- Press Releases
Sustainability
Social Impact
Explore how Zillow is driving real progress toward a more affordable and accessible housing market.
- Investors
- Careers
15 min read
The Data Infra Behind Zillow's 3x Growth in Experiment Volume

Introduction
ZEXP: AB Testing for all of Zillow (Zall)
When I was tapped to lead a newly formed team at Zillow focused on experimentation in mid-2020, Zillow was already one of the most visited real estate brands, with nearly 200 million monthly unique users. We had a clear need to continue to innovate our product to help our customers do more than browse homes and connect with real-estate agents, enabling them to “unlock life’s next chapter”. A company positioning itself to lead Real Estate 2.0 needed a rapidly accelerating innovation engine.
Today the mission & vision of the Zillow Experimentation team (shortened to ZEXP) is to “accelerate Zillow’s transition to help every customer win their dream home, by creating the most compelling experimentation platform & culture, empowering faster testing & decision making, and enabling all of Zillow (Zall) to take big swings to win & learn.”
In this post, I’ll share how we created our first big wins. In our first 2 years, we built a platform enabling Zillow to run 3x experiments, achieve significant cost and time savings, and compute more results more rapidly. We could not have moved this quickly without Zillow’s cutting-edge data & development infrastructure, which enabled us to build reliable and observable pipelines and rapidly iterate on both distributed workloads and scaled services. I’ll share an overview of that infrastructure and how it’s supporting our progress in experimentation.
AB Testing before ZEXP
Teams across Zillow had implemented nearly a dozen 3rd party or built from scratch experimentation tools, with each tool often only solving for one business or one key problem in the experimentation stack. For example, we had implemented services to enable assignment at scale, but product managers were sometimes waiting weeks for Data Scientists to have time to build experiment scorecards, custom authoring metrics, statistical tests, or visualizations. In other organizations, we implemented bought tools, but implemented only metrics local to the experience under test, keeping us in the dark on customer goals (for example: touring and completing a move) and cross-line-of-business impacts. In some cases, teams implemented self-service assignment and reporting, but without the infra or team capacity to scale beyond one product area or brand.
Without clearly paved paths, experiments were costly, unpredictable, and often untrustworthy. There was a clear need to enable our product teams and data scientists with a reliable and scalable experimentation framework, platform, and set of cultural processes.
ZEXP Vision
Zillow saw the opportunity in our vision for ZEXP: to solve for increased velocity, trust, and transparency with a single system, built to support AB testing and experiment use cases across all of our brands and experiences. We developed a hybrid build & buy strategy. We would build a flexible analysis platform, and integrate a bought solution with developer facing SDKs, enabling both feature-flagging and experimentation. In solving for analysis, we enabled a common analysis library (ZEXPy) and pipeline for both automated and manually configured analysis. We created the AB Testing Hub web application to enable self-service control of everything experiments, visualization of results, with tools to govern experiment designs, configurations, and decisions. Both ZEXPy and the AB Testing Hub are powered by a single source of truth API (“fast-ab”) for publishing and retrieving data on all experiments at
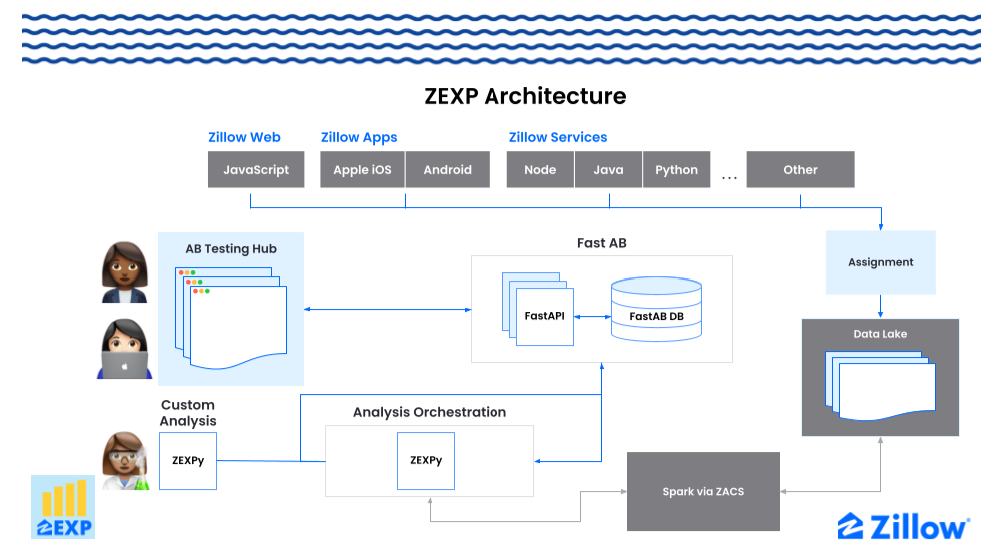 Figure 1. High Level ZEXP Architecture, enabling Zillow Product Managers and Engineers to own experiment configuration, results and decisions, and Zillow scientists to customize analysis.
Figure 1. High Level ZEXP Architecture, enabling Zillow Product Managers and Engineers to own experiment configuration, results and decisions, and Zillow scientists to customize analysis.
In solving for assignment, we wanted to optimize for speed of integration and adopt a solution as fast as possible. A bought solution would allow us to leverage a trusted and tested-at-scale solution. Onboarding could start in parallel, and be driven by product engineering teams, with SDKs and docs implemented across all of the languages and platforms we leverage. Integration with our ZEXPy analysis library would also be simple with a managed service delivering hourly logs of which entities were exposed to which experiments.
The Infrastructure
Distributed Compute
Zillow engineering teams maintain more than four thousand “applications”, including tools, services, pipelines, streams, and libraries. While product and platform teams had begun building new services on cloud-based infra, central services teams were still managing thousands of legacy applications on shared infrastructure with limited support for self-service deployments. Zillow made the decision to adopt a Kubernetes based infrastructure as a backbone for distributed, managed compute that would allow engineers to dramatically increase productivity and velocity.
The Zillow Group Container platform (ZGCP) is a platform and application for creating and managing Kubernetes clusters, created and supported by Zillow’s Developer Experience organization. ZGCP clusters support critical features like CICD, observability, config & secrets, autoscaling, and team level cost-attribution. Archetypes were developed in popular programming languages so that services and web applications could be launched in minutes not days. Even distributed applications could be developed with these archetypes, enabling Zillow to leverage node consolidation and auto scaling on any cloud instance type to power applications of nearly any scale.
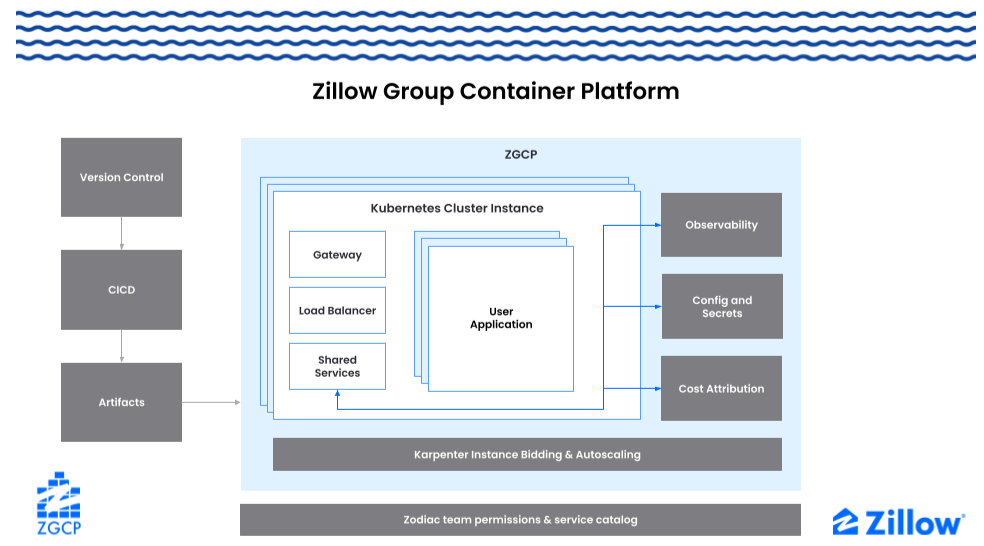 Figure 2. ZGCP enables teams across Zillow to build and deploy reliable applications in hours
Figure 2. ZGCP enables teams across Zillow to build and deploy reliable applications in hours
Around the time ZGCP was beginning to onboard pilot use cases, it was clear the human and capital costs of our Spark workloads were growing unsustainably. Our Data, Analytics & AI teams were spending more than 15% of our cloud budget on clusters to run more than thirteen thousand jobs. Our ZEXP team on-call was spending about half of their time supporting issues with cluster management, scaling, deployment, and instance provisioning. Leveraging learnings from ZGCP, our Data Infrastructure team delivered a solution that transformed our ability to scale Spark workloads with the delivery of the Zillow Analytics Compute Services (ZACS) platform.
ZACS fronts large clusters with a convenient SDK and API enabling data teams to submit distributed workloads of nearly any size. Leveraging the YuniKorn scheduler allows us to set per-team limits so that all teams can depend on regularly available capacity and predictable costs. The ZACS team built a plugin for our orchestration engine so that migrating jobs to ZACS was seamless, requiring only a substitution of our old spark-submit plugin for a new ZACS version. Even ad-hoc exploration is now much easier, with JupyterLab interactive environments connected to ZACS via SparkMagic, allowing interactive Spark jobs to process data and produce visualizations.
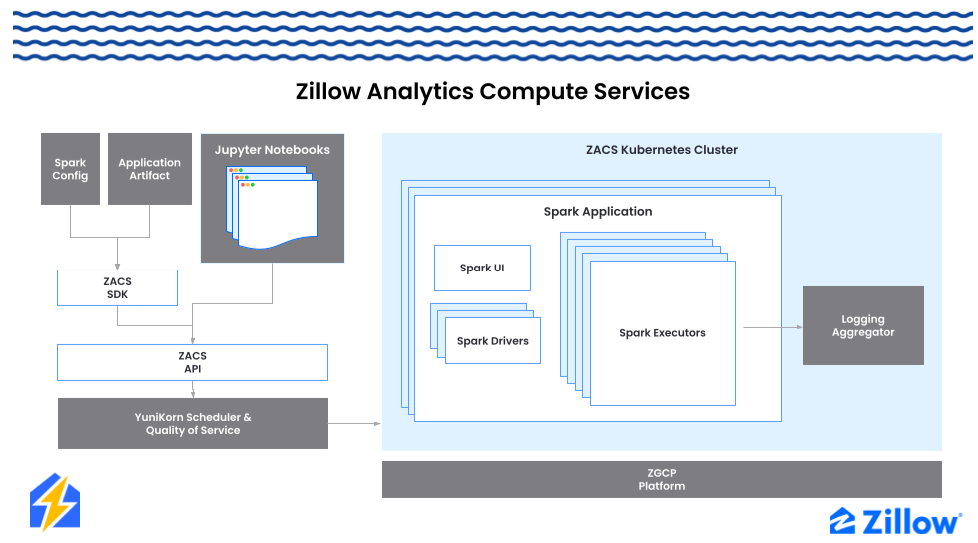 Figure 3. ZACS enables Zillow to run distributed data applications with efficient operations and compute costs.
Figure 3. ZACS enables Zillow to run distributed data applications with efficient operations and compute costs.
While ZGCP empowers Zillow to create services that are easily tested, deployed, monitored, and scaled, with ZACS, we can develop batch data applications on shared infra while easily scaling, tuning, and managing dependencies. With these advances, new bottlenecks became apparent in streaming data to enable responsive and personalized use-cases, and to create cross-enterprise sources of truth. Solving these challenges was critically important for experimentation as we needed it to be trivial for teams to reliably log user assignment and exposure to experiments, and user actions as events.
Distributed Data
Zillow customer activity creates more than 2B events every day, and Zillow needed a scalable, reliable, and distributed solution to ingest, validate, process, and store each and every event to enable trustworthy analytics, measurement, experimentation, and machine learning uses cases to help our customers find their home faster.
The Data Engineering team at Zillow wanted to enable all of Zall to create centrally cataloged, observable, testable, scalable, and schema-validated pipelines. This capability needed to include configurable data contracts to enable further observability and anomaly detection so that we could be alerted when unexpected events occur. The Data Streaming Platform (Streamz) and the Data Quality and Governance platform work together to increase quality and observability via anomaly detection and contract evaluation available as events are produced and delivered.
Streamz allows any event producer to create a new Kafka topic, companion data lake table and Flink job to process data in real time as it arrives in the topic. Topics, tables, and Flink jobs are easily provisioned in Terraform. Every asset is linked to an owning team so that costs and data quality alerts can be attributed downstream. Schema registry tools allow data producers to associate avro schemas to event ids, enabling schema validation as events are processed. Within a day, teams can set up new topics, produce events, and enable real time and batch processing of validated data.
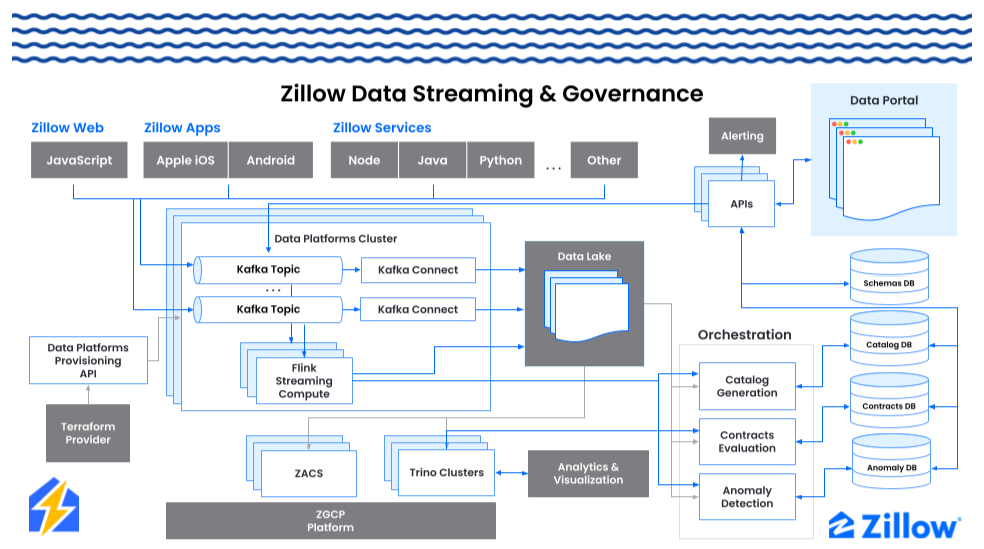 Figure 4. Zillow Data Streaming & Governance. Data Portal shown at upper right is the control center.
Figure 4. Zillow Data Streaming & Governance. Data Portal shown at upper right is the control center.
The Zillow Data Portal is the control center of Zillow data. Data Portal is a series of services and applications hosting schema registry, data catalogs, data contracts, anomaly detection configuration, metrics definition, batch SQL job definition, status and logs for ZACS jobs in one easily accessible web application.
Zillow’s Luminaire contracts enable data producers and consumers to define tests over streaming and batch data that can be executed on a schedule. A self-service interface enables easy configuration of contracts, including configuring the data source (whether streaming or at rest), business rules to validate, the cadence to complete data checks, and alerts to producers and consumers. Contract evaluations and results are shown directly in the UI, and can also be retrieved via API as dependency readiness checks. As we begin to develop a set of certified data products, contracts are required as a key mechanism to enable producers and consumers to drive quality together.
Zillow’s ZGCP has enabled ZEXP to build a scalable single source of truth service for experimentation, and with the ZACS platform, scalable and maintainable distributed data applications. With reliable and observable data produced and monitored by Zillow’s Data Platforms, ZEXP is empowered with trustworthy data and able to produce trusted analysis.
ZEXP Today
As these services were developed our team made the effort to become early champions and to support the work of these growing platforms. We designed our next generation experimentation framework and platform to take full advantage of the new capabilities offered by scalable compute and trustworthy data.
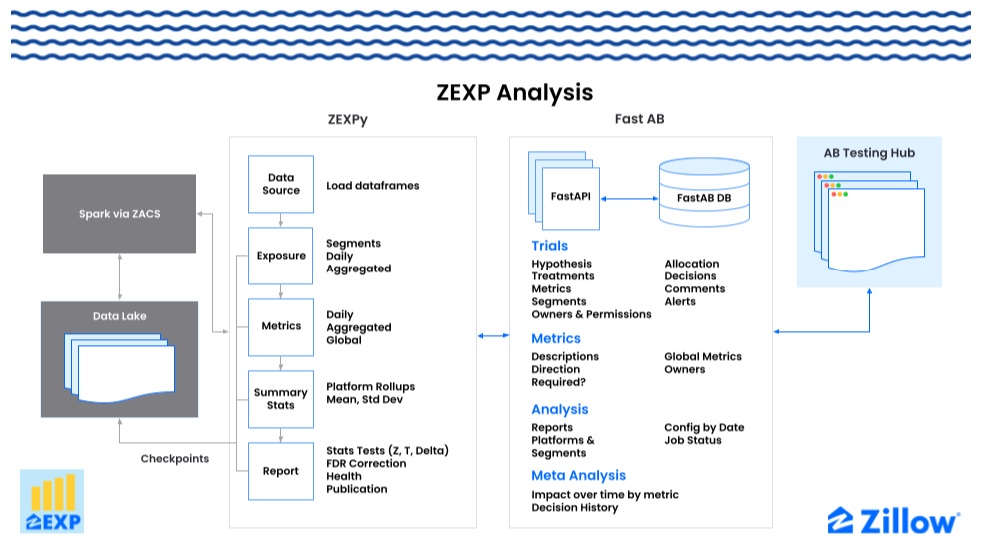 Figure 5. ZEXP Analysis is powered by the ZEXPy Experimentation Analysis Engine and the Fast-AB single source of truth API. The AB Testing Hub is hosted on the Data Portal.
Figure 5. ZEXP Analysis is powered by the ZEXPy Experimentation Analysis Engine and the Fast-AB single source of truth API. The AB Testing Hub is hosted on the Data Portal.
ZEXPy: Analysis Engine
When we set out to build an analysis capability that could support all of Zillow’s experimentation use cases, we had 3 goals in mind:
- Flexibility: We would need to onboard assignment, exposure, and metric data sources from across Zillow’s teams and lines of business, as Zillow’s data story continues to rapidly evolve. We wanted to make it seamless to incorporate custom segments, even when joining arbitrary data sources. We wanted to empower Zall to customize analysis with new techniques, capabilities, and governance as Zillow’s needs evolved.
- Trustworthy: We wanted our analysis work to be observable, with granular fault tolerance and checkpointing (by platform and segment, for example), with intermediate data output that could be inspected or used for debugging. It would have to be just a few clicks to replicate and debug our analysis so that scientists could trust its output.
- Batteries included: We repurposed this early Python motto as a shorthand for a pipeline that was easy to operate. We needed automatic backfill (including selective reprocessing of a single platform), and we wanted to motivate Data Scientists to retire their lengthy SQL statements for manual metrics and analysis in favor of a toolset they could extend for custom analysis and run locally as simply as it would run in production automation.
We implemented a Python and PySpark library, ZEXPy, actively maintained by our team, but open to contributions from others. ZEXPy defines interfaces for data sources, daily and aggregated exposure and metrics, and then calculates summary statistics and computes various stats tests. Global metrics can be computed for any data source, considering custom aggregation logic and context about the experimental unit. And checkpoint interfaces enable saving and loading intermediate data for each stage by trial, platform, and segment, so that intermediate data is available for reprocessing, manual analysis, or inspection.
Leveraging Zillow’s ZACS spark on Kubernetes solution, it’s just as easy to run an analysis locally as it is in scheduled orchestration. With the help of ZACS we’ve empowered data scientists to reproduce any of our analysis, with full control and customization of configuration in code, and with the option to dive deep into any intermediate data to inspect step by step.
ZEXPy has significantly reduced the effort we spend to add new channels, metrics sources, and capabilities to analysis, and it has dramatically lowered our costs, while increasing reliability and observability.
AB Testing Hub and FastAB: Transparency and Governance
AB Testing Hub, our self-service experimentation tool is also hosted in the Data Portal for easy discovery and configuration of experiments. Zall can view and explore the hypothesis, goal metrics, configuration, of any experiment, run by any team. Experiment owners can view critical alerts like SRM, and deep dive into experiment health by platform. Experiment stakeholders can view results as they’re updated daily, and add comments for the experiment owner with any questions.
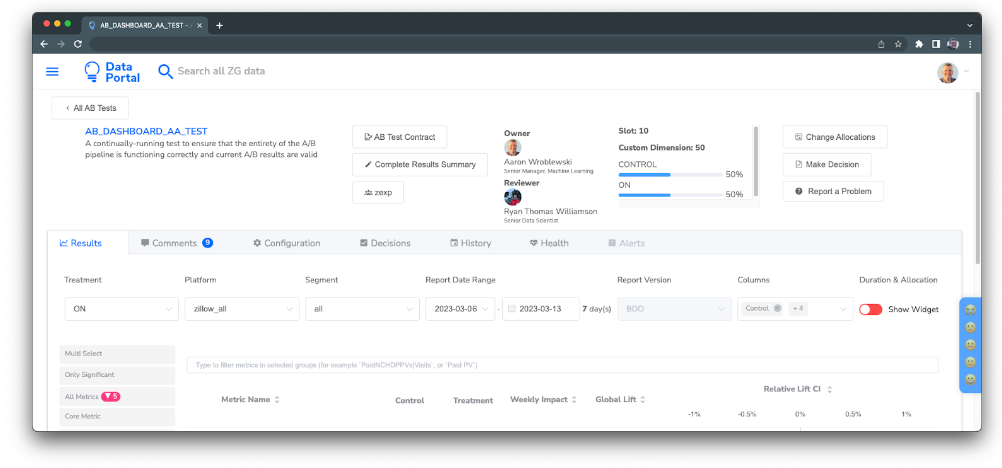 Figure 6. AB Testing Hub Scorecard. Experiment owners, key configuration, and statistically significant metric counts are readily available. Comments, configuration, Decisions, History, and Health are shown in detail tabs.
Figure 6. AB Testing Hub Scorecard. Experiment owners, key configuration, and statistically significant metric counts are readily available. Comments, configuration, Decisions, History, and Health are shown in detail tabs.
Learning from past experiments is essential to enable compounding innovation. We wanted to enable this learning by enabling owners to record key outcomes from their experiments for Zall to discover and learn from later on. When experiments are concluded, owners record a decision, including a summary, decision metrics, and a linked report so that the findings can be archived for monthly business reporting and for future reference. These results can be found in our Impact Dashboard, enabling browsing results by any metric, platform, channel, segment, or owner.
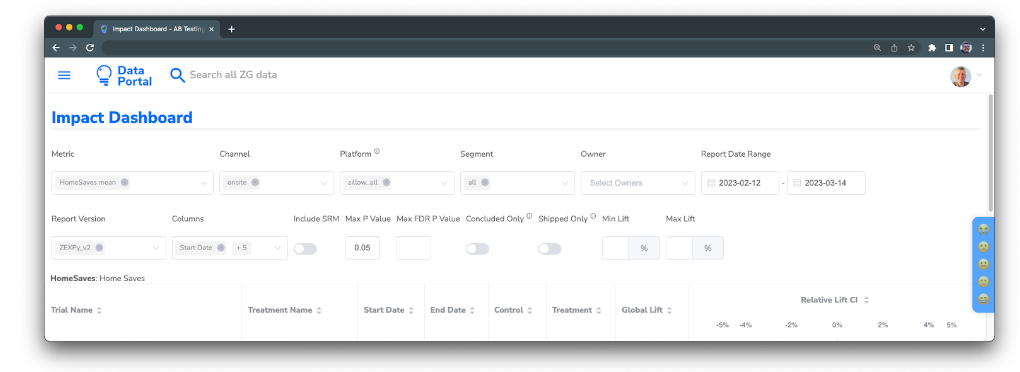 Figure 7. AB Testing Hub Impact Dashboard allows Zall to browse results measured in ongoing and concluded experiments from a metric-centric perspective, exploring how metrics have been impacted by experiments on various channels, platforms, segments, or run by selected owners & teams.
Figure 7. AB Testing Hub Impact Dashboard allows Zall to browse results measured in ongoing and concluded experiments from a metric-centric perspective, exploring how metrics have been impacted by experiments on various channels, platforms, segments, or run by selected owners & teams.
Powering the AB Testing Hub is our single source of truth for all experiments, the FastAB API, deployed as a ZGCP service. FastAB exposes APIs enabling all the capabilities in AB Testing Hub, including providing job config and status tracking by trial and analysis stage for our ZEXPy orchestration. Our team uses the job status tools to automatically reprocess and backfill individual trials, platforms, segments, and analysis days as needed.
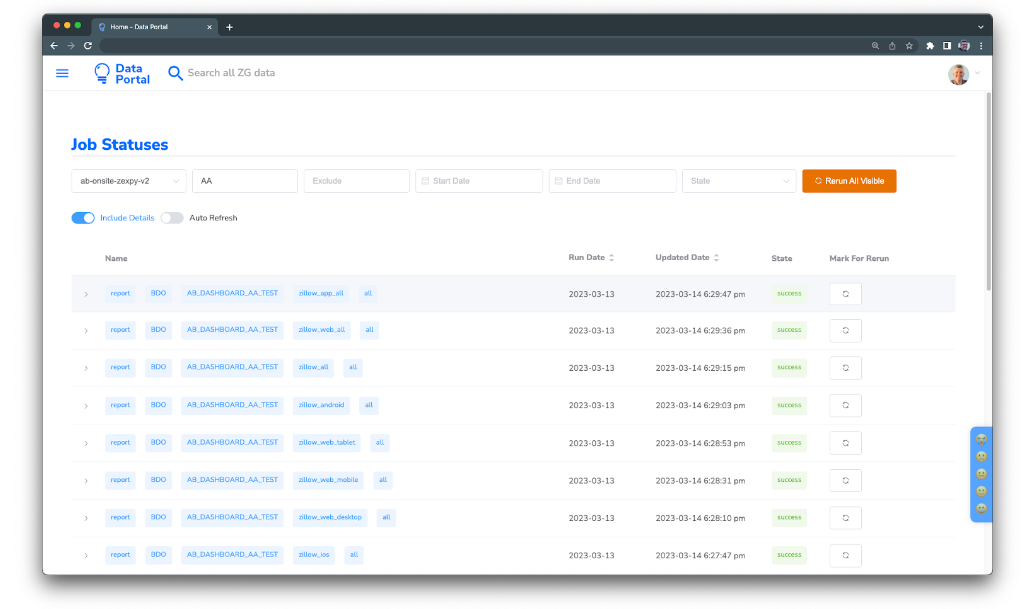 Figure 8. AB Testing Hub Job Status enables the ZEXP team to visualize and debug failures and rerun analysis tasks.
Figure 8. AB Testing Hub Job Status enables the ZEXP team to visualize and debug failures and rerun analysis tasks.
Future work
Culture
Our internal customers get really excited when we introduce features that help drive our product innovation process and ways of working. We see considerable opportunity to build tools that optimize for high bandwidth and rigorous coordination across teams in prioritizing, designing, launching and concluding experiments.
Trial Duration
Every business is different. Moving your home often has a long consideration cycle (deciding where to move and finding a home) and a long close cycle (offer, lease, mortgage, closing) that can vary by moving goal and location. We want to continue to lead in defining upper funnel metrics that predict lower funnel outcomes. We also see significant opportunity in applying existing techniques and exploring novel approaches to variance reduction.
Inner Source
Inner source is a software development methodology that applies open source principles within an organization. It encourages collaboration, knowledge sharing, and code reuse among teams, fostering a culture of transparency and continuous learning. By breaking down silos, inner source enables efficient problem-solving and accelerates innovation, while maintaining the necessary privacy and security for proprietary software. We developed ZEXPy with the hopes that we could empower scientists across the organization to contribute new methods to ZIllow experimentation. So far we’ve had a few successful collaborations, but we’d love to achieve widespread, cross-team adoption and contribution.
Metrics
While data is now flowing freely from producer to consumer at Zillow, what happens between receiving an event and analyzing the customer’s actions varies significantly depending on the internal use case. We’ve created significant impact from centralizing metric definition and computation for some data sets, and see significant opportunity to grow these solutions so that creating cross-dataset metrics and dimensions is self-service and democratized.
Meta Analysis
Centralizing all results and decisions has recently empowered our team to conduct meta-analysis over all of Zillow’s completed experiments. As we strive to improve the statistical rigor and cultural behaviors of experimentation, we now have a deep well of experience and data to draw on. We’re leveraging this capability to drive research into running faster experiments, improve visibility into experiment health, faster debugging and root cause analysis, and for validating new features.
Acknowledgements
Thanks to our partner teams whose work is described here, including Zillow Developer Experience, Data Engineering, and Analytics teams, and to our product teams for your dedication to winning and learning with experiments. Special thanks go to Jennifer Chunn, Leah Ganis, Ryan Williamson, Satish Matthew and to the entire ZEXP team for your partnership in evolving experimentation. Thanks to Eric Ringger, Yuliana Havryshchuk, Russell Rhodes, Hao Xu, and Adam Costanza for reviewing this post and providing feedback.
Related Articles




Sign up for Zillow news updates
Subscribe to receive daily emails for the latest Zillow news and announcements, product updates, research and more.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23111116;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M.67,84.17v-9.38L39.19,20.75v-1.12H1.34V4.67h62.64v9.38l-37.85,54.04v1.12h38.97v14.96H.67Z'/%3e%3cpath%20class='st0'%20d='M75.04,9.36c0-5.58,4.13-9.71,9.94-9.71s9.94,4.13,9.94,9.71-4.13,9.71-9.94,9.71-9.94-4.02-9.94-9.71ZM76.71,84.17V27h16.53v57.17h-16.53Z'/%3e%3cpath%20class='st0'%20d='M106.3,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M135.33,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M161.79,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM208.58,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M246.32,84.17l-17.2-57.17h16.86l11.61,40.64h1.12l10.16-40.64h16.53l10.94,40.98h1.12l11.39-40.98h16.41l-17.31,57.17h-21.55l-8.71-37.85h-1.12l-8.6,37.85h-21.66Z'/%3e%3cpath%20class='st0'%20d='M362.44,84.17V4.67h56.94v15.86h-38.3v17.53h33.5v14.51h-33.5v31.6h-18.65Z'/%3e%3cpath%20class='st0'%20d='M428.76,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.53Z'/%3e%3cpath%20class='st0'%20d='M471.64,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM518.43,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M545.11,84.17V27h16.52v8.04h1.12c4.24-6.48,9.71-9.71,16.64-9.71,12.95,0,21.55,10.05,21.55,23.78v35.06h-16.52v-32.72c0-7.03-4.02-11.95-10.72-11.95s-12.06,5.25-12.06,12.51v32.16h-16.52Z'/%3e%3cpath%20class='st0'%20d='M617.13,65.74v-26.69h-8.04v-12.06h8.49l3.24-18.09h12.95l-.11,18.09h13.06v12.06h-13.06v26.02c0,4.8,2.9,8.04,7.59,8.04,1.56,0,4.02-.33,5.92-.78v11.84c-3.24,1.12-7.93,1.79-11.17,1.79-11.5,0-18.87-8.15-18.87-20.21Z'/%3e%3cpath%20class='st0'%20d='M686.58,84.17V4.67h34.95c19.43,0,31.93,10.27,31.82,26.69,0,16.3-12.62,26.8-31.93,26.8h-16.52v26.02h-18.31ZM704.89,44.08h15.07c9.16,0,14.85-5.02,14.85-12.73s-5.81-12.62-14.85-12.62h-15.07v25.35Z'/%3e%3cpath%20class='st0'%20d='M757.71,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM804.49,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.19,6.7-15.19,16.19,6.25,16.3,15.19,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M831.17,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.52Z'/%3e%3cpath%20class='st0'%20d='M874.16,55.58c0-18.2,12.62-30.37,31.04-30.37,15.52,0,27.36,8.71,29.25,22.22l-15.41,2.01c-1.45-6.25-7.26-10.61-13.62-10.61-8.37,0-14.74,6.92-14.74,16.75s6.25,16.75,14.63,16.75c6.59,0,12.17-4.35,13.73-10.5l15.52,1.9c-2.12,13.51-14.07,22.22-29.37,22.22-18.2,0-31.04-12.28-31.04-30.37Z'/%3e%3cpath%20class='st0'%20d='M944.73,84.17V1.32h16.52v33.39h1.12c4.35-6.25,9.71-9.49,16.64-9.49,12.95,0,21.66,10.05,21.66,23.67v35.28h-16.52v-32.83c0-7.03-4.13-11.95-10.83-11.95s-12.06,5.25-12.06,12.62v32.16h-16.52Z'/%3e%3c/svg%3e)
