Balancing Latency and Accuracy in the Zestimate
Introduction
As the Zestimate is a huge driver of traffic to Zillow, we are constantly evolving our technology and approach as we refine the algorithm. We’ve made significant gains in accuracy and we are currently hosting one of the largest machine learning competitions ever to see if anyone can improve the accuracy further. Some of the biggest changes the Zestimate has undergone have been in the last two years.
In early 2015, right around the time I started at Zillow, a few of my colleagues presented on the Zestimate architecture—as it was then. At the core, the Zestimate then was largely written in R. We built a team of R language experts and designed our own in-house R framework for parallelization (à la Hadoop MapReduce). We were a smaller team, mostly data scientists who also had a knack for engineering. We leaned heavily on other teams, especially our database administrators, to reduce the amount of infrastructure we had to maintain.
Two years later, we have made a hiring push across all skill sets and invited engineers to join the fray. Python has become the new language of choice, thanks mostly to its long history of support in Apache Spark. We started leveraging more and more cloud-based services, such as Amazon’s Simple Storage Service (S3) for storing our data and Elastic MapReduce for compute. No longer are we bottlenecked by the size of a single machine.
With all of these changes, we had the opportunity to start afresh and design a system that would handle large amounts of data in the cloud, that would rely on horizontal scaling (instead of vertical), and most importantly would meet the larger goals of the Zestimate.
What are the goals of the Zestimate that drive our team day-to-day to make improvements? Our first priority is accuracy—when a home sells, our estimated market value should be near that sale price. Moreover, the Zestimate should be an independent assessment of the value of a home. It should not be heavily influence by the list price set by the agent (as other automated home valuation models are doing), but be independent so it benefits buyers and sellers. The Zestimate should also be stable over time and not exhibit erratic behavior day-to-day. Finally, the Zestimate should be able to respond quickly to an update in home facts—if a user corrects the number of bedrooms in their home, the Zestimate should be recalculated and immediately reflect that change. Our new Zestimate pipeline had to support these goals.


Lambda Architecture
Enter Lambda Architecture. Nathan Marz, who you may know as the Apache Storm creator, is often credited with the idea and even published a book on the subject. In short, Lambda Architecture is a generic data processing architecture that is horizontally scalable, fault-tolerant (in the face of both human and hardware errors), and capable of low-latency responses.
But, how can we expect to have low latency responses when processing enormous amounts of data? We will have to trade off some degree of accuracy to do so. The Databricks team showcased this accuracy-latency tradeoff when introducing Apache Spark’s approximation algorithms in 2016. Below are the plots their team produced when studying the lengths of Amazon reviews at various quantiles. The targeted residual—or the error bound that the result is guaranteed to be within—is plotted on the x-axis. As we would guess, the higher the residual, the less computationally expensive the calculation becomes, but at the cost of accuracy.
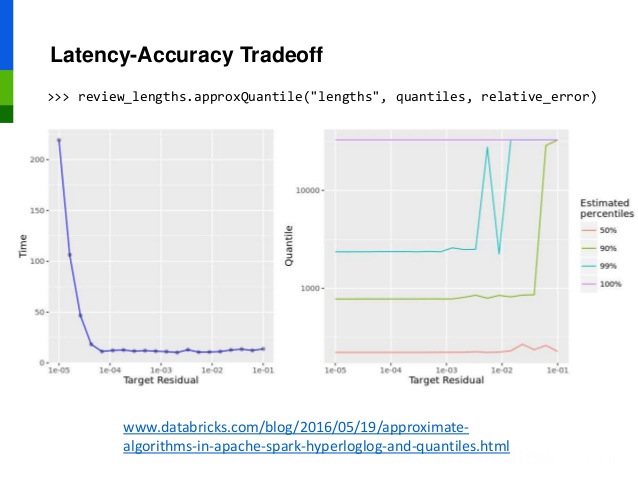
Let’s start thinking about what this tradeoff means for a big data processing system. We start simple by building just a batch system for the Zestimate (and this is what we actually did). It reads directly from a master dataset, which contains all of the data so far. This batch layer, as it’s called, will virtually freeze the data at the time the job begins running computations. The problem, though, is that once the batch layer finishes computing estimates, the data is already out-of-date: new changes have come in and were not accounted for. Lambda Architecture tries to solve this gap. We shouldn’t expect our batch layer to be up-to-date and instead expect it to be accurate. We can instead rely on a speed layer that will compensate for this lack of timeliness.
In this way, at any given moment, we have two different views of the Zestimate: one view from the batch layer that is accurate but not so timely and one view from the speed layer that is less accurate but timely. Reconciling these two views, we can serve our users a Zestimate that is both accurate and timely.
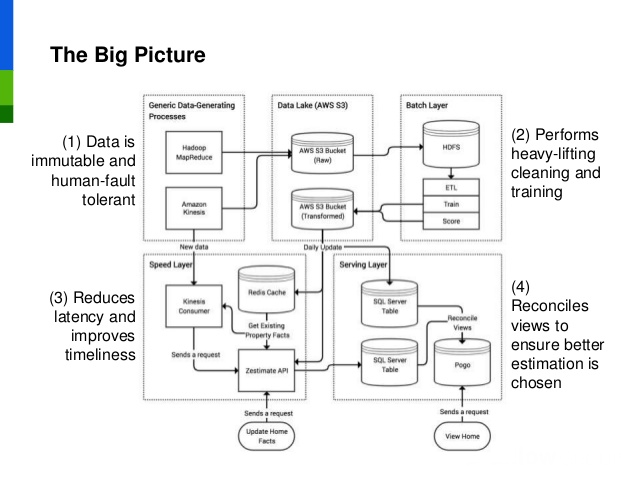
Zestimate Lambda Architecture
I want to explore a couple of the layers of the Lambda Architecture and illustrate how we implement each layer for the Zestimate. So far, most of the investments in the new Zestimate pipeline apply to the data, batch, and speed layers. We still rely on the serving layer that our product teams and database administrators originally set up, and as such, I won’t focus on that.
Master Dataset
To begin, we start with the data. In 2015, most of our data was stored on premises in relational databases, so our first goal was to move this data to the cloud. At Zillow, we use AWS S3 to house our master dataset, as it is optimized to handle a large, constantly growing set of data. In our case, we designate a bucket specifically for raw data. In this design, we do not want to actually modify or update the raw data, so we set permissions on the bucket itself to prevent deletes and updates. After all, data, especially your raw, master set, should be treated as immutable.
Batch Layer
The batch layer is comprised of three stages: ETL, training, and scoring. The ETL stage is responsible for interfacing with the master dataset and transforming it to arrive at cleaner, standardized training and scoring datasets that are consumable by our Zestimate models. We especially invest enormous energy into ensuring our data is clean. As we know, garbage in, garbage out, and this concept holds true for the Zestimate algorithm. One example we always talk about is the case of fat-finger errors. You can imagine that typing 500 square feet instead of 5000 square feet could drastically change how we perceive that home’s value.
This cleaning process can be very expensive computationally. As a result, this is one area where a speed layer would need to be more nimble, as it won’t be able to look at historical data to make inferences about the quality of new data.
After the ETL stage, we begin training models. Training, in our cases, requires large amounts of memory to support caching of training sets for various models. We train models on various geographies, making tradeoffs between data skew and volume of data available. Scoring is then done in parallel, using data partitioned in uniform chunks.
At this point, we have a view created (the Zestimates for about 100M homes in the nation) as well as trained models for the speed layer. But, by this time, some of the facts that went into our model training and scoring could be out of date.
Speed Layer
The number one source of Zestimate error is the facts that flow into it, like number of bedrooms and bathrooms, square footage, etc. To combat this, we provide homeowners with a means for proactively making adjustments to their home facts and images. To do so, they can update a home fact and immediately see a change in their Zestimate. Homeowners can also upload listing images which the Zestimate may use as an input. Beyond that, we want to recalculate our estimates when homes are listed on the market, because in these cases an off-the-market home is updated with all of the latest facts so that it is represented accurately on the market. We rely on our speed layer to tackle these objectives.
In Lambda Architecture, we want our speed layer to read from the same master dataset that our batch layer does. In our case, we have a Kinesis consumer that directly connects to a Kinesis stream. The Kinesis consumer shares cleaning modules with the batch layer, so code reuse is maximized. We accept that the speed layer is not meant to be perfect because our batch layer will correct its mistakes, eventually. As such, we make tradeoffs in the speed layer when choosing which cleaning functions to rely on, balancing the data quality benefit with the latency cost. In addition, to obtain further latency savings, we currently do not use incremental training and re-use the trained models from the batch layer.
Presentation
This post was adapted from a presentation I delivered at the Seattle Data/Analytics/Machine Learning meetup. View the full presentation below. A video will be uploaded as soon as it’s available.