- Press Releases
Sustainability
Social Impact
Explore how Zillow is driving real progress toward a more affordable and accessible housing market.
- Investors
- Careers
6 min read
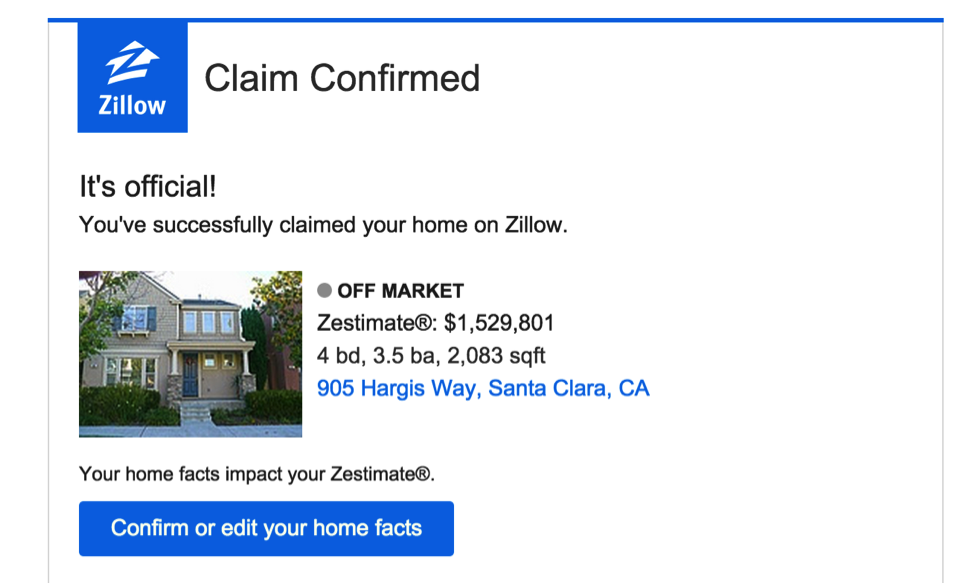
Personalization: Who Owns that Home?

Zillow maintains a database of 110 million homes in the United States. To keep the database updated, we import data from with various feeds from the counties, brokers, and MLS. Another important source of data is the actual homeowner. We have a feature called “Claim Your Home” that allows the homeowner, after verification, to update their home data - such as home facts, description, and photos and videos. This data is also used to improve the accuracy of the Zestimate. Moreover, after claiming, the homeowners will have access to unique content and tools related to their home.
In order to get more users to claim their home, we implemented a machine learning application and multiple models to predict the homeowner for all homes nationwide. The models are used in a variety of use cases to increase home claims. For example, we display a pop-up for the user to claim the home if the model predicts a high score.
Models
There are multiple regression classification models involved - NFS (not for sale homes) property model, RS (recently sold homes) property model, user model, and an ensemble model. The NFS property model predicts the owner of a home based on user behavior for a particular home. The RS property model is similar to the NFS property model, but the model is optimized for recently sold homes. The reason to split the models is that we found the feature importance to be quite different. To avoid the vast search pitfall and improve accuracy, we wanted to reduce # of predictive variables, and thus we decided to split up the models. Finally, the user model predicts the owner of the home leveraging a particular user’s behavior across the various Zillow brands sites and mobile apps.
Training Set
Our homeowner predictions are based on supervised learning methodologies. The training sets for the various models are based on variations of website and mobile behavioral data. The label is binary - did this user activity belong to the user that claimed the property. The training set row represents a user activity in regards to an actual property. Thus, in aggregate, the training set is all user activity events for homes with actual claims. There differences between the various models is in the feature engineering.
Feature Engineering
Feature engineering is the process of mapping important raw signals into concrete variables for the model. The decision to split our predictions into multiple models was driven by the feature engineering process and model performance metrics.
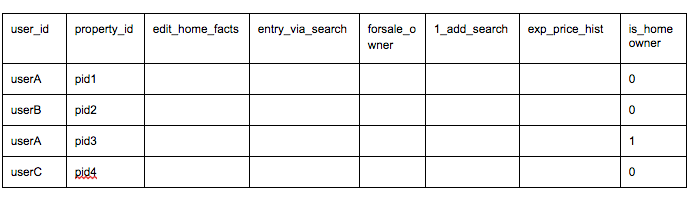
For the property models, we are interested in predicting a homeowner based on user behavior signals relative to the particular property we are predicting. In other words, for a specific property, we want to look at all user activity (e.g. page view, clicks on tabs, interaction with photos) from all users, which includes the actual homeowner, and distinguish homeowner activity from non-homeowner activity. Out of 45 different features, here are some of the important ones for the NFS property model:
edit_home_facts = (# times user triggered edit home fact event on the property) / (# of times all users triggered edit home fact event on the property)
entry_via_search = (# of times user arrived at the property via search on homepage from the sell tab) / (# of times all users arrived at the property via search on homepage from the sell tab)
forsale_owner = (# of times user triggered post as for-sale-by-owner event) / (# of times all users triggered post as for-sale-by-owner event)
1_add_search = (# of times user searched for single address for the target home) / (# of times all users searched for single address for the target home)
exp_price_hist = (# of times user expanded price history module) / (# of times all users expanded price history module)
The training data set, with a subset of the predictor variables, looks something like this:
The user model follows a similar paradigm. The difference is within the feature engineering - specifically the features only incorporate that specific user’s activity across all properties (vs. all other user activity for the particular property as in the property models).
Model Performance
The key model performance metrics we looked at are:
Precision - % of homeowners predicted correctly vs. incorrectly (not homeowner)
Recall - % of homeowners we predicted correctly returned from the overall set of homeowners
F1 - overall accuracy and effectiveness of our model
We found the property models were very strong in recall but not as strong with precision. On the other hand, our user model was weak in recall but strong in precision. By combining these various models, we are able to get a good balance of high recall and high precision.
System Engineering
Now that the model and features have been figured out, the next step is to actually make predictions of the homeowner for 150+ million homes. This requires us to move the model prototype code - which includes data ingestion, ETL, feature extractions, training and scoring the model - into real production code. Our definition of “real” production code is
Unit tests with code coverage at least 80%
Regression test suite with golden data set
Automation - continuous integration and deployment
High quality code - the right data structures, efficient but clean / maintainable Python code.
Performance & Scalability - the code runs quickly and can scale linearly as we add nodes.
We decided on Spark as our data processing platform. For data, we decided on real-time streaming data ingestion with Kinesis. The only reasons we decided on Kinesis over open-source Kafka is (1) Kinesis is cheap and (2) Kinesis is a managed service - so less work on the operations side of things.
With Spark, the data partitioning strategy is critical for performance. The goal is to avoid major shuffle operations by partitioning the data appropriately at the beginning. I’ll post on more details of Spark and performance in future blogs.
Conclusion
The home claims model has been a huge success in driving up home claims by homeowners. We have a lot of new ideas we are exploring - including using more data sources and signals, exploring different modeling techniques to improve the precision and recall, and performance optimizing our code to squeeze out better performance.
Related Articles




Sign up for Zillow news updates
Subscribe to receive daily emails for the latest Zillow news and announcements, product updates and more.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23111116;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M.67,84.17v-9.38L39.19,20.75v-1.12H1.34V4.67h62.64v9.38l-37.85,54.04v1.12h38.97v14.96H.67Z'/%3e%3cpath%20class='st0'%20d='M75.04,9.36c0-5.58,4.13-9.71,9.94-9.71s9.94,4.13,9.94,9.71-4.13,9.71-9.94,9.71-9.94-4.02-9.94-9.71ZM76.71,84.17V27h16.53v57.17h-16.53Z'/%3e%3cpath%20class='st0'%20d='M106.3,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M135.33,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M161.79,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM208.58,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M246.32,84.17l-17.2-57.17h16.86l11.61,40.64h1.12l10.16-40.64h16.53l10.94,40.98h1.12l11.39-40.98h16.41l-17.31,57.17h-21.55l-8.71-37.85h-1.12l-8.6,37.85h-21.66Z'/%3e%3cpath%20class='st0'%20d='M362.44,84.17V4.67h56.94v15.86h-38.3v17.53h33.5v14.51h-33.5v31.6h-18.65Z'/%3e%3cpath%20class='st0'%20d='M428.76,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.53Z'/%3e%3cpath%20class='st0'%20d='M471.64,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM518.43,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M545.11,84.17V27h16.52v8.04h1.12c4.24-6.48,9.71-9.71,16.64-9.71,12.95,0,21.55,10.05,21.55,23.78v35.06h-16.52v-32.72c0-7.03-4.02-11.95-10.72-11.95s-12.06,5.25-12.06,12.51v32.16h-16.52Z'/%3e%3cpath%20class='st0'%20d='M617.13,65.74v-26.69h-8.04v-12.06h8.49l3.24-18.09h12.95l-.11,18.09h13.06v12.06h-13.06v26.02c0,4.8,2.9,8.04,7.59,8.04,1.56,0,4.02-.33,5.92-.78v11.84c-3.24,1.12-7.93,1.79-11.17,1.79-11.5,0-18.87-8.15-18.87-20.21Z'/%3e%3cpath%20class='st0'%20d='M686.58,84.17V4.67h34.95c19.43,0,31.93,10.27,31.82,26.69,0,16.3-12.62,26.8-31.93,26.8h-16.52v26.02h-18.31ZM704.89,44.08h15.07c9.16,0,14.85-5.02,14.85-12.73s-5.81-12.62-14.85-12.62h-15.07v25.35Z'/%3e%3cpath%20class='st0'%20d='M757.71,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM804.49,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.19,6.7-15.19,16.19,6.25,16.3,15.19,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M831.17,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.52Z'/%3e%3cpath%20class='st0'%20d='M874.16,55.58c0-18.2,12.62-30.37,31.04-30.37,15.52,0,27.36,8.71,29.25,22.22l-15.41,2.01c-1.45-6.25-7.26-10.61-13.62-10.61-8.37,0-14.74,6.92-14.74,16.75s6.25,16.75,14.63,16.75c6.59,0,12.17-4.35,13.73-10.5l15.52,1.9c-2.12,13.51-14.07,22.22-29.37,22.22-18.2,0-31.04-12.28-31.04-30.37Z'/%3e%3cpath%20class='st0'%20d='M944.73,84.17V1.32h16.52v33.39h1.12c4.35-6.25,9.71-9.49,16.64-9.49,12.95,0,21.66,10.05,21.66,23.67v35.28h-16.52v-32.83c0-7.03-4.13-11.95-10.83-11.95s-12.06,5.25-12.06,12.62v32.16h-16.52Z'/%3e%3c/svg%3e)
