We had a great time talking about recommendations at Zillow during the recent Data/Analytics/MachineLearning meetup.
We’ve included the full video and our biggest takeaways below:
Recommendation Systems are an easy way to make your product more personalized without having to reinvent the wheel.
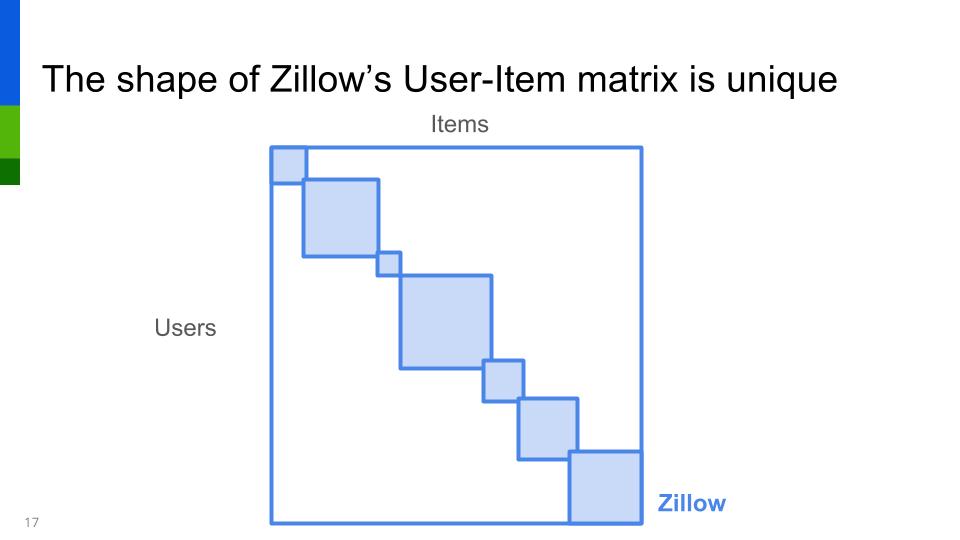
Zillow has some unique data features: a closer ratio of homes (items) to users and unique regional differences (vs a traditional stores globally popular items vs niche products).
There are two families of models: collaborative filtering (only need user<->item interaction) and content based modeling (involves defining and mapping user & item information to machine learning variables). Collaborative filtering is an easy approach to start with via the below open source and one click services.

A new technique called interleaving replaces the need to A/B new models separately and provides statistically significant results on comparative model performance without having to pay people to manually rate results.

We save an offline dataset for testing new models and make the pipeline to validate those online via interleaving or an A/B test very easy. If that test is successful, the model is rolled out to 100%.

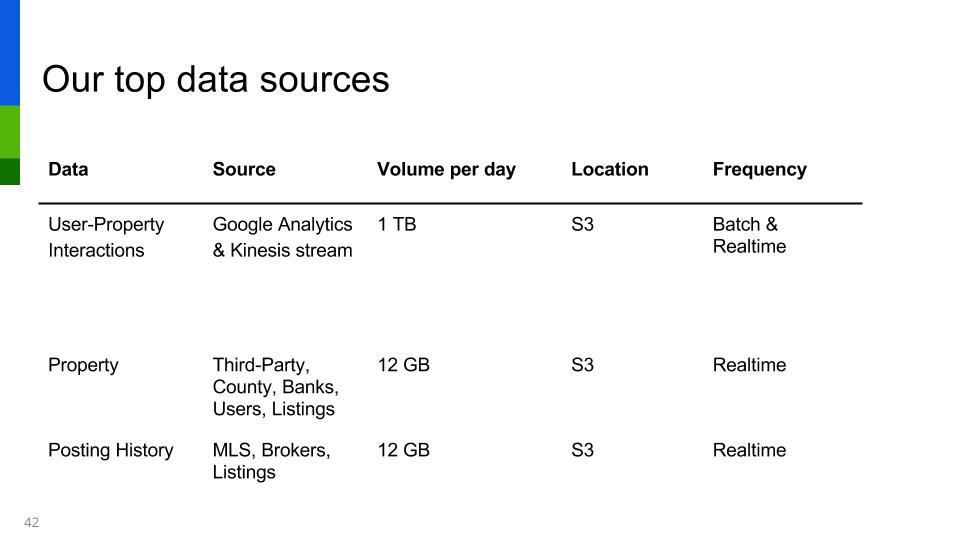
At Zillow, we get roughly 1 TB of relevant user & home data a day to process.
We use all modern infrastructure on AWS:
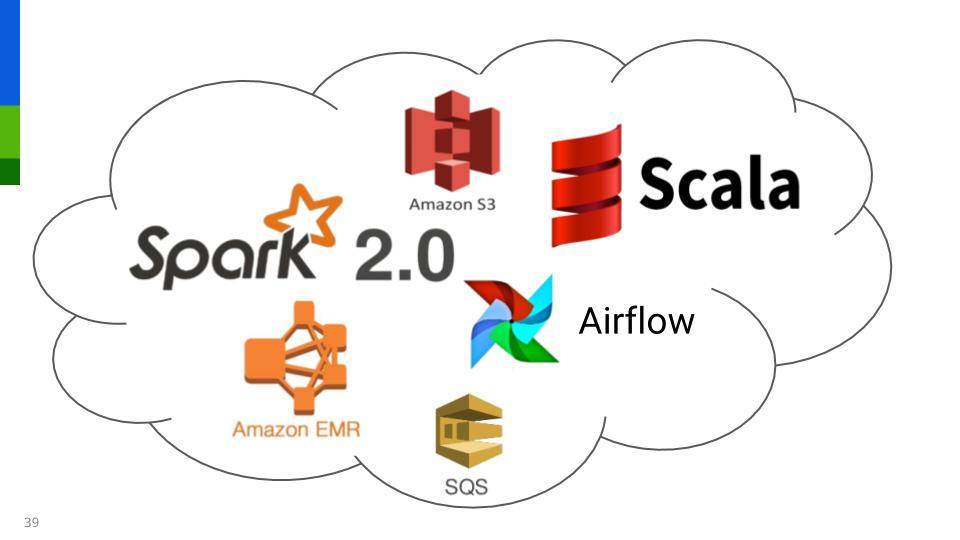
We write our Spark code in Scala as it’s a first class citizen, use the new Datasets (Spark 2.0) when possible, and RDD’s everywhere else.



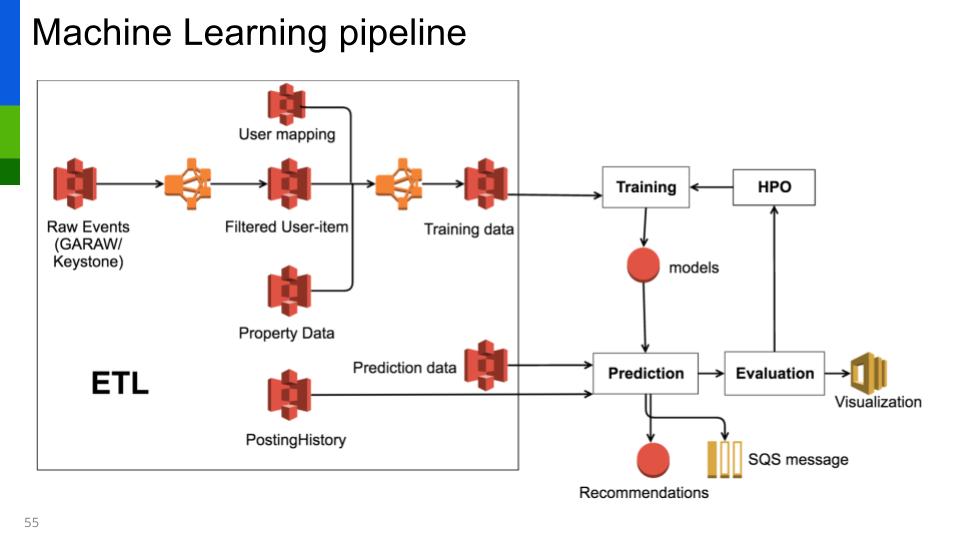
A summary of a standard model pipeline.
Standard, most important evaluation metrics for new models.

That’s it for our intro to recommendation systems! We have a bunch of other cool projects in the works below. If you’re a Data Scientist, Machine Learning Engineer, Data Engineer or PM – send us a note! nicholass@zillow & shrutik@zillow


{kind=link}