests, getting them in the format compatible with the model, performing feature extraction on the fly, potentially enriching the request with some preprocessed cached features, and — when necessary — post-processing the output. Sometimes we even need to dynamically adjust the core model scoring orchestration logic (e.g., score the request with an optional additional model based on the output of a previous model).
All of this requires a customizable serving container solution allowing for runtime environment and scoring orchestration logic customizations, rather than a prepacked, pre built model server solution. While these are popular in many industry solutions, they offer a restricted runtime environment and limited flexibility for custom business and scoring orchestration logic.
As if this wasn’t complicated enough, this all needs to take place consistently across dev and production settings, with high-quality, performant code (low query response latency), continuously integrated, continuously deployed, and monitored for any system and model metrics anomalies.
All of this often needs to integrate with other data and experimentation platforms. The problem is multi-disciplinary, requiring heavy expertise with both modeling as well as engineering in the software stack. This gives rise to what we call a “triple friction” problem:
- ML practitioners believe their skills will not be efficiently used if digging into all the engineering details — and rightly so. They should spend most of their time researching the best modeling solutions to solve a business problem. So they’d rather let an engineer take over from here to deploy the trained model for real-time serving. However, they still need to be involved in the development and deployment process to make sure that features and model behavior do not change in a different production environment.
- Engineers spend a lot of time re-writing code to have it production-ready as a web service. While they come to help with creating the service and the model deployment, they also have to learn about the model behavior, restructure and write a lot of custom code to pre-process features, make predictions with the model, post-process the output, and learn to avoid all the pitfalls, sometimes with great difficulty.
- Product teams will frequently experience a long and risky timeline. This results from the funding of engineers required every time a new model is trained and ready to go, the required ramp-up on the model behavior itself, or the unfortunate case when model behavior changes between training and production.
Without a flexible platform, this process happens over and over again with every project across various teams. All of this results in a lot of time being consumed to actually deploy models in production successfully and have an accelerated impact on the customer experience and business metrics.
Over the years of dealing with these friction points, our take here is that we need to solve the triple friction problem with a two-part centralized platform solution:
- Model server creation and deployments (user layer): Provide a model-serving platform solution with enough customizability and abstractions that ML practitioners themselves can deploy (i.e., “self-serve”) the trained model with all the business logic for real-time serving efficiently without becoming experts in web services or even having to know any of the low-level engineering details.
- Serving ML model efficiently at scale (backend): The abstracted model-serving solution should be performant enough and cover as many pitfalls as possible in the interdisciplinary area of ML serving (to be covered in the ML Serving Characteristics section later). This is where engineering talent spends most of its time to create such operationally performant systems.
In addition to solving these two problems, creating a centralized platform solution also provides economies of scale for infrastructure, standardized easy onboarding to cookie cutter projects, CICD pipelines as well as seamless integrations with data and experimentation, logging, monitoring and alerting platforms and solutions. For product teams, if the platform achieves our goals, then timelines for deployment become more predictable, and AI-powered product roadmaps become more reliable.
Industry Landscape
A lot of prominent OSS (Open-Source Software) and vendor solutions have evolved over the last couple of years to support the end-to-end machine learning lifecycle, offering a variety of strengths and capabilities. It’s important to know that these solutions have been approaching the problem from different directions — some of them are more focused on production pipelines, some more on the experimentation lifecycle.
At Zillow we have actively integrated some of these platforms and solutions, which unlock huge capabilities for us without having to reinvent the wheel. Nonetheless, we invest heavily in making such third-party solutions operational at scale, compatible with our Zillow ecosystem and accessible to our internal users.
Focusing on serving ML models, some existing solutions do implement the requirements of our two-part platform to a certain extent, but not sufficiently, especially when it comes to ease of use by ML practitioners. For example, for model server creation and deployment, the existing solutions provide ways to abstract the web server creation and deployment process through configuration files, libraries and/or CLI tools. However, the end-to-end experience generally still requires developing a good level of software engineering expertise with low-level system concepts exposed (such as the setting and serialization of environment variables).
Deployments and the overall experience are primarily built for engineers. Sometimes there are also unnecessary restrictions, such as when the model and serving logic need to be packed in a special format. Many provide pre-built servers without really solving the problem that a lot of custom code and dependencies are still required with real life models. Overall, the model server creation and deployment experience still requires a steep engineer learning curve leading to a lot of conceptual overhead for ML practitioners.
For scale and performance, most industry solutions do promise a good availability and request success rate. However, our load testing results show that the latency, especially the long-tail P90/P95, can be compromised due to the special characteristics of ML serving.
Our integration with OSS
Our AI platform team's vision is to create a cohesive end-to-end ML platform for Zillow that provides deep integration with our business and infrastructure while leveraging open source ML platform solutions and tools when appropriate.
Having done a thorough evaluation and analysis around requirements and what works best with our engineering ecosystem, operations, goals and vision, we have integrated with parts of the prominent Open Source Project Kubeflow which offers a very powerful toolkit for running ML Workloads on Kubernetes. We have also actively integrated Knative and KServe as our model serving backend. More on this coming in the later section on our Technical stack.
Over our development and customer feedback cycles, we also realized the potential of Metaflow and appreciated how our design philosophies were so similar that successful projects are delivered when ML practitioners can build, improve, operate end-to-end workflows independently, focusing on data science and less on engineering. We really liked the Pythonic syntax, the concept of steps, flows and the ease of using decorators and have adopted it for our batch workflows, with our own Orchestration layer zillow-metaflow.
Note that these OSS solutions offer a good starting point, though an extensive amount of engineering is required to make them operations-ready, adapt to Zillow infrastructure, meet our customers’ SLAs, and more importantly to create a “paved path” that reduces the above-mentioned frictions to levels that help with easy transitions through the ML lifecycle stages to production deployment. We will be writing separate blog posts on our integrations with these OSS solutions soon and highly recommend exploring these technologies.
Now, let’s take a look at the applications of these solutions as they apply to the problem of deploying ML models as services.
ML Model as a Service
What does it mean when we say model as a service? Typically that’s a machine learning model (or various versions of it) deployed as a web service. This web service could be either interacting with various client-side applications for real time predictions (as shown in Figure 2 by the “WWW” API entrypoint), or it could be a step in a streaming pipeline, receiving streaming data from (for example) Kafka streams and sending predictions to an output stream in a near real-time manner (as shown in Figure 2 by the “Streaming Application” flow).
In both configurations, they run on top of a model-serving infrastructure, which connects with a number of data, feature, model and metadata stores to fetch relevant artifacts, A/B testing platforms for controlling model versions and treatments (and evaluating performance), as well as monitoring and alerting solutions for system and model health as shown at the top of Figure 2.
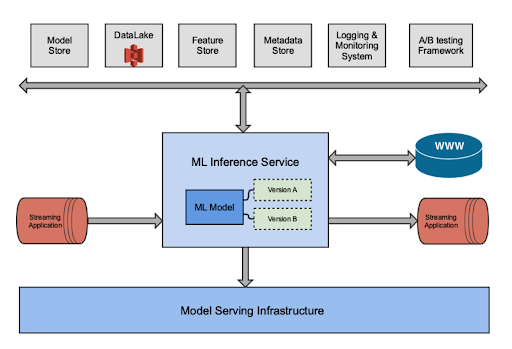 Figure 2: Models as a Service
Figure 2: Models as a Service
The core concept behind “ML model as a service” is to abstract away all the “peripheral” components (i.e., all components in Figure 2 other than “ML Model”) from ML practitioners so that they can simply focus on the ML model itself, and deploy it directly as a service at ease. To enable such, we’ll need the aforementioned two-part centralized platform solution:
-
- Model server creation and deployments (User layer)
- Serving ML model efficiently at scale (Backend layer)
Now let’s dig deeper into these two layers with our findings and solutions.
User Layer - Model Server Creation and Deployments
Service as Online flow
For a solution to be successful here, the layer has to be easy to use for an ML practitioner and should have a minimal learning curve.
To provide such an interface, we investigated what the user layer or experience should look like. Talking to our ML practitioners and understanding their development style and patterns, we were intrigued by the flow paradigm and how often this is used in batch workflows.
In simple terms, a flow is a natural DAG (Directed Acyclic Graph) representation to mimic the philosophy of steps performing tasks in a machine learning or big data project. In fact, the concept of flow is used by many ML and data engineering platforms and frameworks such as Kubeflow, zillow-metaflow, mlflow and Airflow, primarily in a batch (offline jobs) context.
But if we look carefully, the same flow paradigm could also be applied to an online service serving machine learning models as well.
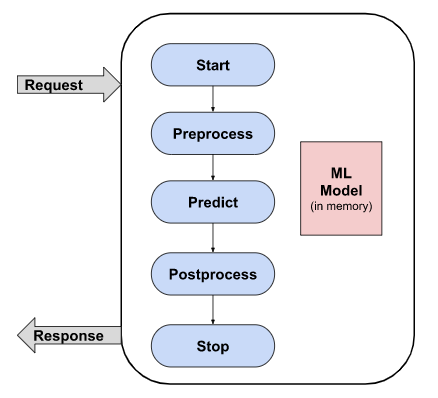
Figure 3: Service as Online flow
As seen in Figure 3, a model deployed as an online machine learning prediction service is essentially a flow containing steps that include but are not limited to starting to process a request, preprocessing the data received in the request and transforming it into acceptable format/features for the model, predicting using the deployed ML model, and postprocessing and converting the output prediction to a client agreed format.
In practice, one should be able to define and perform any step as it sees fit (e.g., the flow can potentially branch out to enable concurrent data preprocessing). Of course the load model step (which loads the ML model in memory) is universal and the loaded ML model should be active for the lifetime of the service.
This view really helped us come up with the “service as online flow” concept and create a user-friendly abstraction layer. Since Python is the preferred language for applied science at Zillow (and in the broader AI/ML community), we are doubling down with a Pythonic flow syntax to define our online serving flows.
Since we are already actively integrated with Metaflow (our version of metaflow: zillow-metaflow) for defining our batch workflows, using similar syntax has helped to keep the learning curve not only very reasonable but seamless. As a consequence, our users can express their online service code as flows in pure simple Python without requiring a deeper knowledge or in fact any knowledge of web service concepts and still deploy their models as highly performant web services (explained more in the Backend section).
Service Code
Here’s an example in which we put the offline batch flow and online service flow side by side to show what the user experience looks like:

Figure 4: On the left is an example of a “HelloFlow” offline flow or a batch training and scoring workflow. On the right, an online service flow for prediction.
The similarities in defining a flow between offline and online versions are by design. Significantly, where and how the steps mentioned in the code are orchestrated is completely abstracted from our end users. The online flow file on the right is all a user needs to define a complete service. Now let’s take a closer look at the online flow:
- OnlineFlowSpec implements the core flow concept, containing the DAG with custom service logic defined through @step decorators and self.next. The power of such a DAG representation is it’s extensible and can be more than linear (e.g., it’s possible to define a DAG with multiple branches for async processing as needed).
- Flow class decorators (e.g. online_service, online_resources, autoscaling, etc.) control the behavior of services from an engineering perspective, such as the endpoint URL, resource limit and auto-scaling behavior. Such Pythonic abstraction helps ML practitioners define the service in declarative fashion, all within the same online flow file.
- Flow parameters (Parameter) is a Pythonic abstraction on runtime configurations needed for web services, over the vanilla environment variables. For example, one can simply use `self.score_param` when needed, rather than `os.getenv(“SCORE_PARAM”)` which has a low-level system concept as well as serialization logic exposed.
- The load function executes the warmup task needed before serving the traffic, such as downloading and loading models and other artifacts, as well as custom business warmup logic.
- We abstract away the low-level HTTP read and write formatting concept through the self.input and self.output in online flow, which provides convenient and efficient transformation against Pandas DataFrame (something which our Scientists love).
All these online flow abstractions are provided by the Serving SDK (Python module aip_serving_sdk). The Serving SDK also wraps a performant web server implementation (explained in the backend section), but for our users they don’t need to be worried about that at all. In the future we also plan to provide seamless integration with data, experimentation, monitoring and alerts systems leveraging the same syntax.
Automatic Service Deployments
After the service is defined through the online flow, the offline flow will take the responsibility for service deployment, as shown in the example code using the “online_publish” function. When it executes, the “online_publish” function deploys the targeted online flow file as a real-time service. The artifact and metadata of the service deployment offline flow will also be available in the online flow’s load function through the “base_run” pointer, so that loading models as well as any other artifacts in the online flow for serving can be as easy and elegant as a one-line pointer-style call.
Such a pattern also helps naturally with the critical model retraining and refresh story, something we call Automatic Model Refreshes: for models that benefit from scheduled continuous retraining, they can be redeployed as services as soon as they get trained and evaluated in the offline flows. Note that our overall projects for Offline and Online do leverage GitLab™ and GitLab CICD overall for making all this experience happen.
All of these elements help make the model server creation and deployment story a straightforward, seamless and efficient experience. All the concepts involved here are made to be intuitive and Pythonic, without introducing much cognitive burden and conceptual overhead. The overhead is further reduced through a very similar syntax shared between offline and online flows. Furthermore, given that offline and online flow live in the same repository sharing the same container environment, there’s less of a hassle to reuse the code and align the runtime environment between model development and model deployment.
Internally, we’ve seen that the patterns of “ML model as a service” and “service as online flow” have helped us create model servers as well as deploy them efficiently. We have feedback from ML practitioners that this pattern has helped save at least 60% of the time that was spent on infrastructure type work before, and we are continuing to improve the solution to make it even better over time.
For our ML practitioners, this is all they have to do to deploy a model as a service to power core Zillow user experiences.
Backend - Serving ML Model Efficiently at Scale
Behind the smooth user experience of model server creation and deployment is the underlying backend to make the model serving solution perform efficiently at scale in real production settings. We abstract this area from our ML practitioner end users completely so that they can focus on data and modeling, but this area is extremely important and is where our AI platform engineers spend a lot of time, aiming to provide an operationally excellent system.
ML Serving Characteristics
It’s worthwhile to explore what makes ML serving different from regular web services:
- CPU-bound: ML serving is mostly CPU (sometimes GPU)-bound, while regular web services are usually IO-bound. This means:
- Under the same resource boundary, each ML server replica can’t have as many parallel worker processes as that of regular web services. The benefit of asynchronous I/O can also be less significant for ML serving.
- The system level overhead, such as context switching among processes and CPU throttling for guaranteed resource allocation, matters more for ML serving and can affect latency performance more drastically than that of regular web services.
- Varying request workloads: The workload for each request could vary a lot for ML serving especially with custom business logic. For example, some inference requests could be fulfilled by lightweight lookups, while others may require CPU (or GPU) to run at full capacity.
- This makes CPU utilization-based auto-scaling policy less effective, which could result in many false-positives and false negatives in autoscaling decisions.
- Heavy request effect: Depending on the model scoring and business logic, there could be heavy inference requests that could take a rather long time (e.g., close to the default 1-minute request timeout) to get scored. This brings side-effects including:
- Health/Liveness/Readiness probe targeting busy ML server replica could generate false-positive alarms if the server replica can’t get to the probe request in its busy backlog queue before the request timeout. In such cases the serving replica could get terminated mistakenly.
- Excessive requests that get routed prematurely to a busy server replica could end up waiting with timeout.
- Serverless: ML serving costs are typically much higher due to the large resource footprint, thus it would be beneficial costwise to enable serverless (i.e., scale to zero) support for certain ML serving use cases with clear off-peak traffic patterns.
Such unique characteristics have made ML serving an interdisciplinary area that many performant web serving architectures for regular web services do not perform well, essentially due to the fundamental difference between CPU-bound workloads and IO-bound workloads.
To tackle the unique characteristics of ML serving, a good first step is to introduce a request or event based auto-scaling mechanism to autoscale serving replicas based on the concurrency of in-flight traffic and the number of concurrent requests each replica could handle. This mechanism helps solve No. 2 (varying request workloads) and No. 4 (serverless) as now we can autoscale based on traffic itself rather than an indirect measure of traffic (e.g., CPU utilization).
However, this won’t help with No. 1 (CPU-bound) and No. 3 (heavy request effect). Especially as perfect load balancing is impossible, inevitably there could be surplus requests hitting the serving replica waiting to be fulfilled in the replica's backlog queue and contributing to the context switch overhead. A long backlog queue itself could also bring in all the heavy request effects.
Solving these remaining pain points would require a strong opinion in the network architecture and data flow between the load balancer and serving replicas. Ideally we’d need a middle layer in between to buffer the surplus requests and only dispatch them to the serving replicas with capacity. If smart enough, that middle layer could also proxy the work of probes to offload some burden from the serving replicas.
Our Technical Stack
All these requirements may seem overwhelming, but actually it turns out that there’s already a mature open-source solution handling all the requirements gracefully – Knative Serving. Built on top of Kubernetes and Istio, Knative Serving offers:
- Centralized autoscaler component enabling request-based autoscaling (e.g., concurrency or request per second) and serverless (scale to zero).
- Centralized activator component for smart load balancing (e.g., buffer the surplus requests and only dispatch to serving replicas with capacity on its best effort under a distributed environment).
- Queue-proxy sidecar containers, to be attached to each model server container to form a complete serving replica pod. Queue-proxy implements a proxy on probes and when configured properly (e.g., using TCP probe instead of HTTP probe), the application layer of the main model server container won’t get interrupted. Queue-proxy can also behave as an additional buffer layer to hold the surplus requests before the main serving container has capacity, so that the main serving container won’t get interrupted when it’s running hard.
- Many features in general traffic management such as traffic splitting and gradual rollout.
With Knative helping solve most but not all of the pain points in ML serving efficiency (due to the complexities of a distributed computing environment), we are further utilizing KServe to complete the ML serving picture. KServe offers a performant base custom model server that we can further optimize upon, a great abstraction on top of Knative, as well as lots of critical features for ML serving such as request batching enabling batch optimization and separated transformer for pre/post-processing.
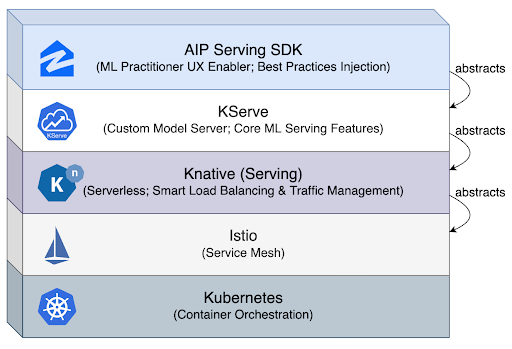
Figure 5: High-level architecture of the Zillow Group AIP serving stack
Leveraging these open source solutions and optimizing for performance internally based on our insights around ML characteristics, we manage to boost the ML serving performance in real production scenarios, compared to alternative vendor solutions.
The performance difference varies by specific models and settings, but generally we are seeing a 20%-40% improvement in terms of p50 and long-tail latencies. This in turn also contributes to 20%-80% less cost to serve the same traffic, combined with other internal compute and resource level optimizations.
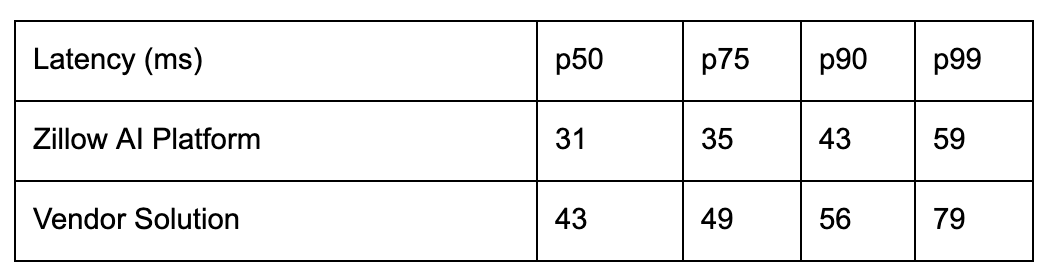 Table 1. Performance comparison of a production grade model
Table 1. Performance comparison of a production grade model
Lastly, with the Zillow’s AIP Serving SDK on top of the stack, we hide these advanced Knative and Kubernetes concepts from our end users and only provide them with the online flow user layer that we have implemented. The deployments are taken care of by our established GitLab CICD pipelines as well as automatic redeployments on recurring trained models with “online_publish” functionality that we have introduced.
Serving SDK also nicely integrates with the Zillows tools and ecosystem on monitoring and observability with platforms like Datadog and Splunk. We plan to introduce more and more abstractions for our users related to data access as well as running seamless A/B experiments, ultimately helping them focus only on the core modeling details and metrics and abstract away all the complexities that come from cross-platform integrations.
We are privileged to be in this open source era when there are plenty of OSS including Knative and KServe empowering ML serving, whether being a primary goal (for KServe) or as a byproduct (Knative’s primary goal is to enable serverless and event driven applications, which at first glance seems to be nothing especially relevant to ML serving but turns out to be of great help).
However, we can only be aware of and fully utilize these benefits when we know the whys and hows of the ML Serving Characteristics. We hope this blog can help turn on the lights of this less visited ML serving performance facet when it comes to comparison of ML serving solutions, especially for large-scale efficient production-grade serving.
Conclusion and What’s Next?
With a combination of our easy-to-use user layer enabling server creation and deployments and a very scalable and performant backend layer, we are able to provide our users a self-service serving platform, significantly reducing or even eliminating the friction between various stages in the ML lifecycle. Our vision is to make it so simple that every machine learning model can be deployed in a self-service manner, easily and rapidly empowering our ML practitioners to enable our key business scenarios.
And this is only the beginning of the story as we continue to improve the ML efficiency for both humans and machines. We have started on some interesting paths to provide more abstractions with respect to data layer access, feature extractions and enhanced observability in model performance metrics, in addition to service system metrics. We are excited about our OSS engagements and working with an active community of world-class developers to build our solutions — and we look forward to contributing in this space as well.
We are committed to continuity in improving both our user experience as well as computational efficiency and are happy to connect and collaborate as we continue to learn.
GITLAB is a trademark of GitLab Inc. in the United States and other countries and regions. All product names, logos, and brands are property of their respective owners. All company, product and service names used in this website are for identification purposes only. Use of these names, logos, and brands does not imply endorsement.
Footnotes
Related Articles




Sign up for Zillow news updates
Subscribe to receive daily emails for the latest Zillow news and announcements, product updates and more.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23111116;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M.67,84.17v-9.38L39.19,20.75v-1.12H1.34V4.67h62.64v9.38l-37.85,54.04v1.12h38.97v14.96H.67Z'/%3e%3cpath%20class='st0'%20d='M75.04,9.36c0-5.58,4.13-9.71,9.94-9.71s9.94,4.13,9.94,9.71-4.13,9.71-9.94,9.71-9.94-4.02-9.94-9.71ZM76.71,84.17V27h16.53v57.17h-16.53Z'/%3e%3cpath%20class='st0'%20d='M106.3,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M135.33,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M161.79,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM208.58,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M246.32,84.17l-17.2-57.17h16.86l11.61,40.64h1.12l10.16-40.64h16.53l10.94,40.98h1.12l11.39-40.98h16.41l-17.31,57.17h-21.55l-8.71-37.85h-1.12l-8.6,37.85h-21.66Z'/%3e%3cpath%20class='st0'%20d='M362.44,84.17V4.67h56.94v15.86h-38.3v17.53h33.5v14.51h-33.5v31.6h-18.65Z'/%3e%3cpath%20class='st0'%20d='M428.76,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.53Z'/%3e%3cpath%20class='st0'%20d='M471.64,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM518.43,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M545.11,84.17V27h16.52v8.04h1.12c4.24-6.48,9.71-9.71,16.64-9.71,12.95,0,21.55,10.05,21.55,23.78v35.06h-16.52v-32.72c0-7.03-4.02-11.95-10.72-11.95s-12.06,5.25-12.06,12.51v32.16h-16.52Z'/%3e%3cpath%20class='st0'%20d='M617.13,65.74v-26.69h-8.04v-12.06h8.49l3.24-18.09h12.95l-.11,18.09h13.06v12.06h-13.06v26.02c0,4.8,2.9,8.04,7.59,8.04,1.56,0,4.02-.33,5.92-.78v11.84c-3.24,1.12-7.93,1.79-11.17,1.79-11.5,0-18.87-8.15-18.87-20.21Z'/%3e%3cpath%20class='st0'%20d='M686.58,84.17V4.67h34.95c19.43,0,31.93,10.27,31.82,26.69,0,16.3-12.62,26.8-31.93,26.8h-16.52v26.02h-18.31ZM704.89,44.08h15.07c9.16,0,14.85-5.02,14.85-12.73s-5.81-12.62-14.85-12.62h-15.07v25.35Z'/%3e%3cpath%20class='st0'%20d='M757.71,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM804.49,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.19,6.7-15.19,16.19,6.25,16.3,15.19,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M831.17,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.52Z'/%3e%3cpath%20class='st0'%20d='M874.16,55.58c0-18.2,12.62-30.37,31.04-30.37,15.52,0,27.36,8.71,29.25,22.22l-15.41,2.01c-1.45-6.25-7.26-10.61-13.62-10.61-8.37,0-14.74,6.92-14.74,16.75s6.25,16.75,14.63,16.75c6.59,0,12.17-4.35,13.73-10.5l15.52,1.9c-2.12,13.51-14.07,22.22-29.37,22.22-18.2,0-31.04-12.28-31.04-30.37Z'/%3e%3cpath%20class='st0'%20d='M944.73,84.17V1.32h16.52v33.39h1.12c4.35-6.25,9.71-9.49,16.64-9.49,12.95,0,21.66,10.05,21.66,23.67v35.28h-16.52v-32.83c0-7.03-4.13-11.95-10.83-11.95s-12.06,5.25-12.06,12.62v32.16h-16.52Z'/%3e%3c/svg%3e)
