- Press Releases
Sustainability
Social Impact
Explore how Zillow is driving real progress toward a more affordable and accessible housing market.
- Investors
- Careers
12 min read
Topic Modeling for Real Estate Listing Descriptions
Details about a home can be provided through multiple modalities, including video, image, text, or structured data at Zillow. While structured data such as lot size and square footage of a home can be easily leveraged by a machine learning system to provide signal regarding the home, other modalities may need further preprocessing steps to capture their representations in a usable form (e.g., as a feature vector). The textual modality (in the form of listing descriptions) often contains unique information about a home. One solution to represent listing descriptions for a machine learning system is to use a document-term matrix, which is a large sparse matrix. For example, given two homes with the following listing descriptions,
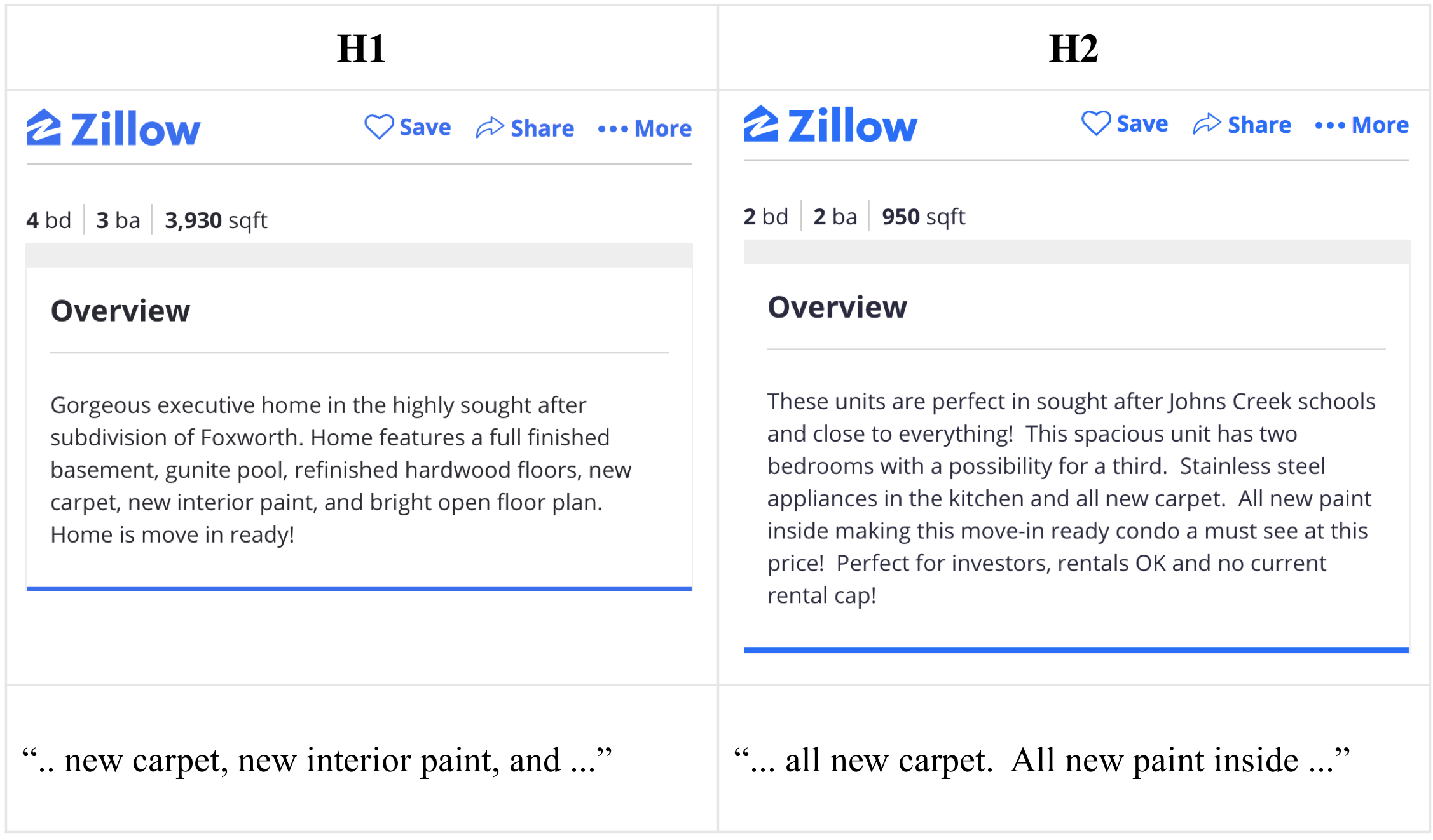
Figure 1: An example of descriptions for two different listings at Zillow.
We can represent the listing descriptions of these homes by their own sparse vectors, each constituting a row of the matrix:
Table 1: An example of representation of the listing descriptions.

To tackle the problem of sparsity, we can project the large-dimensional sparse space into a lower cardinality dense space via topic modeling techniques. These models represent each home as a probability distribution over topics and each topic as a probability distribution over individual words. There are many hyper-parameters to tune in training topic models, such as the number of topics or the list of stopwords. The optimal configuration of these hyper-parameters poses one of the main challenges in using topic models.
In this blog post, we describe steps that can be taken to understand the listing descriptions using a topic modelling algorithm. We focus on:
- preprocessing steps and their necessity in training a topic model
- effect of the number of topics in training a topic model
- inter-topic distance map in discovering clusters of topics.
Latent Dirichlet Allocation (LDA)
We use the now standard Latent Dirichlet Allocation (LDA) model , depicted as a directed graphical model with the plate notation in Figure 1. In this generative model, each word (W) in a home description is generated according to the distribution over words for the given topic (Z). In the context of the current document, the topic is generated from the document’s distribution over topics with parameter (). The topics are characterized by a distribution of words within each of K topics (). This model describes K topics that generate N words in the description of any of the M homes listed on Zillow.
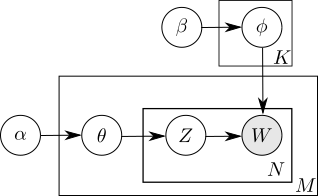
Figure 1: Directed graphical model (with plate notation) of LDA
Distribution of words in the collection of Zillow listing descriptions
The distribution of words plays a critical role in the distribution of topics trained using LDA.Therefore, before getting deep into the topic models, let’s understand the distribution of words in the collection of listing descriptions at Zillow. First, we look at the popularity of words (tokenized by NLTK tokenizer ) in this collection. We remove punctuation marks and use the Porter stemmer to reduce the size of the vocabulary.
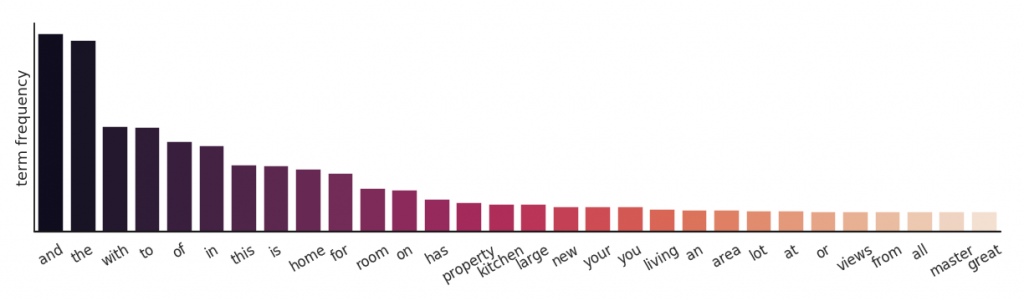
Figure 2: Term Frequency of popular words in the collection of listing descriptions.
The term frequencies of the most popular words in this collection of listing descriptions, shown in Figure 2, provide valuable information regarding the distribution of words in this collection. The word “home” exists in over half of the listing descriptions. The following words exist in more than a quarter of listing descriptions in Zillow:
Table 2: List of words in over 25% of listing descriptions.
![]()
The popularity of stopwords in listing descriptions at Zillow is also different from the popularity in general English documents such as the one provided by NLTK. Some noteworthy differences are:
- The word “and” is more popular than the word “the” in this listing descriptions collection, which can be an indication that in this collection, the descriptions tend to include a list of home features which also increases the popularity of “with”.
- The word “home” is more popular than words such as “for” and “on” that are commonly considered as stopwords (due to their popularity) in general English documents.
- Popular words in this collection belong to different attributes of home such as “room”, “kitchen”, and “master ”.
Furthermore, some interesting observations:
- The popularity of the words “lot”, “view”, “location” and “acre” shows the importance of view, location, and lot size of homes or vacant lands in this domain.
- The most popular adjectives that listing agents tend to mention in the listing descriptions are “new”, “large”, “great”, and “beautiful”.
- The most popular verb is “live”, which is frequently used in listing descriptions in sentences such as “.. if you want to live in a quiet neighborhood close to ...”. The word “live” is also popular because it has the same stem as the word “living” in the phrase “living room”.
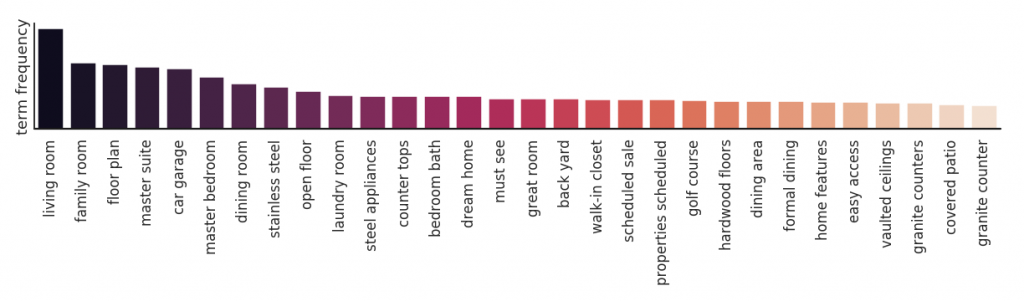
Figure 3: List of most popular bigrams in the listing descriptions.
We remove general list of stopwords (provided by NLTK) and in addition to unigrams, we looked at the popularity of bigrams in this collection (shown in Figure 3) and observed that:
- The most popular bigrams belong to attributes of home. The only
- The most popular descriptive bigrams are “dream home”, “must see” and “great room”.
Effect of Domain-specific Popular Words in Training the LDA Model
Words that frequently exist in a majority of documents such as “and” and “the” are often assumed to have less effect on the topics in the document describes. Therefore, as a pre-processing step to train LDA, it is a common practice to remove the list of popular words from the collection. In the following, we examine the effect of domain-specific popular words, such as “home” and “room”, on the distribution of derived topics.
We utilize word clouds to depict the topic distributions. Considering only two topics per collection, we get the following distribution of words over topics:

Figure 4: Distribution of words per topic when we assume to have only two topics.
In the word clouds as shown in Figure 4, the size of each word depends on the probability of this word given each of the topics - p(word|topic). In one topic, the most related words are “room” and “home” and in the other topic, the most related words are “lot” and “home”. Given only two topics, we can understand that the listing descriptions are mainly about the topics “existing homes” and “vacant lands”. This result is consistent with the fact that listings in Zillow correspond to either existing homes or vacant lands. Since the word “home” exists in more than half of the listing descriptions, it was expected to be displayed as the most related word in both topics.
From the distribution of words per each topic in Figure 5, we can see that removing the word “home” does not significantly change the semantic meaning of topics. By removing the word “home”, we can observe that other words, such as “bedroom” and “kitchen” in one topic and “property” and “located” in the other topic, have higher relevance probabilities.

Figure 5: Distribution of words per topic after removing the most popular word “home” when we assume to have only two topics.
By repeating the above step and removing the next most related words (“room”, “kitchen” and `“lot”) from the collection, we observe that these topics have slight changes in their semantic meanings. For example, we can see that by removing the word “kitchen”, the first topic has higher relevance to the words “bedroom” and “master”.

Figure 6: Distribution of words per topic after removing three most related words to topics (“home”, “kitchen”, and “lot”) when we assume to have only two topics.
The next question is, whether the meaning of each topic changes more significantly when a larger number of LDA topics is extracted? In the following figures, we have four topics and we keep all the popular words:

Figure 7: Distribution of words per topic when we assume to have only four topics.
Now, we remove the popular words that appear in more than a quarter of listing descriptions and obtain the following topics:

Figure 8: Distribution of words per topic after removing the words exist in more than a quarter of listing descriptions when we assume to have only four topics.
We can see that by increasing the number of topics (from 2 to 4), removing popular words from the collection results in a more significant change in the semantic meaning of the derived topics. In the case of having four topics, by removing the popular words from the collection, instead of a topic about “view”, the model derives a topic about “sale”. On the other hand, when there is a larger number of topics, the model has a larger number of parameters and less likely converging towards the same answer. Therefore, by having a larger number of topics, the model has less confidence in its derived topics and as a result, there is a more significant change when we remove the most popular words from the collection.
Number of topics in Training the LDA model
The number of topics is a hyper-parameter in the LDA model. As shown earlier, given a different number of topics, the trained LDA model provides different insights regarding the collection of listing descriptions. By increasing the number of topics, the list of topics trained by the LDA model tends to contain duplicate or similar topics. For example, given 100 topics, we identify the following topics:

Figure 9: Distribution of words per topic when we assume to have only 100 topics (only 4 topics are depicted in this figure).
The second and third topics in Figure 9 share the same list of most relevant words, thus they can be considered as duplicate topics. Duplicate topics are generated by LDA when the given number of topics is greater than the actual number of topics in the collection. Therefore, the next question that we need to address is what is the actual number of topics in the given collection of home description. By increasing the number of topics to train LDA, the LDA model still converges to the same number of unique topics, since the actual number of topics can be less than the given number of topics. By using perplexity to measure the quality of the topic model, from Figure 10, we can see that the model has the lowest perplexity when we select 10 as the number of topics to train the LDA model. In other words, we can conclude that the actual number of topics is around 10.
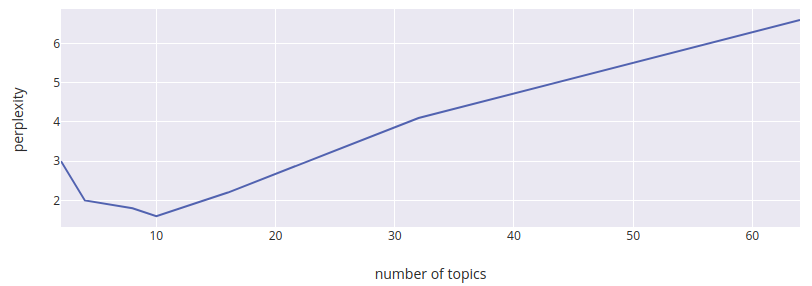
Figure 10: The perplexity in terms of # of topics in the training of the LDA model.
From the inter-topic distance map, described in the next section, we show that the derived topics can be clustered into a smaller number of topics.
Inter-topic Distance Map
We can compute inter-topic distances using Jensen-Shannon divergence , to understand the similarity of topics. Besides the distribution of words within topics, the inter-topic distances provide valuable information regarding the content of listing descriptions. By considering the distance between topics, we can infer clusters of topics. For example, from the following two figures, we can understand that the set of topics (topics 30, 20, 15, 22, … shown in the right bottom corner of the following figure) have a significant inter-topic distance from the rest of the topics. These topics can be considered as a cluster of topics that is about the location of a house and its distance from different attractions such as shops, beaches, and mountains.
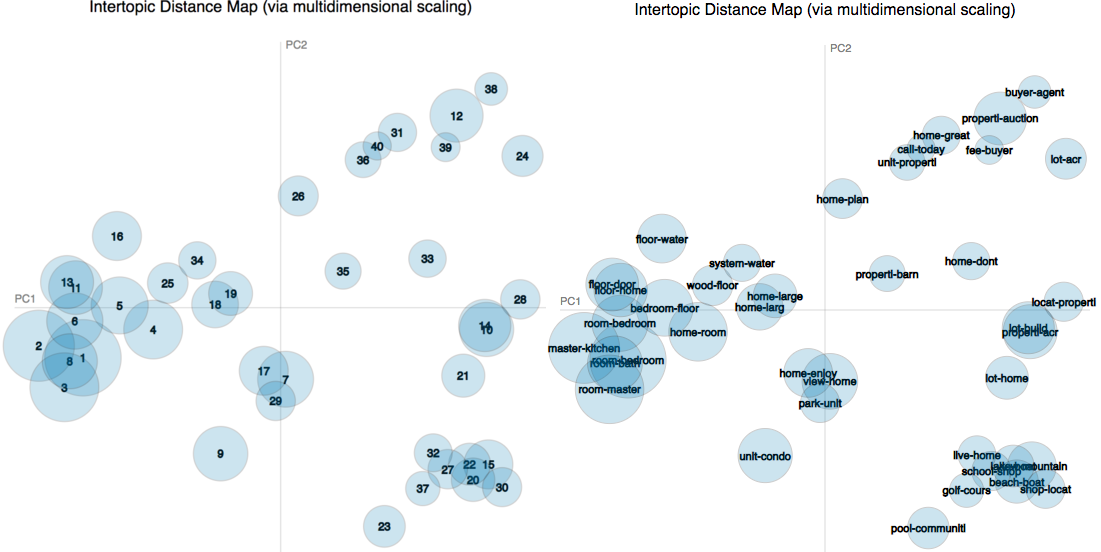
Figure 11: The inter-topic Distance Map of the topics discovered by using LDA. The size of each circle depends on the number of documents that are related to its corresponding topic. The distance between circles depends on the similarity of topics. It can be seen that the topics are mainly about three main cluster of topics.
The distribution of detected topics reveals the main topics that are mentioned in the listing descriptions at Zillow: “Homes for sale/rent”, “Vacant Lands”, “Real Estate Investment”, and “attractions”. The number of documents that have higher dependency with “Homes for sale/rent” is more than the number of documents that belong to the other main two topics.
Conclusion
- LDA is a useful tool in understanding the listing descriptions in scale. It provides a list of topics that the listings describe and can help in better understanding of listing descriptions.
- The word that is most common among multiple topics is “home”, which is also the most popular word in the collection. Removing the domain-specific popular words such as “home” may have a slight change in the distribution of topics if they have similar relevance to all topics. Otherwise, the removal of common words in this domain changes the distribution of discovered topics and the modified distribution of topics may not be the best representation of the listings descriptions. Therefore, we do not suggest to consider these common words as stop-words.
- We observed that the topics in the listings descriptions is around 40 as duplicated topics are generated when training LDA model with a larger number of topics. A similar observation can be achieved by using perplexity to find the optimal number of topics.
- inter-topic distance map provides valuable insights on the distribution of topics. According to the inter-topic distance map of topics, there are three main cluster of topics in the listing descriptions which are “existing homes”, “vacant lands”, and “investment”. The number of topics and the number of listings that belong to the cluster of topics “existing homes” is significantly more than the ones belonging to the other cluster of topics.
References
Blei, David M., Andrew Y. Ng, and Michael I. Jordan. 'Latent dirichlet allocation.' Journal of machine Learning research 3, no. Jan (2003): 993-1022.
https://www.nltk.org/api/nltk.tokenize.html
Wallach, Hanna M., Iain Murray, Ruslan Salakhutdinov, and David Mimno. 'Evaluation methods for topic models.' In Proceedings of the 26th annual international conference on machine learning, pp. 1105-1112. ACM, 2009.
Lin, Jianhua. 'Divergence measures based on the Shannon entropy.' IEEE Transactions on Information theory 37, no. 1 (1991): 145-151.
Related Articles




Sign up for Zillow news updates
Subscribe to receive daily emails for the latest Zillow news and announcements, product updates and more.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23111116;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M.67,84.17v-9.38L39.19,20.75v-1.12H1.34V4.67h62.64v9.38l-37.85,54.04v1.12h38.97v14.96H.67Z'/%3e%3cpath%20class='st0'%20d='M75.04,9.36c0-5.58,4.13-9.71,9.94-9.71s9.94,4.13,9.94,9.71-4.13,9.71-9.94,9.71-9.94-4.02-9.94-9.71ZM76.71,84.17V27h16.53v57.17h-16.53Z'/%3e%3cpath%20class='st0'%20d='M106.3,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M135.33,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M161.79,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM208.58,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M246.32,84.17l-17.2-57.17h16.86l11.61,40.64h1.12l10.16-40.64h16.53l10.94,40.98h1.12l11.39-40.98h16.41l-17.31,57.17h-21.55l-8.71-37.85h-1.12l-8.6,37.85h-21.66Z'/%3e%3cpath%20class='st0'%20d='M362.44,84.17V4.67h56.94v15.86h-38.3v17.53h33.5v14.51h-33.5v31.6h-18.65Z'/%3e%3cpath%20class='st0'%20d='M428.76,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.53Z'/%3e%3cpath%20class='st0'%20d='M471.64,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM518.43,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M545.11,84.17V27h16.52v8.04h1.12c4.24-6.48,9.71-9.71,16.64-9.71,12.95,0,21.55,10.05,21.55,23.78v35.06h-16.52v-32.72c0-7.03-4.02-11.95-10.72-11.95s-12.06,5.25-12.06,12.51v32.16h-16.52Z'/%3e%3cpath%20class='st0'%20d='M617.13,65.74v-26.69h-8.04v-12.06h8.49l3.24-18.09h12.95l-.11,18.09h13.06v12.06h-13.06v26.02c0,4.8,2.9,8.04,7.59,8.04,1.56,0,4.02-.33,5.92-.78v11.84c-3.24,1.12-7.93,1.79-11.17,1.79-11.5,0-18.87-8.15-18.87-20.21Z'/%3e%3cpath%20class='st0'%20d='M686.58,84.17V4.67h34.95c19.43,0,31.93,10.27,31.82,26.69,0,16.3-12.62,26.8-31.93,26.8h-16.52v26.02h-18.31ZM704.89,44.08h15.07c9.16,0,14.85-5.02,14.85-12.73s-5.81-12.62-14.85-12.62h-15.07v25.35Z'/%3e%3cpath%20class='st0'%20d='M757.71,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM804.49,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.19,6.7-15.19,16.19,6.25,16.3,15.19,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M831.17,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.52Z'/%3e%3cpath%20class='st0'%20d='M874.16,55.58c0-18.2,12.62-30.37,31.04-30.37,15.52,0,27.36,8.71,29.25,22.22l-15.41,2.01c-1.45-6.25-7.26-10.61-13.62-10.61-8.37,0-14.74,6.92-14.74,16.75s6.25,16.75,14.63,16.75c6.59,0,12.17-4.35,13.73-10.5l15.52,1.9c-2.12,13.51-14.07,22.22-29.37,22.22-18.2,0-31.04-12.28-31.04-30.37Z'/%3e%3cpath%20class='st0'%20d='M944.73,84.17V1.32h16.52v33.39h1.12c4.35-6.25,9.71-9.49,16.64-9.49,12.95,0,21.66,10.05,21.66,23.67v35.28h-16.52v-32.83c0-7.03-4.13-11.95-10.83-11.95s-12.06,5.25-12.06,12.62v32.16h-16.52Z'/%3e%3c/svg%3e)
