Zkafka by Zillow: Go Library for Simplifying Kafka Consumption

Zkafka is a go module written by Zillow and used internally by about 100 services. The library aims to be a valuable and straightforward building block for Apache Kafka consumption. It ships with a complete feature set and introduces higher-level primitives on top of bare metal Kafka consumers. Some of the notable features include:
- Work ahead processing
- Scalability beyond physical Kafka partitions
- Configurable dead lettering
- Composable retry pipelines
The above list introduces much jargon with little context. However, reviewing the “why” behind this project is helpful before fully detailing the feature set.
Why It Was Built
In the past five years, Kafka use at Zillow has become more common. The internal Kafka Cluster has more than 1,500 Kafka Topics currently provisioned. As Kafka's use expanded, teams began to author bespoke consumption solutions. Teams whose language of choice was Java had a rich set of Java frameworks built up in the Kafka Ecosystem. A common choice for these teams was Flink, which is a framework for stateful message processing. Zillow codebase is a polyglot web of microservices, and for teams not using Java, their choices were fewer and further between. The most popular languages for application development were Go, Python, and JS. For these tech stacks, bespoke Kafka consumer solutions built with direct use of HighLevel consumers began to become commonplace. This led to a proliferation of solutions, each with its own set of challenges and limitations:
- Poor Performance: Naive interpretations of scaling strategies documented online poorly utilize the underlying compute infrastructure.
- Narrowly Designed Solutions: Bespoke solutions often narrowly focus on the specific use case, overlooking features that are not immediately required. This approach limits their broader applicability. Consistently ignored features included:
- Telemetry (metrics/ distributed traces)
- Graceful and performant teardown
- Strong guarantees about at-least-once semantics
- Dead lettering solutions
- Retry pipeline solutions
Uber documents a similar problem space and its solution in its Kafka Consumer Proxy post. Consumer Proxy’s solution, as detailed in Uber’s post, primarily focuses on improving performance and simplifying consumption semantics. It achieves this by introducing Consumer Proxy, which liaises between would-be consumers and Kafka. The abstraction layer introduces a seam by which semantic simplifications and performance gains can be attained. The shortcomings can categorically be summarized as issues with performance and usability. The following sections will detail those issues, some of which were similarly observed and noted in the Uber post. PerformanceThe performance issues in this section aren’t limitations of Kafka as a technology. However, there are limitations incurred by typical consumer pattern implementations against Kafka. Partition ScalabilityFungible replicas make up a service deployment. In the Kafka world, each replica becomes a member of the consumer group (a processor). For the sake of this example, say that count is 2. Kafka consumer group semantics will roughly evenly split the topic’s partitions amongst the replicas. To continue with the example, assume there are four partitions:Processor Count = 2
Partition Count = 4A curious reader can arrange this setup in the Kafka Topic VisualizationTool.The typical recommendation is to increase throughput simply by increasing the consumer count. However, this strategy has an upper limit. That’s because a single partition can be assigned to, at most, one consumer group member simultaneously. Unfortunately, this caps the number of replicas that may do meaningful work.Additionally, a replica processing a single message at a time doesn’t efficiently use the underlying compute resources. A workload with an IO-bound code path will idly waste its compute allocation and have no opportunity to schedule meaningful work. Kubernetes can combat this by allocating portions of virtual CPUs and minuscule memory. However, a Kubernetes replica (in Zillow’s case, an executing OS process) is comparatively heavyweight. Consider the following example.Assume a replica has a minimum memory footprint of 40MiB; thus, two replicas would be 80 MiB, and so on. Alternatively, a single goroutine has a minimum size of 2 KB (1000 orders of magnitude smaller). Figure 1 shows that though both scaling strategies are linear, the constants of replica-only scaling are much higher. Utilizing concurrency within a replica better amortizes the overhead of running a Go process within a replica. Note: The back envelope math is liberal in its assumption that the second goroutine's size is vanishingly small and non-growing. In reality, its memory footprint would increase. The inference that a goroutine is lighter weight, comparatively to a Go process, remains valid (See Why is goroutine being called a “lightweight” thread?)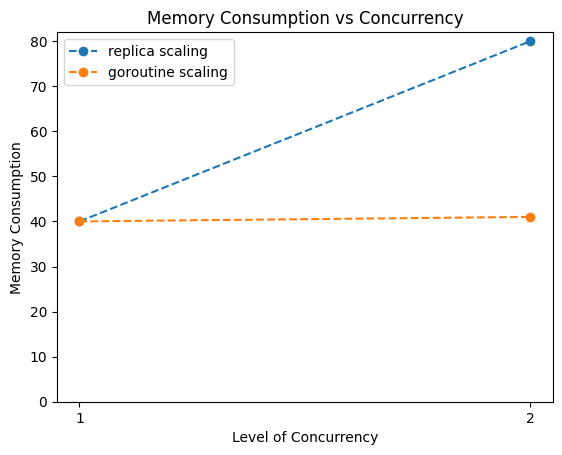 Figure 1: Memory consumption increases in the face of increased concurrency by way of replica and goroutine scalingHead of line blockingImagine you're at your local Publix (or any grocery store) and there are two checkout lines. The lines are balanced initially, with four patronsin each. Unfortunately, for line 1, the first patron insists on paying by check, and they're struggling to find their pen. Suffice it to say line 2 is efficiently processed and is now empty, but line 1 remains stubbornly motionless. This is head of line blocking.The metaphor is somewhat strained, but roughly, this arrangement can be mapped to the following Kafka Topic/Consumer Group arrangement:
Figure 1: Memory consumption increases in the face of increased concurrency by way of replica and goroutine scalingHead of line blockingImagine you're at your local Publix (or any grocery store) and there are two checkout lines. The lines are balanced initially, with four patronsin each. Unfortunately, for line 1, the first patron insists on paying by check, and they're struggling to find their pen. Suffice it to say line 2 is efficiently processed and is now empty, but line 1 remains stubbornly motionless. This is head of line blocking.The metaphor is somewhat strained, but roughly, this arrangement can be mapped to the following Kafka Topic/Consumer Group arrangement: - A) The two grocery store lines refer to a Kafka Topic with two partitions.
- B) The two cashiers are the two processors.
- C) The patrons are messages to be processed.
- D) The obstinate patron insisting on paying by check is a poison-pill message representing a processing duration outlier.
- Consumer groups
- Rebalancing events
- Kafka brokers
- Topics
- Partitions
- Offsets
- Commits
- etc. The above list is incomplete but demonstrates comparative complexity, especially compared to other technologies like AWS’s SQS. The complexity enables a single piece of infrastructure to serve many use cases. Still, it forces developers to reason about details far from the business rules they implement.Consider the case where a dev wants to use Kafka for a greedy consumer pattern. The greedy consumer pattern implies queue semantics, a task a Kafka topic is well suited for. However, the developer must now reason about Kafka consumer semantics.
- What should the consumer group id be?
- Auto commit is on by default in my library; should I use it?
- What actions should my code take as consumer replicas go on and offline? If the previous question has various answers, what outcomes can be expected based on those responses?
A typical, but conservative, pattern for kafka consumers wary of data loss is to process a single message, commit the message, and then proceed to the following message. This pattern is simple and allows for guaranteed at-least-once-processing. Publix has decided to use this strategy in the contrived example. However, as the example demonstrates, the cashier of line 2 finishes and then becomes ineffectual (compute underutilization), and the patrons after patron 1 in line 1 are grumpy because of the delay (poor poison pill isolation).UsabilityDifficult SemanticsKafka comes with a steep learning curve. The primitives introduced by Kafka include:
Those questions are shown without answers to illustrate some of the considerations/tradeoffs developers must consider when interacting with Kafka.Dead LetteringDead lettering is a convenient and powerful technique for asynchronous message processing. A bare Kafka cluster doesn’t support dead lettering as a first-class citizen. Service implementers must provision the topic and adopt the pattern of writing to the topic in the presence of message processing failure. Though conceptually simple, the one-off code for dead letter delivery raises the barrier to entry just enough that, in practice, many systems at Zillow went without.Retry PipelinesRetry pipelines extend the concept of dead lettering, and similar to dead lettering, there is no out-of-the-box primitive that enables the idea. The pattern is to introduce a tiered retry pipeline where delays between progressive retries are significant (typically many orders of magnitude larger than the processing duration).
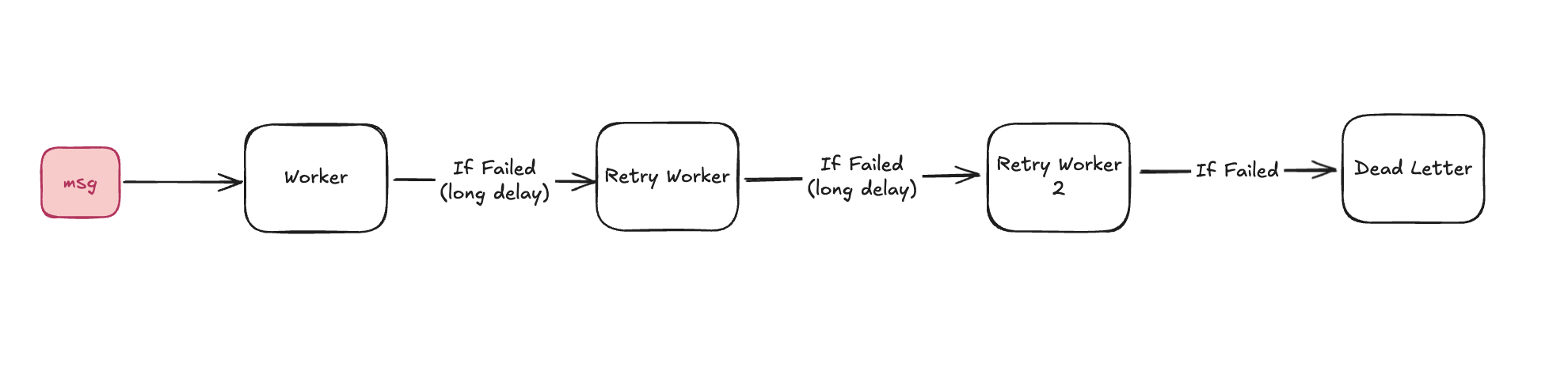 Figure 2: Retry Pipeline demonstrating contingency execution (on delay) in the face of failure
Figure 2: Retry Pipeline demonstrating contingency execution (on delay) in the face of failure- Conceptually, a retry pipeline takes the form shown in Figure 2. A replica processes a message. If processing fails, it's processed again (after some considerable delay). The idea here is that some transient errors (like Database failover from primary to a reader) have a longer duration than typical inline retry delay can mask. After N failures (3 in the above diagram), the failed message persists in a dead letter mechanism (a queue, topic, or database), and an operator can make decisions about recourse.
The strategy can help mitigate operator interventions required to evaluate and execute a course of action for a dead-lettered message.
What Was Built
Zkafka was developed to address these issues and provide a unified, high-performance, easy-to-use solution for Kafka consumption. Zkafka is a Kafka library that addresses all the above problems with dead simple semantics. Kafka itself is complex, but zkafka aims to address the issues above transparently, leaving the code author responsible for writing only the function executed per read message. All the details about polling for messages, efficiently using the underlying compute, extending the Kafka ordering semantics, safely shutting down, and handling rebalances caused by failures/consumer member additions/ revocations are handled. Zkafka taking on this complexity allows the developer to be principally focused on the code directly relevant to the task.
Uber's post details a service implementation that aims to address many of the same issues. Zillow pursued the more straightforward library solution, as opposed to distributed service, for the following reasons:
- Designing a service represents a considerable upfront and continued cost (in terms of maintenance). Centralized services must ensure the isolation of workloads, scalability, etc. This work statement was many orders of magnitude greater than the library solution (which defers many of these same concerns to service implementors).
- Proof of correctness is more straightforward with a library.
- The failure scenarios in a distributed system are more complex to reason about; introducing another component in that collection of services complicates the failure scenarios that must be considered.
- The service implementation has an additional persistence layer, mimicking Kafka consumption semantics but with the added complexity of negative commits (commits for dead-lettered messages), inflight messages, and committed messages, which is by no means trivial to implement.
- The indirection introduces additional service hops. As a centralized service, performance is paramount, and the development team would have to cope with the additional constraint of optimizing for performance at every corner.
Alternatively, the library is divorced from many of these complexities. It can address the issues without complex persistence requirements, instead acting only on the local state, increasing simplicity and benefiting testability.
ZKafka is a library with many great features to be further detailed in the upcoming sections. It aims to efficiently use underlying compute resources by introducing safe concurrency beyond Kafka’s physical partitions (without weakening ordering guarantees). It achieves this by implementing work ahead processing and virtual partitions. Moreover, it aims to achieve a higher-level feature set than bare metal Kafka can with Configurable Dead Lettering and Composable Retry Pipelines.
Work Ahead Processing
A message read from a Kafka topic has an offset and partition, both integers. A consuming service may commit a message after processing concludes. “Committing message” means saving the offset with the Kafka cluster. The Kafka cluster tracks committed offsets for every partition per consumer group.
The last commit is the starting point when the consumer is assigned a set of partitions. This assignment happens when a consumer joins or a member consumer is evicted. Typical scenarios where this occurs include:
- During deployments - replicas are stood up and torn down.
- In case of replica failure - Kubernetes will detect the failure and add a replica back, forcing a Kafka consumer group to rebalance
- During workload shuffling - Kubernetes manages workloads and can move them intermittently.
A simple commit strategy would be to commit after each message is processed. However, the following example will show that this poses a risk of data loss.
Consider the case where a topic has one partition and two messages are processed concurrently. Figure 3 shows a timelapse of this strategy progressing from t=0 -> t=4.
t=0) Processing of msg0 and msg1 begins
t=1) Processing of msg1 completed and is committed** advancing the offset just beyond msg1.
t=2) Processing of msg2 begins
t=3) Processing of msg0 is completed and is committed**. This commit is ineffectual (lower offset commit).
t=4) Processing of msg2 is completed and msg2 is committed**
The commit at t=1 represents a data loss opportunity. If before the completion of msg0 processing after t=1 but before t=2, the replica was torn down, msg0 would never be reread. When the partition gets reassigned to another replica, it will start reading at msg2 (since the commit acts as a high watermark used to start where work left off). Starting at mg2 constitutes data loss.
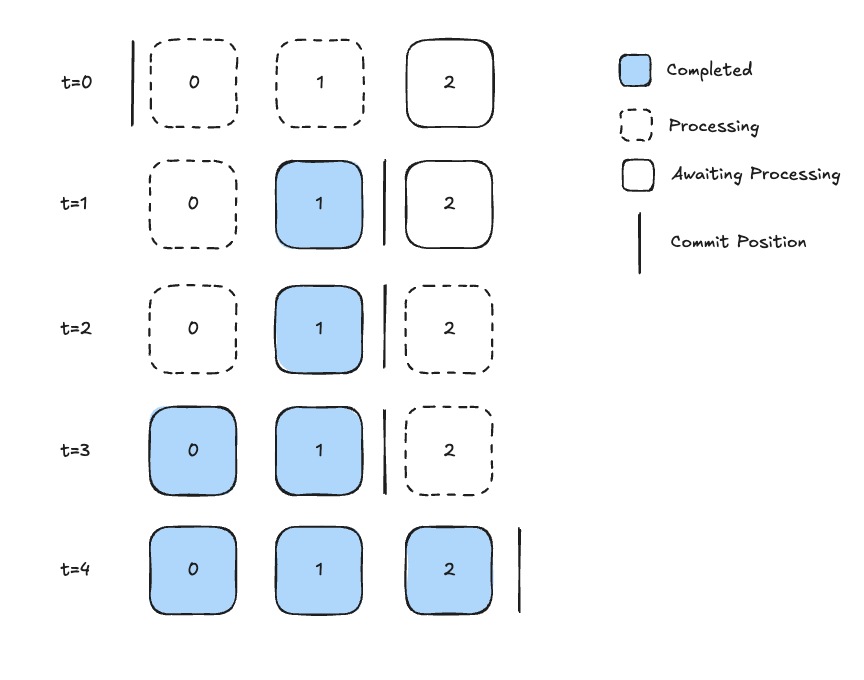 Figure 3: A timelapse of concurrent processing of a single partition. Initially, the commit is just before msg0
Figure 3: A timelapse of concurrent processing of a single partition. Initially, the commit is just before msg0
Zkafka handles this scenario by keeping track of inflight work and marking messages as completed when processing concludes. Zkafka executes commits only when all previous messages have been marked as completed. Figure 4 shows this concept.
t=0) Processing of msg0 and msg1 begins
t=1) Processing of msg1 is finished and msg1 is marked as completed
t=2) Processing of msg2 begins
t=3) Processing of msg0 is finished and msg0 is marked as completed. A commit** is executed, advancing the offset to just beyond msg1
t=4) Processing of msg2 if finished and msg2 is marked as completed, and a commit** is executed.
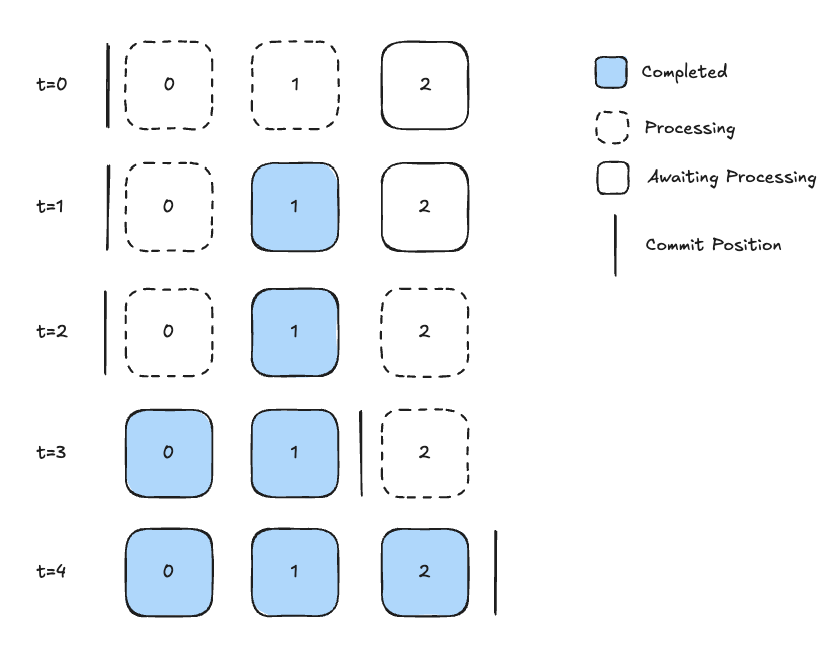 Figure 4: A timelapse of processing a single partition. Initially, the commit is just before msg0
Figure 4: A timelapse of processing a single partition. Initially, the commit is just before msg0
**A commit, as described, is more accurately described as a logical commit. It doesn’t incur a network call. Instead, a local store is updated, and a background process communicates with the broker at set intervals and rebalance events. The strategy is detailed in zkafka's readme.
Virtual Partitions
Virtual partitions are a mechanism that allows for concurrent processes, without dismantling the ordering guarantees of Kafka partition. Virtual Partitions are most easily explained by looking at a natural progression for introducing concurrency.
Single Replica Single Processor
Kafka has the concept of consumer groups. It’s the basic primitive for horizontal scaling processing. Topics are defined a priori, with N partitions. At Zillow, we deploy our workloads to a Kubernetes cluster and leverage Kubernetes Deployments to control the number of replicas via configuration.
The example below shows a replica processing messages from a single topic with two partitions. Kafka can maintain its ordering guarantees (per partition ordering) at the sacrifice of throughput.
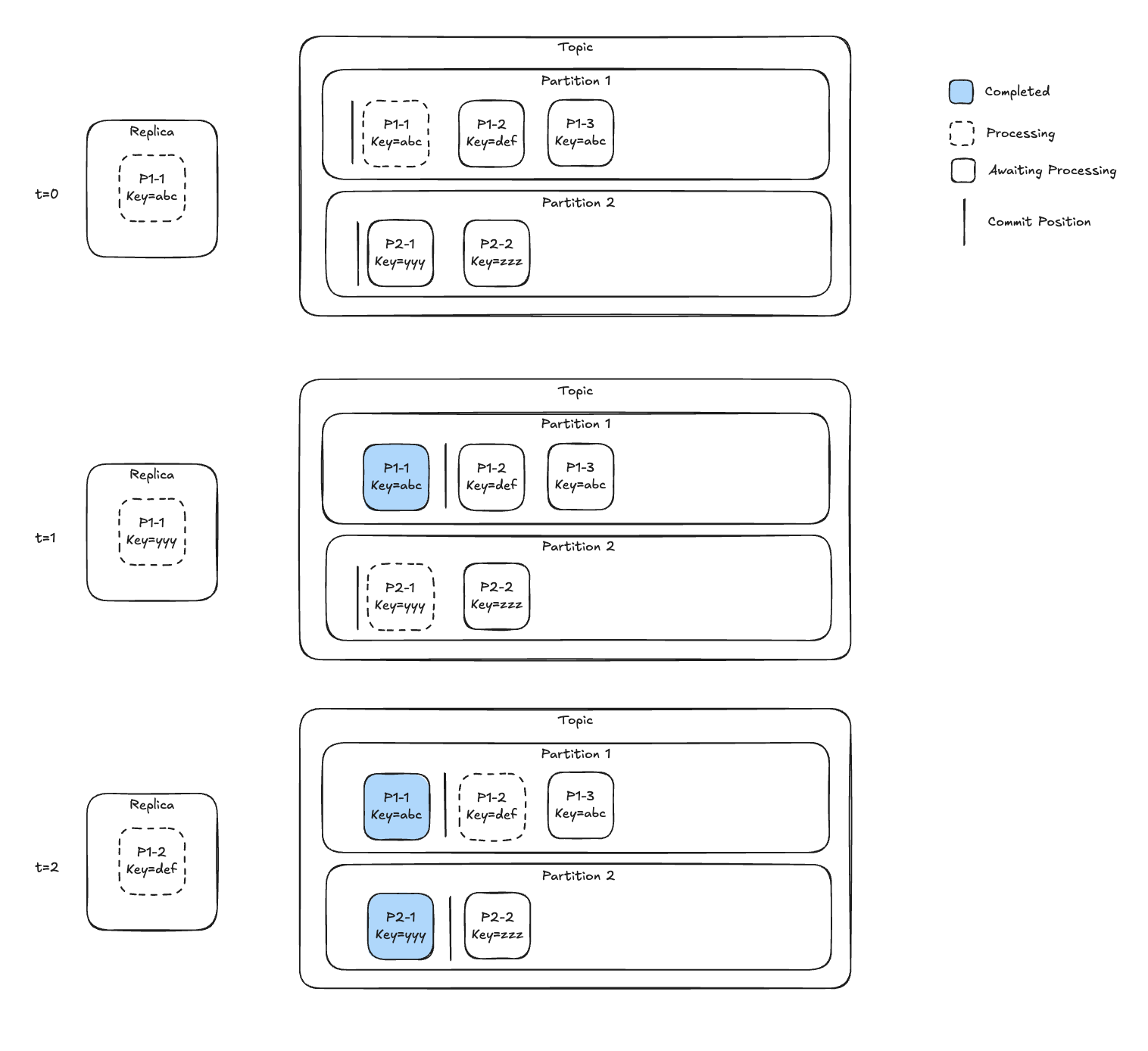 Figure 5: A single replica with a single processor processing messages from a topic with two partitions. A video rendering of the same process is available on YouTube (single message processor).
Figure 5: A single replica with a single processor processing messages from a topic with two partitions. A video rendering of the same process is available on YouTube (single message processor).
Multiple Replicas Single Processor
The easiest way to scale and increase throughput is to use Kafka consumer group semantics in conjunction with Kubernetes deployment replica sets. This example increases the replica count to 2.
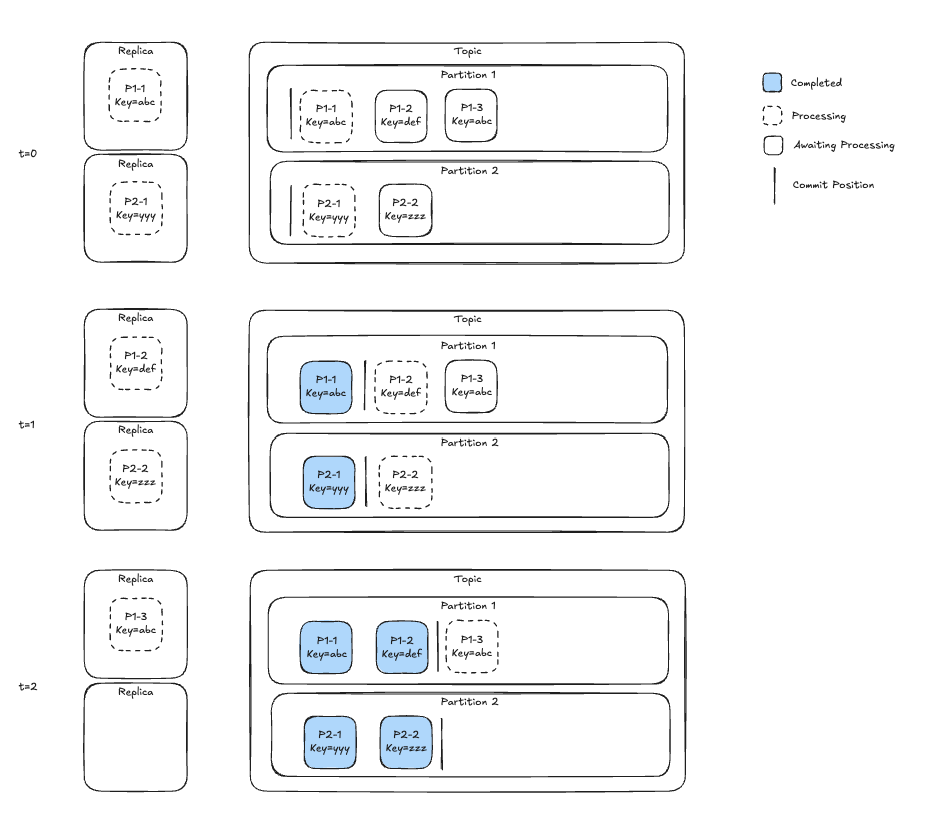 Figure 6: Two replicas with a single processor processing messages from a topic with two partitions. A video rendering of this diagram is available on YouTube (multiple replicas, single message).
Figure 6: Two replicas with a single processor processing messages from a topic with two partitions. A video rendering of this diagram is available on YouTube (multiple replicas, single message).
Throughput has increased. However, the replica could be better utilizing its underlying compute resources. In IO-bound workloads, the CPU sits idle for large spans and has no opportunity to schedule other messages on the CPU concurrently. Would it be possible to introduce concurrency within a replica?
Naive Concurrency Within a Replica
In Go, concurrency can come from a goroutine pool.
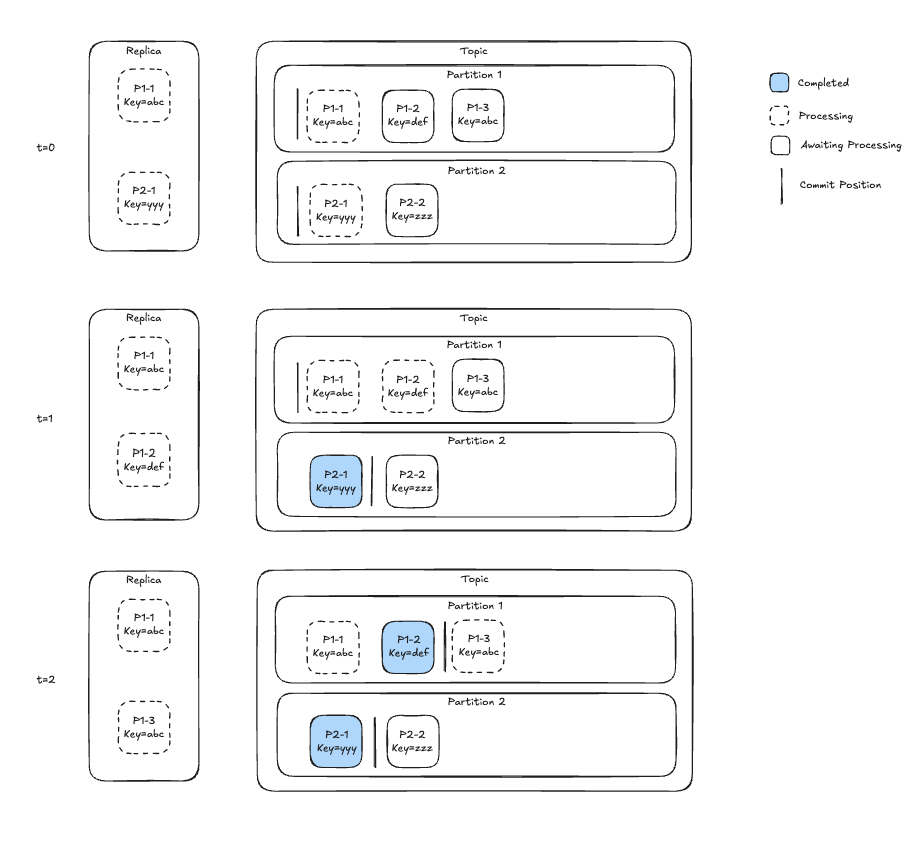 Figure 7: one replica with two processors processing messages from a topic with two partitions. Processor selection is based on availability only. A video rendering of this diagram is available on YouTube (single replica multi-processor round robin).
Figure 7: one replica with two processors processing messages from a topic with two partitions. Processor selection is based on availability only. A video rendering of this diagram is available on YouTube (single replica multi-processor round robin).
Figure 7 shows a replica processing a topic as a time series. The series of events is as follows:
- time=0 - a replica begins processing two messages. Partition 1 Message 1 (P1-1) is a poison pill and takes exceedingly long.
- time=1 - the replica has finished P2-1 and committed. The replica reads the next message (P1-2) and assigns it to the unoccupied processor
- time=2 - the replica has finished message P1-2 and naively committed (processing continues on P1-1)
This uncoordinated concurrency gives up on utilizing Kafka’s per-partition ordering, as there’s no guarantee that P1-2 will be processed after P1-1. This would be unfortunate because Kafka’s semantics offer a valuable seam for workload isolation in the previous iterations. This begs the question, is there a way to have our cake and eat it too?
ZKafka’s Concurrency
What zkafka does is introduce the goroutine pool with a goroutine in the middle, acting as a router. The router selects a gouroutine from the processor pool using a hash mod N strategy. The selection process is similar to that of the Kafka producer partition selector. The algorithm has the following signature (pseudocode) where the response is an integer index of an assignable processor goroutine.

A description of the timelapse is shown in Figure 8 below.
- time=0 - a replica begins processing two messages (P1-1, P2-1, P1-2). The router, not shown here, selects a processor for each message. The selection algorithm guarantees that messages with the same key will end up on this same processor. None of the first three read messages have the same key (even the two messages from the same partition, P1-1 and P1-2, have different keys), and so they may all end up, as they do in this example, on separate processors (though it's not guaranteed).
- time=1 - the processor has finished P2-1 and committed. The router reads the next messages. The router assigns P1-3 to the top processor (it has the same key=abc as p1-1, and this processor selection was inevitable). It is placed in a queue and will not begin until P1-1 is completed or times out.
- time=2 - the processor has finished messages P1-1 and P2-2 and commits. Though this example doesn’t illustrate it, the introduction of virtual partitions does introduce the possibility of order work for partition, but it is not a key. See Work Ahead Processing (above) for details on how out-of-order commits can be managed safely.
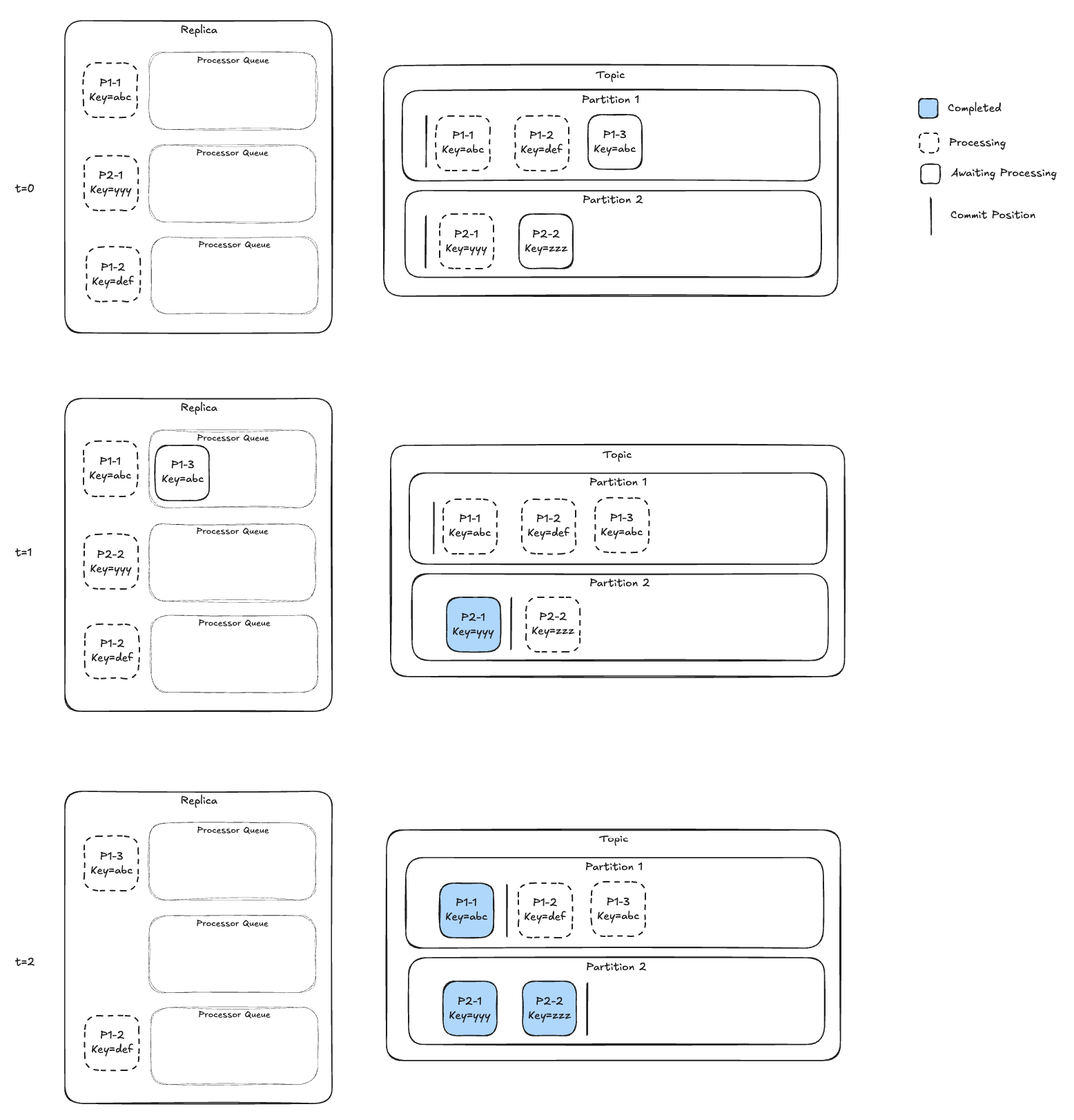 Figure 8: one replica with two processors processing messages from a topic with two partitions. Processor selection is based on the message key. A video rendering of this diagram is available on YouTube (single replica, multi-processor with virtual partitions)
Figure 8: one replica with two processors processing messages from a topic with two partitions. Processor selection is based on the message key. A video rendering of this diagram is available on YouTube (single replica, multi-processor with virtual partitions)
Configurable Dead Letter
Processing a message can fail for several reasons, some of which are:
- A service code bug
- A transient error in a dependency
- A semi-permanent bug in a dependency
- etc.
What should be done when any of the above occurs? At Zillow, many services are built with built-in idempotency (see AWS's safe retries with idempotent APIs for a detailed discussion), which allows for safe retries. This strategy addresses (2), though it doesn’t eliminate it. Regardless, (1) and (3) and the catch-all (4) still exist. So, ultimately, failures will occur that automated retries can’t paper away. A typical strategy in async message processing is for some mechanism to dead letter messages that failed to execute successfully. Subsequently, a human assesses and determines remediation steps.
Dead lettering is a baked-in functionality for other queuing technologies, namely SQS. Though conceptually simple, it does add a fair amount of boilerplate within the Kafka world. One of zkafka’s primary motivations was simplifying consumption semantics for developers. The bias to simplify extends to failure scenarios. Zkafka introduces a configuration-based solution for dead letters. In this way, adding dead lettering to a worker is as simple as providing the topic name of the dead letter to target in case of a failed message.
The following code snippet shows the additional lines required by such a configuration.

Under the hood, zkafka exposes rich lifecycle/callback functionality through its APIs. The dead letter configuration is syntactic sugar for registering a special onDone callback, which is guaranteed to be processed after the message processing conclusion (either message processing success, failure, or timeout), and is codified to write to the configured Dead Letter Topic in case of failure or timeout.
Retry Pipelines
A typical pattern is configuring a service to retry processing a message after an extended delay. SQS can achieve inter-process retry using the concept of Visibility Timeout. In practice, the extended delay can be orders of magnitude larger than the typical processing duration of a message. Large retry delays are a valuable property for addressing extended transient errors.
A developer could achieve a processing delay by adding a delay within the processor callback (the code they principally authored). However, an implementation like this presents a couple of disadvantages:
- The retry delay is invisible to zkafka’s scheduling mechanism. It’d be impossible to differentiate between the processing delay from the deliberate pause and processing delays incurred while acting on the message. Combining these two phases eliminates zkafka’s optionality to harmlessly abort unstarted processing during teardown.
- To further this point, zkafka places upper bounds on the processing duration allotted to a single message (by default, it's one minute). The upper bound duration allows for guarantees about eventually making continued progress on messages in the topic, and avoids an indefinite blocking scenario. The issue is that retries of this nature are typically very large. The closest equivalent, semantically, is SQS, which Zillow enterprise libraries default to a 30-second pause before inter-process retry. A retry of this duration would exhaust the default 1 minute after two failures.
To address both these issues, zkafka has a concept of processor delay. Processor Delay was designed as a configurable option in a Kafka worker to enable a stage in a retry pipeline to execute on delay.
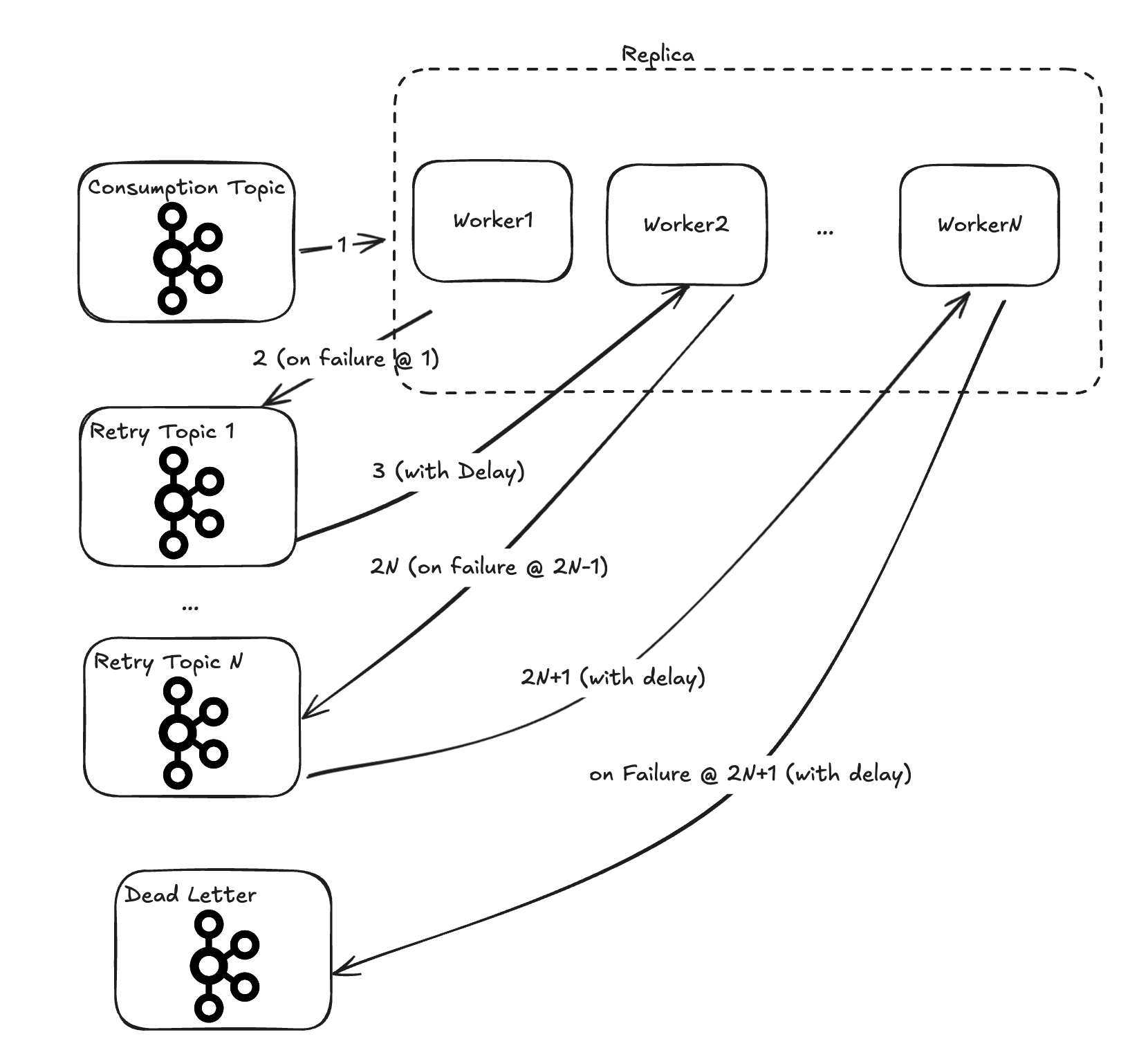 Figure 9: Retry Pipeline shows multiple topics daisy chained together by logically identical workers
Figure 9: Retry Pipeline shows multiple topics daisy chained together by logically identical workers
Tactically, a system designer achieves the design objectives of Figure 9 by deploying N workers with the same processor callback (differing only in their source topic, dead letter topic, and processing delay).

How to Get Access
Zkafka is open-source and available on GitHub under an Apache 2.0 license. The package is well documented and has plenty of runnable examples, and the zkafka readme gives details about running an example (including the simple setup phase).
For questions about the library or working at Zillow, contact stewartb@zillowgroup.com. I look forward to hearing from you!
References
Related Articles




Sign up for Zillow news updates
Subscribe to receive daily emails for the latest Zillow news and announcements, product updates and more.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23111116;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M.67,84.17v-9.38L39.19,20.75v-1.12H1.34V4.67h62.64v9.38l-37.85,54.04v1.12h38.97v14.96H.67Z'/%3e%3cpath%20class='st0'%20d='M75.04,9.36c0-5.58,4.13-9.71,9.94-9.71s9.94,4.13,9.94,9.71-4.13,9.71-9.94,9.71-9.94-4.02-9.94-9.71ZM76.71,84.17V27h16.53v57.17h-16.53Z'/%3e%3cpath%20class='st0'%20d='M106.3,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M135.33,84.17V1.32h16.53v82.85h-16.53Z'/%3e%3cpath%20class='st0'%20d='M161.79,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM208.58,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M246.32,84.17l-17.2-57.17h16.86l11.61,40.64h1.12l10.16-40.64h16.53l10.94,40.98h1.12l11.39-40.98h16.41l-17.31,57.17h-21.55l-8.71-37.85h-1.12l-8.6,37.85h-21.66Z'/%3e%3cpath%20class='st0'%20d='M362.44,84.17V4.67h56.94v15.86h-38.3v17.53h33.5v14.51h-33.5v31.6h-18.65Z'/%3e%3cpath%20class='st0'%20d='M428.76,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.53Z'/%3e%3cpath%20class='st0'%20d='M471.64,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM518.43,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.18,6.7-15.18,16.19,6.25,16.3,15.18,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M545.11,84.17V27h16.52v8.04h1.12c4.24-6.48,9.71-9.71,16.64-9.71,12.95,0,21.55,10.05,21.55,23.78v35.06h-16.52v-32.72c0-7.03-4.02-11.95-10.72-11.95s-12.06,5.25-12.06,12.51v32.16h-16.52Z'/%3e%3cpath%20class='st0'%20d='M617.13,65.74v-26.69h-8.04v-12.06h8.49l3.24-18.09h12.95l-.11,18.09h13.06v12.06h-13.06v26.02c0,4.8,2.9,8.04,7.59,8.04,1.56,0,4.02-.33,5.92-.78v11.84c-3.24,1.12-7.93,1.79-11.17,1.79-11.5,0-18.87-8.15-18.87-20.21Z'/%3e%3cpath%20class='st0'%20d='M686.58,84.17V4.67h34.95c19.43,0,31.93,10.27,31.82,26.69,0,16.3-12.62,26.8-31.93,26.8h-16.52v26.02h-18.31ZM704.89,44.08h15.07c9.16,0,14.85-5.02,14.85-12.73s-5.81-12.62-14.85-12.62h-15.07v25.35Z'/%3e%3cpath%20class='st0'%20d='M757.71,55.58c0-18.42,12.62-30.37,31.71-30.37s31.71,11.95,31.71,30.37-12.73,30.37-31.71,30.37-31.71-11.95-31.71-30.37ZM804.49,55.58c0-9.49-6.25-16.19-15.07-16.19s-15.19,6.7-15.19,16.19,6.25,16.3,15.19,16.3,15.07-6.81,15.07-16.3Z'/%3e%3cpath%20class='st0'%20d='M831.17,84.17V27h16.3v7.82h1.23c2.46-5.36,8.04-8.93,14.07-8.93,2.34,0,4.69.56,6.48,1.45v14.85c-3.24-1.45-7.03-2.12-9.38-2.12-7.26,0-12.17,6.03-12.17,14.85v29.25h-16.52Z'/%3e%3cpath%20class='st0'%20d='M874.16,55.58c0-18.2,12.62-30.37,31.04-30.37,15.52,0,27.36,8.71,29.25,22.22l-15.41,2.01c-1.45-6.25-7.26-10.61-13.62-10.61-8.37,0-14.74,6.92-14.74,16.75s6.25,16.75,14.63,16.75c6.59,0,12.17-4.35,13.73-10.5l15.52,1.9c-2.12,13.51-14.07,22.22-29.37,22.22-18.2,0-31.04-12.28-31.04-30.37Z'/%3e%3cpath%20class='st0'%20d='M944.73,84.17V1.32h16.52v33.39h1.12c4.35-6.25,9.71-9.49,16.64-9.49,12.95,0,21.66,10.05,21.66,23.67v35.28h-16.52v-32.83c0-7.03-4.13-11.95-10.83-11.95s-12.06,5.25-12.06,12.62v32.16h-16.52Z'/%3e%3c/svg%3e)
