Zillow Transitions to Streaming Data Architecture
Zillow’s data science & engineering team receives immense amounts of real estate data every second from sources such as public records, user/agent feeds and Multiple Listing Services. Traditionally, this data has been stored in Microsoft’s SQL Server and processed using in-house caching techniques. As part of a fast-growing tech company with enormous amounts of data and a need to solve hard problems — like real-time Zestimates®, business intelligence and personalization — we are moving toward a scalable, highly available and fault-tolerant streaming data architecture which could enable us to process large volumes of varied data in real time.
Shifting Approaches: Data as Event Streams
Viewing data as an event stream is crucial to the working of a streaming architecture. On our team, we have changed our approach from thinking about database tables to event streams. For example, the selling of a house is a transactional event, and a record of that transaction and many other such transactions functions as continuously flowing data in the transactions event stream. Similar examples include a for-sale listings stream, rental listings stream, foreclosures stream, loans stream and many others. The idea is fascinating, and the exciting challenge has been to actually implement the streaming data architecture, fit new technology stacks into the existing ones and generate streams for systems that were never designed to support them.
Our Streaming Data Platform
Our choice for the streaming data platform has been Amazon Kinesis Firehose: It helps us do real-time analytics and load massive volumes of streaming data into Amazon S3, and it’s an auto-managed service. We use Amazon S3 as our permanent persistent data storage solution and have created a hub for all data streams called Zillow Data Lake. Our Data Lake stores all historical data so it can be consumed by our data processing engine, Apache Spark, to run our complex machine learning algorithms. It can also be used by other teams at Zillow Group, including Premier Agent, StreetEasy, Trulia and dotloop.
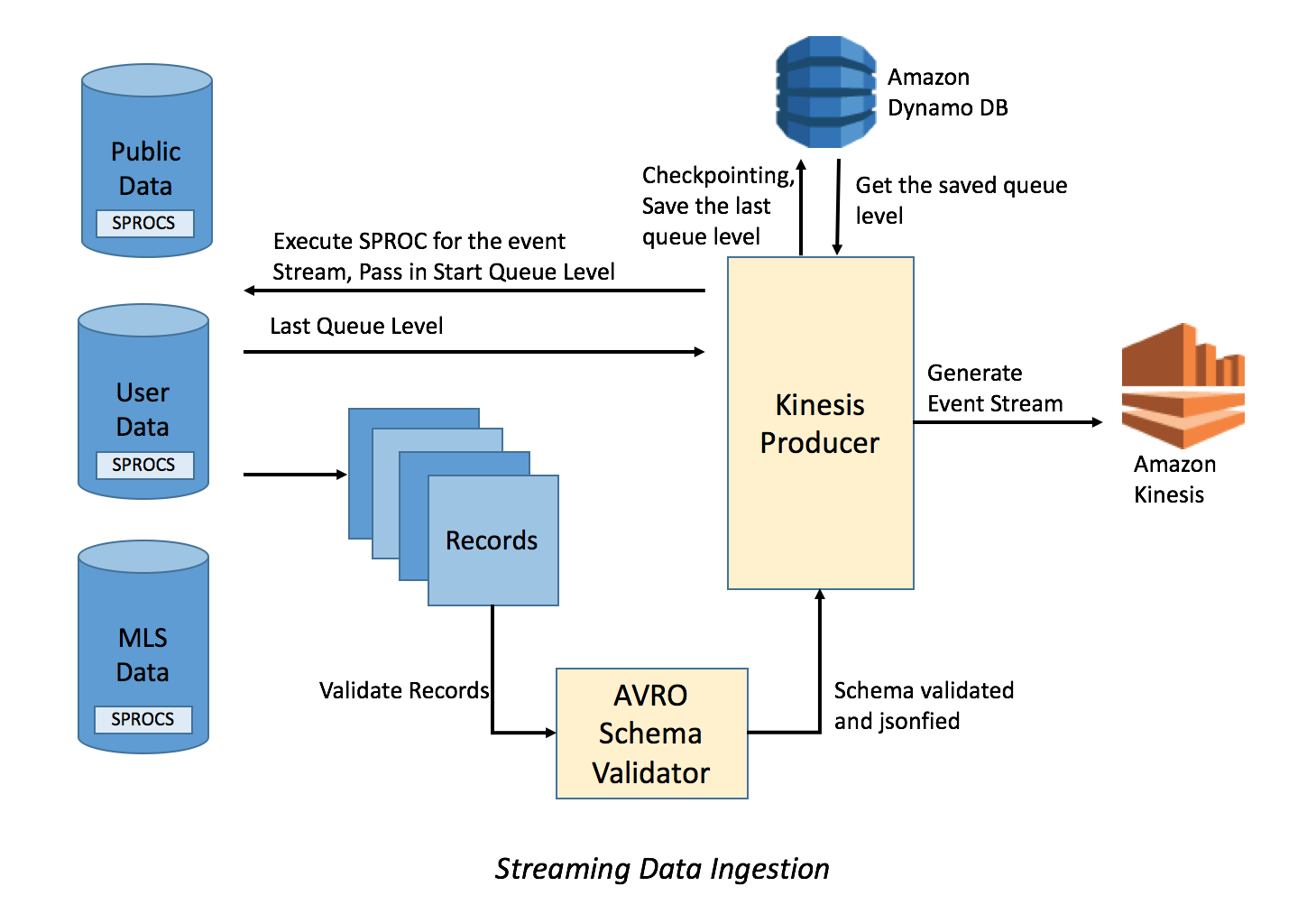
Streaming Data Ingestion
While designing this system, the biggest challenge has been performing data ingestion from existing databases to AWS Kinesis streams for all the historic data as well as designing a system to ingest new data we receive every second.
At Zillow, we have implemented an in-house data publishing service called Kinesis Producer which runs continuously and executes stored procedures on our databases, fetching data records corresponding to various event streams. Each record in the retrieved data is uniquely time stamped, validated with Avro Schema, converted to JSON for effective storage and published to respective Amazon Kinesis streams using Kinesis client libraries. This process can result in duplicate records, but they are de-duped in the downstream processes.

Once we have this valuable data ingested in the streaming architecture, it will be further used by the downstream processes for home valuation, personalization, content recommendation, predictive analysis, deep learning, business intelligence, market reports and other specialized use cases at Zillow Group.