Splunk at Zillow
Seattle Splunk User Group Hosted at Zillow
The Seattle Splunk user group was recently hosted at the Zillow HQ in Seattle. The Splunk user group is community-built and run, and is a platform for sharing knowledge and real-life examples while connecting with other Splunkers. The presenters for the event, Bernie Macias and Jerome Ibanes, support Splunk at Zillow and shared on topics that they have been working on internally. The topics embody some of the crucial elements of our Splunk projects that we thought would be relevant to others looking to harness the power of Splunk in their organizations. The evening had substantial Splunk representation from the local Seattle Splunk office with folks representing engineering, sales and support attending.
The topics for the evening were “Extending Splunk Through the Use of External Commands” and “Finding the Needle in the Haystack.”
You can watch the entirety of the presentation:

Below Jerome and Bernie provide a summary, including additional details and supporting links that recap their presentations.
“Extending Splunk Through the Use of External Commands”
Getting Started
There are scenarios where it would be nice to expose data in the Spunk interface without Splunk actually ingesting the underlying data and storing it within the Splunk indexers. The data source could be any external system that stores configuration data such as system state. What is important is to expose the current state, analyze, and include in query results.
During our presentation we demonstrated extending Splunk by creating an external command which was exposed through the Splunk Query Language allowing the Splunk user to query the F5 BigIp Load-balancer configuration. This is where we came up with the idea of creating the command “f5query”, which would allow users to request F5 information and merge it with other datasets.
How does this work?
The command relies on suds, bigsuds, and Splunk’s SDK (https://github.com/splunk/splunk-sdk-python), which handles the command arguments and dispatching of code. The only difficult task is working with the API and returned dataset, which could be a csv, xml, json, etc; luckily the F5 iControl api returns list and dictionary objects.
At the core of the f5query command is a simple Python class —which has a number of methods to retrieve pool, statuses, members, destinations and statistics — and joins all results into a single dataset. Each item in the data set is then yielded as a json object to the Splunk search head. Normally each method would be ran serially to the F5, which can be slow, so to improve performance we added multithreading to allow requests to the F5 run concurrently. This abstracts much most of the complexity from the user.
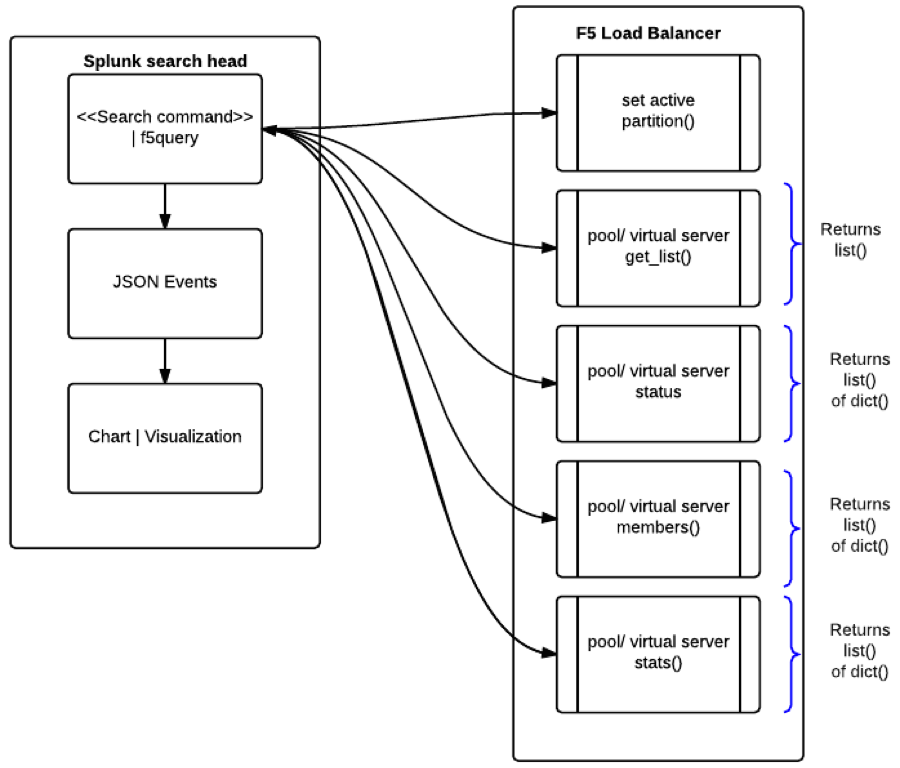

To use the command a user simply enters
"| f5Query vserver='/Common/trans.mycompany_86_vs,/Common/post.mycompany_81_vs' device='f5.com'"
This command connects to the F5 requesting information on the virtual servers from the device f5.com. To retrieve stats a user simply adds getStats=True. By default the command sets the partition to ‘common’, which is the default partition on most F5 LB devices, can be change with the partition argument.
You can download the app from Splunkbase here
Another example of querying external data is found in our custom search command called “Getsnow”. This command was created so that a Splunk user can create a custom to post and pull results from the ServiceNow API. Again, by using the external command in this manor the data is not ingested in Splunk, however it makes it available for more complex Splunk queries.
You can download the app from Splunkbase here
In the End
Extending Splunk has allowed us to surface information to users easily. Going a step further, space can be made into portal to view other information internal or external. To view our other Splunk apps and extensions visit:
- F5query – https://github.com/httpstergeek/f5query
- carbonmine – https://github.com/httpstergeek/carbonmine
- getsnow – https://github.com/httpstergeek/getsnow
Finding the Needle in the Haystack
“In a natural thermodynamic process, there is an increase in the sum of the entropies of the participating systems.”
– Second law of thermodynamics.
When shipping software at Internet speed, it’s not uncommon that processes observe a behavior similar to the first part of the second law of thermodynamics, in which errors (similarly to entropy) only increase with time. Given a few years, services or applications (here, the presentation servers) report over 4 million errors per day; most of them being unactionable and contribute to the daily noise of acceptable errors. The volume is so high that it becomes quite impossible to differentiate “real” errors from what should probably be considered less important. Needless to say, the entire capacity to monitor a high-availability website becomes impaired when the volume of false positives reaches such thresholds. This behavior isn’t uncommon, and is usually magnified on middle-ware services, where errors are not (usually) directly visible from a public facing service; but consequences are usually greater (latency increase, drop in duration of user sessions, etc.)
The challenge: Ranking errors by severity as opposed to volume would allow us to focus on primary, user-impacting issues and identify which errors which can be silenced.
The numbers: One service presentation raises over 4 million errors a day, accounting for 20,000 different types of errors; monitoring of the health of this service is solely done on the volume of errors, not even their contents.
We have taken different approaches to this problem: The first was to measure the distribution of errors based on their punctuation, and alert should a “type” of error deviate from its expected range. However this approach failed due to the fact that shipping a service or application modifies the distribution of said errors. This approach is also unpractical for test and stress environments where no process can “learn” what is expected noise and what is critical and should be actioned upon; also, this method doesn’t account for seasonality. Therefore, we focused on building a self-learning engine.
The severity of an error can be defined by the impact it makes on a customer, whereas this is a http 400 or 500 or higher latency. So I’ve started to collect those metrics: I called them the Factor X— a representation of the user experience (accounting for number of apache errors, bad urls, high latency, etc.) — and sampled it every second. The higher the value, the most degrading the user experience is.
Similarly, every service error is placed (or rather, a description of its punctuation) in a multi-billion row in-memory database. Once per minute severity is calculated for each individual error based on their elevation of the Factor X at the time (minus 1 second/plus 29 seconds) each identical type of error happened. Such as this (for clarity, we’ll consider that this error happened only a few times):
Error: “fell back to property pogo subdivision assignment when mapping a community” and a baseline Factor X of 49.5.
Factor X (average -1/+29 seconds relative to Event time)
Because this error doesn’t elevate the Factor X baseline significantly, we can rule that its severity is low.
| Error datetime | Factor X (average -1/+29 seconds relative to Event time) |
| 2015-02-21T06:01:34.105-0800 | 42 |
| 2015-02-22T13:51:44.309-0800 | 51 |
| 2015-02-22T13:53:14.111-0800 | 53 |
| 2015-02-22T13:57:31.714-0800 | 50 |
| 2015-02-25T13:59:11.891-0800 | 49 |
Let’s consider another scenario:
Error: “com.zillow.service.search.SearchException: Search came back with an ambiguous region match quality, but no region results” and a baseline Factor X of 49.5.
| Error datetime | Factor X (average -1/+29 seconds relative to Event time) |
| 2015-02-25T13:52:59.672-0800 | 145 |
| 2015-02-25T13:52:07.414-0800 | 148 |
| 2015-02-25T13:53:01.112-0800 | 149 |
| 2015-02-25T13:58:07.562-0800 | 151 |
| 2015-02-25T13:59:16.699-0800 | 149 |
Here, because the Factor X is elevated ONLY during the time window around the occurrence of this specific error, we can deduce that this error is of higher severity.
Because the severity is calculated on the mathematical average of Factor X, any fluke (should a critical error happen at the time of a non-critical error) is silenced. This inherent advantage of calculating the Factor X based on external metrics combined with the fact that the distribution of each individual error is inversely proportional to their severity allows us to build a model and report severity with a high confidence level.
This is better illustrated on a bubble chart, where ranking is done using wilson scoring ( http://www.evanmiller.org/how-not-to-sort-by-average-rating.html )
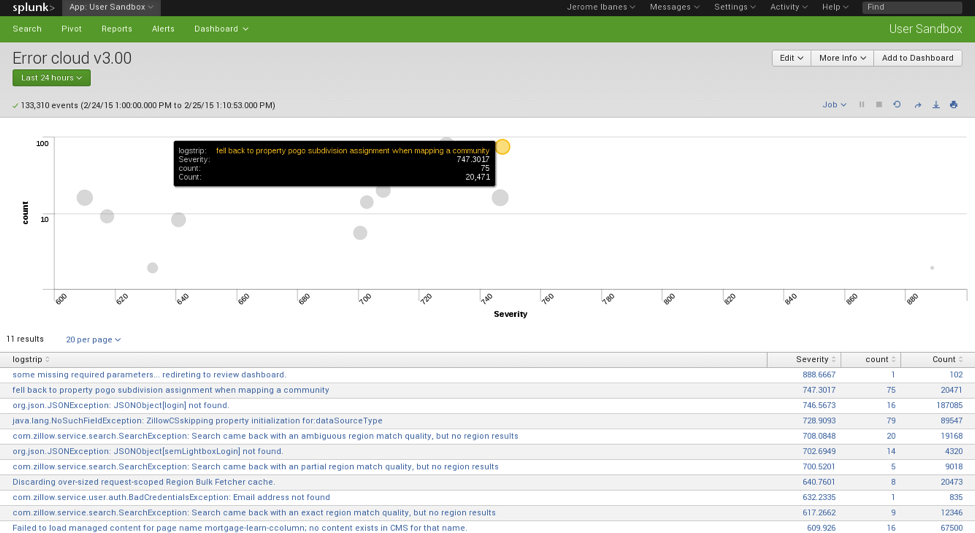

Given an average baseline of 600, errors shown above increase the Factor X at the window of time of their appearance; because most events happened several hundred times, the confidence level of their severity is high. The first column of count is the number of times this error happened in the past 24-hour window, and the second column of count is the number of times this error happened since its first occurrence.
The algorithm behind this ranking is a pivot operation, in which I perform a window join of all the times each individual error happened (20,000 different types) and average the Factor X, which illustrates their severity. Because this is an ongoing process, each lookup (in Splunk) only takes a few seconds; this implies that one could list, in seconds, the most critical errors that are impacting our customers the most.
Why this works?
The Factor X metric is agnostic to the state of a server (shutdown, up, being serviced, out of a pool) because it’s measured from the customer directly. If software is being released, the server is out of the pool, so the Factor X metric isn’t impacted.
Wrapping it up
Zillow was honored to host the spring Seattle Splunk user group. By bringing together like-minded individuals and sharing how we are solving real world challenges provides cultivates a vibrant tech community. As stated above, the apps are available for download from Splunkbase and we welcome your comments and contributions.